diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..6e5bdd9
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,162 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+cover/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+# For a library or package, you might want to ignore these files since the code is
+# intended to run in multiple environments; otherwise, check them in:
+# .python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# poetry
+# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
+#poetry.lock
+
+# pdm
+# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
+#pdm.lock
+# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
+# in version control.
+# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
+.pdm.toml
+.pdm-python
+.pdm-build/
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# pytype static type analyzer
+.pytype/
+
+# Cython debug symbols
+cython_debug/
+
+# Editors
+.idea/
+.vscode
+
+# logs
+logs
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..9ad8f6d
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,23 @@
+BSD 3-Clause License
+Copyright (c) 2016-2023 HangZhou YuShu TECHNOLOGY CO.,LTD. ("Unitree Robotics")
+All rights reserved.
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+1. Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+2. Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+3. Neither the name of the copyright holder nor the names of its
+ contributors may be used to endorse or promote products derived from
+ this software without specific prior written permission.
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/README.md b/README.md
index e69de29..9f9ee0b 100644
--- a/README.md
+++ b/README.md
@@ -0,0 +1,200 @@
+
+
Unitree RL GYM
+
+ 🌎English | 🇨🇳中文
+
+
+ This is a repository for reinforcement learning implementation based on Unitree robots, supporting Unitree Go2, H1, H1_2, and G1.
+
+
+
+
+|
Isaac Gym
|
Mujoco
|
Physical
|
+|--- | --- | --- |
+| [
](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [
](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [
](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) |
+
+
/_/model_.pt`
+
+---
+
+### 2. Play
+
+To visualize the training results in Gym, run the following command:
+
+```bash
+python legged_gym/scripts/play.py --task=xxx
+```
+
+**Description**:
+
+- Play’s parameters are the same as Train’s.
+- By default, it loads the latest model from the experiment folder’s last run.
+- You can specify other models using `load_run` and `checkpoint`.
+
+#### 💾 Export Network
+
+Play exports the Actor network, saving it in `logs/{experiment_name}/exported/policies`:
+- Standard networks (MLP) are exported as `policy_1.pt`.
+- RNN networks are exported as `policy_lstm_1.pt`.
+
+### Play Results
+
+| Go2 | G1 | H1 | H1_2 |
+|--- | --- | --- | --- |
+| [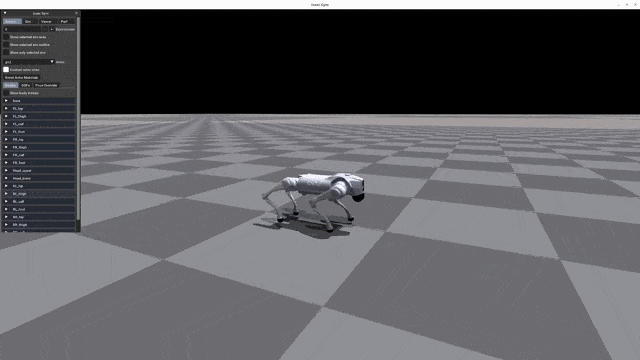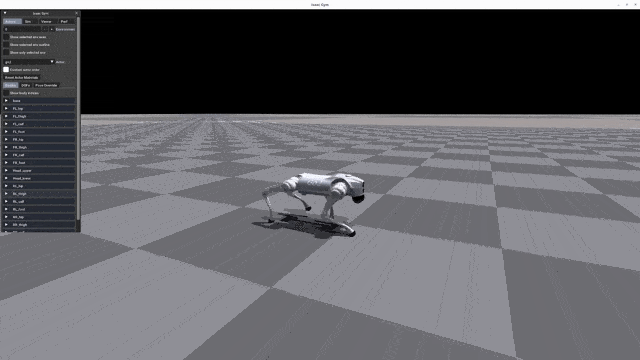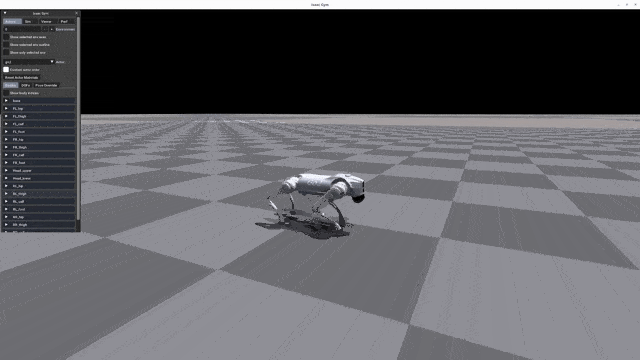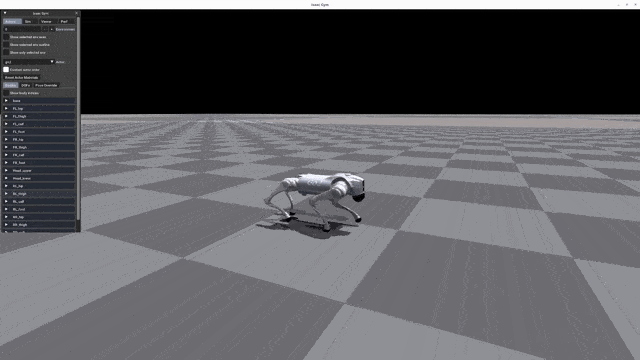](https://oss-global-cdn.unitree.com/static/d2e8da875473457c8d5d69c3de58b24d.mp4) | [](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [](https://oss-global-cdn.unitree.com/static/522128f4640c4f348296d2761a33bf98.mp4) |[](https://oss-global-cdn.unitree.com/static/15fa46984f2343cb83342fd39f5ab7b2.mp4)|
+
+---
+
+### 3. Sim2Sim (Mujoco)
+
+Run Sim2Sim in the Mujoco simulator:
+
+```bash
+python deploy/deploy_mujoco/deploy_mujoco.py {config_name}
+```
+
+#### Parameter Description
+- `config_name`: Configuration file; default search path is `deploy/deploy_mujoco/configs/`.
+
+#### Example: Running G1
+
+```bash
+python deploy/deploy_mujoco/deploy_mujoco.py g1.yaml
+```
+
+#### ➡️ Replace Network Model
+
+The default model is located at `deploy/pre_train/{robot}/motion.pt`; custom-trained models are saved in `logs/g1/exported/policies/policy_lstm_1.pt`. Update the `policy_path` in the YAML configuration file accordingly.
+
+#### Simulation Results
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [](https://oss-global-cdn.unitree.com/static/8934052becd84d08bc8c18c95849cf32.mp4) | [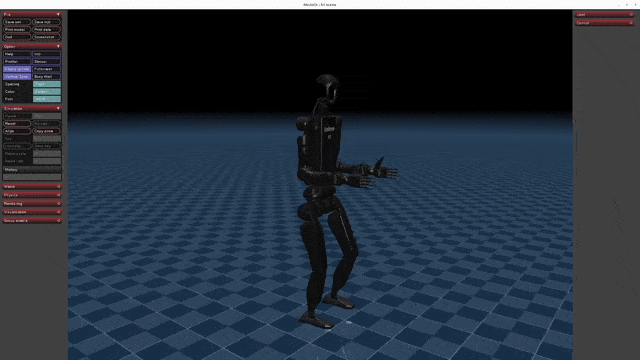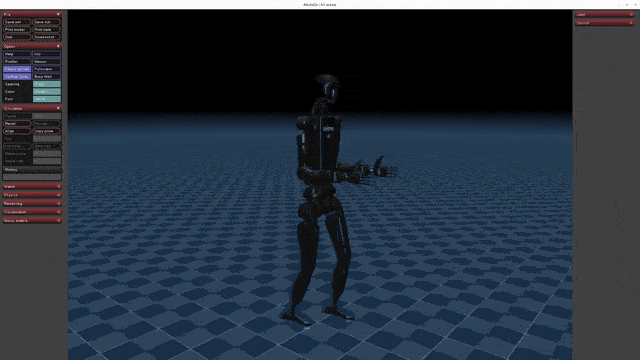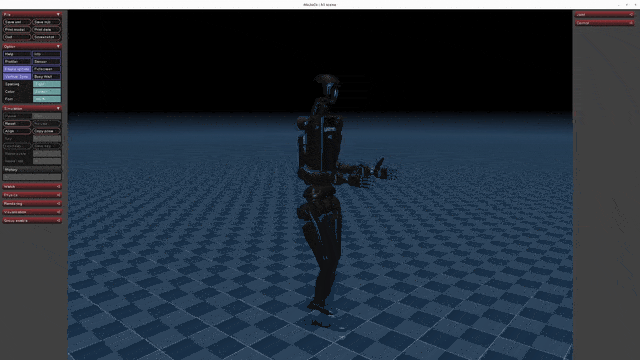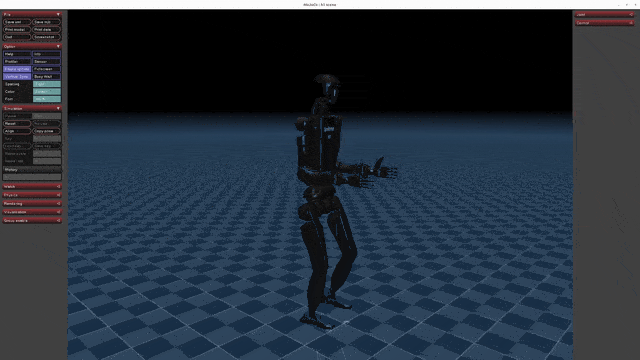](https://oss-global-cdn.unitree.com/static/ee7ee85bd6d249989a905c55c7a9d305.mp4) |
+
+
+---
+
+### 4. Sim2Real (Physical Deployment)
+
+Before deploying to the physical robot, ensure it’s in debug mode. Detailed steps can be found in the [Physical Deployment Guide](deploy/deploy_real/README.md):
+
+```bash
+python deploy/deploy_real/deploy_real.py {net_interface} {config_name}
+```
+
+
+#### Parameter Description
+- `net_interface`: Network card name connected to the robot, e.g., `enp3s0`.
+- `config_name`: Configuration file located in `deploy/deploy_real/configs/`, e.g., `g1.yaml`, `h1.yaml`, `h1_2.yaml`.
+
+#### Deployment Results
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) | [](https://oss-global-cdn.unitree.com/static/ea0084038d384e3eaa73b961f33e6210.mp4) | [](https://oss-global-cdn.unitree.com/static/12d041a7906e489fae79d55b091a63dd.mp4) |
+
+---
+
+#### Deploy with C++
+There is also an example of deploying the G1 pre-trained model in C++. the C++ code is located in the following directory.
+
+```
+deploy/deploy_real/cpp_g1
+```
+
+First, navigate to the directory above.
+
+```base
+cd deploy/deploy_real/cpp_g1
+```
+
+The C++ implementation depends on the LibTorch library, download the LibTorch
+
+```bash
+wget https://download.pytorch.org/libtorch/cpu/libtorch-cxx11-abi-shared-with-deps-2.7.1%2Bcpu.zip
+unzip libtorch-cxx11-abi-shared-with-deps-2.7.1+cpu.zip
+```
+
+To build the project, executable the following steps
+
+```bash
+mkdir build
+cd build
+cmake ..
+make -j4
+```
+
+After successful compilation, executate the program with:
+
+```base
+./g1_deploy_run {net_interface}
+```
+
+Replace `{net_interface}` with your actual network interface name (e.g., eth0, wlan0).
+
+## 🎉 Acknowledgments
+
+This repository is built upon the support and contributions of the following open-source projects. Special thanks to:
+
+- [legged\_gym](https://github.com/leggedrobotics/legged_gym): The foundation for training and running codes.
+- [rsl\_rl](https://github.com/leggedrobotics/rsl_rl.git): Reinforcement learning algorithm implementation.
+- [mujoco](https://github.com/google-deepmind/mujoco.git): Providing powerful simulation functionalities.
+- [unitree\_sdk2\_python](https://github.com/unitreerobotics/unitree_sdk2_python.git): Hardware communication interface for physical deployment.
+
+---
+
+## 🔖 License
+
+This project is licensed under the [BSD 3-Clause License](./LICENSE):
+1. The original copyright notice must be retained.
+2. The project name or organization name may not be used for promotion.
+3. Any modifications must be disclosed.
+
+For details, please read the full [LICENSE file](./LICENSE).
+
diff --git a/README_zh.md b/README_zh.md
new file mode 100644
index 0000000..86d49de
--- /dev/null
+++ b/README_zh.md
@@ -0,0 +1,163 @@
+
+
+
+ 🎮🚪 这是一个基于 Unitree 机器人实现强化学习的示例仓库,支持 Unitree Go2、H1、H1_2和 G1。 🚪🎮
+
+
+
+
+|
Isaac Gym
|
Mujoco
|
Physical
|
+|--- | --- | --- |
+| [
](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [
](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [
](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) |
+
+
/_/model_.pt`
+
+---
+
+### 2. Play
+
+如果想要在 Gym 中查看训练效果,可以运行以下命令:
+
+```bash
+python legged_gym/scripts/play.py --task=xxx
+```
+
+**说明**:
+
+- Play 启动参数与 Train 相同。
+- 默认加载实验文件夹上次运行的最后一个模型。
+- 可通过 `load_run` 和 `checkpoint` 指定其他模型。
+
+#### 💾 导出网络
+
+Play 会导出 Actor 网络,保存于 `logs/{experiment_name}/exported/policies` 中:
+- 普通网络(MLP)导出为 `policy_1.pt`
+- RNN 网络,导出为 `policy_lstm_1.pt`
+
+### Play 效果
+
+| Go2 | G1 | H1 | H1_2 |
+|--- | --- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/d2e8da875473457c8d5d69c3de58b24d.mp4) | [](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [](https://oss-global-cdn.unitree.com/static/522128f4640c4f348296d2761a33bf98.mp4) |[](https://oss-global-cdn.unitree.com/static/15fa46984f2343cb83342fd39f5ab7b2.mp4)|
+
+---
+
+### 3. Sim2Sim (Mujoco)
+
+支持在 Mujoco 仿真器中运行 Sim2Sim:
+
+```bash
+python deploy/deploy_mujoco/deploy_mujoco.py {config_name}
+```
+
+#### 参数说明
+- `config_name`: 配置文件,默认查询路径为 `deploy/deploy_mujoco/configs/`
+
+#### 示例:运行 G1
+
+```bash
+python deploy/deploy_mujoco/deploy_mujoco.py g1.yaml
+```
+
+#### ➡️ 替换网络模型
+
+默认模型位于 `deploy/pre_train/{robot}/motion.pt`;自己训练模型保存于`logs/g1/exported/policies/policy_lstm_1.pt`,只需替换 yaml 配置文件中 `policy_path`。
+
+#### 运行效果
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [](https://oss-global-cdn.unitree.com/static/8934052becd84d08bc8c18c95849cf32.mp4) | [](https://oss-global-cdn.unitree.com/static/ee7ee85bd6d249989a905c55c7a9d305.mp4) |
+
+
+---
+
+### 4. Sim2Real (实物部署)
+
+实现实物部署前,确保机器人进入调试模式。详细步骤请参考 [实物部署指南](deploy/deploy_real/README.zh.md):
+
+```bash
+python deploy/deploy_real/deploy_real.py {net_interface} {config_name}
+```
+
+#### 参数说明
+- `net_interface`: 连接机器人网卡名称,如 `enp3s0`
+- `config_name`: 配置文件,存在于 `deploy/deploy_real/configs/`,如 `g1.yaml`,`h1.yaml`,`h1_2.yaml`
+
+#### 运行效果
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) | [](https://oss-global-cdn.unitree.com/static/ea0084038d384e3eaa73b961f33e6210.mp4) | [](https://oss-global-cdn.unitree.com/static/12d041a7906e489fae79d55b091a63dd.mp4) |
+
+---
+
+## 🎉 致谢
+
+本仓库开发离不开以下开源项目的支持与贡献,特此感谢:
+
+- [legged\_gym](https://github.com/leggedrobotics/legged_gym): 构建训练与运行代码的基础。
+- [rsl\_rl](https://github.com/leggedrobotics/rsl_rl.git): 强化学习算法实现。
+- [mujoco](https://github.com/google-deepmind/mujoco.git): 提供强大仿真功能。
+- [unitree\_sdk2\_python](https://github.com/unitreerobotics/unitree_sdk2_python.git): 实物部署硬件通信接口。
+
+
+---
+
+## 🔖 许可证
+
+本项目根据 [BSD 3-Clause License](./LICENSE) 授权:
+1. 必须保留原始版权声明。
+2. 禁止以项目名或组织名作举。
+3. 声明所有修改内容。
+
+详情请阅读完整 [LICENSE 文件](./LICENSE)。
+
diff --git a/deploy/deploy_mujoco/configs/g1.yaml b/deploy/deploy_mujoco/configs/g1.yaml
new file mode 100644
index 0000000..db18fdf
--- /dev/null
+++ b/deploy/deploy_mujoco/configs/g1.yaml
@@ -0,0 +1,26 @@
+#
+policy_path: "{LEGGED_GYM_ROOT_DIR}/deploy/pre_train/g1/motion.pt"
+xml_path: "{LEGGED_GYM_ROOT_DIR}/resources/robots/g1_description/scene.xml"
+
+# Total simulation time
+simulation_duration: 60.0
+# Simulation time step
+simulation_dt: 0.002
+# Controller update frequency (meets the requirement of simulation_dt * controll_decimation=0.02; 50Hz)
+control_decimation: 10
+
+kps: [100, 100, 100, 150, 40, 40, 100, 100, 100, 150, 40, 40]
+kds: [2, 2, 2, 4, 2, 2, 2, 2, 2, 4, 2, 2]
+
+default_angles: [-0.1, 0.0, 0.0, 0.3, -0.2, 0.0,
+ -0.1, 0.0, 0.0, 0.3, -0.2, 0.0]
+
+ang_vel_scale: 0.25
+dof_pos_scale: 1.0
+dof_vel_scale: 0.05
+action_scale: 0.25
+cmd_scale: [2.0, 2.0, 0.25]
+num_actions: 12
+num_obs: 47
+
+cmd_init: [0.5, 0, 0]
\ No newline at end of file
diff --git a/deploy/deploy_mujoco/configs/h1.yaml b/deploy/deploy_mujoco/configs/h1.yaml
new file mode 100644
index 0000000..5e76056
--- /dev/null
+++ b/deploy/deploy_mujoco/configs/h1.yaml
@@ -0,0 +1,26 @@
+#
+policy_path: "{LEGGED_GYM_ROOT_DIR}/deploy/pre_train/h1/motion.pt"
+xml_path: "{LEGGED_GYM_ROOT_DIR}/resources/robots/h1/scene.xml"
+
+# Total simulation time
+simulation_duration: 60.0
+# Simulation time step
+simulation_dt: 0.002
+# Controller update frequency (meets the requirement of simulation_dt * controll_decimation=0.02; 50Hz)
+control_decimation: 10
+
+kps: [150, 150, 150, 200, 40, 150, 150, 150, 200, 40]
+kds: [2, 2, 2, 4, 2, 2, 2, 2, 4, 2]
+
+default_angles: [0, 0.0, -0.1, 0.3, -0.2,
+ 0, 0.0, -0.1, 0.3, -0.2]
+
+ang_vel_scale: 0.25
+dof_pos_scale: 1.0
+dof_vel_scale: 0.05
+action_scale: 0.25
+cmd_scale: [2.0, 2.0, 0.25]
+num_actions: 10
+num_obs: 41
+
+cmd_init: [0.5, 0, 0]
\ No newline at end of file
diff --git a/deploy/deploy_mujoco/configs/h1_2.yaml b/deploy/deploy_mujoco/configs/h1_2.yaml
new file mode 100644
index 0000000..b27a315
--- /dev/null
+++ b/deploy/deploy_mujoco/configs/h1_2.yaml
@@ -0,0 +1,26 @@
+#
+policy_path: "{LEGGED_GYM_ROOT_DIR}/deploy/pre_train/h1_2/motion.pt"
+xml_path: "{LEGGED_GYM_ROOT_DIR}/resources/robots/h1_2/scene.xml"
+
+# Total simulation time
+simulation_duration: 60.0
+# Simulation time step
+simulation_dt: 0.002
+# Controller update frequency (meets the requirement of simulation_dt * controll_decimation=0.02; 50Hz)
+control_decimation: 10
+
+kps: [200, 200, 200, 300, 40, 40, 200, 200, 200, 300, 40, 40]
+kds: [2.5, 2.5, 2.5, 4, 2, 2, 2.5, 2.5, 2.5, 4, 2, 2]
+
+default_angles: [0, -0.16, 0.0, 0.36, -0.2, 0.0,
+ 0, -0.16, 0.0, 0.36, -0.2, 0.0]
+
+ang_vel_scale: 0.25
+dof_pos_scale: 1.0
+dof_vel_scale: 0.05
+action_scale: 0.25
+cmd_scale: [2.0, 2.0, 0.25]
+num_actions: 12
+num_obs: 47
+
+cmd_init: [0.5, 0, 0]
\ No newline at end of file
diff --git a/deploy/deploy_mujoco/configs/sg1.yaml b/deploy/deploy_mujoco/configs/sg1.yaml
new file mode 100644
index 0000000..e4d8946
--- /dev/null
+++ b/deploy/deploy_mujoco/configs/sg1.yaml
@@ -0,0 +1,26 @@
+#
+policy_path: "{LEGGED_GYM_ROOT_DIR}/deploy/pre_train/smallgray/policy_lstm_1.pt"
+xml_path: "{LEGGED_GYM_ROOT_DIR}/resources/robots/smallgray/scene1.xml"
+
+# Total simulation time
+simulation_duration: 60.0
+# Simulation time step
+simulation_dt: 0.002
+# Controller update frequency (meets the requirement of simulation_dt * controll_decimation=0.02; 50Hz)
+control_decimation: 10
+
+kps: [100, 100, 100, 150, 40, 40, 100, 100, 100, 150, 40, 40]
+kds: [2, 2, 2, 4, 2, 2, 2, 2, 2, 4, 2, 2]
+
+default_angles: [-0.1, 0.0, 0.0, 0.3, -0.2, 0.0,
+ -0.1, 0.0, 0.0, 0.3, -0.2, 0.0]
+
+ang_vel_scale: 0.25
+dof_pos_scale: 1.0
+dof_vel_scale: 0.05
+action_scale: 0.25
+cmd_scale: [2.0, 2.0, 0.25]
+num_actions: 12
+num_obs: 47
+
+cmd_init: [0.5, 0, 0]
\ No newline at end of file
diff --git a/deploy/deploy_mujoco/deploy_mujoco.py b/deploy/deploy_mujoco/deploy_mujoco.py
new file mode 100644
index 0000000..94bfb41
--- /dev/null
+++ b/deploy/deploy_mujoco/deploy_mujoco.py
@@ -0,0 +1,130 @@
+import time
+
+import mujoco.viewer
+import mujoco
+import numpy as np
+from legged_gym import LEGGED_GYM_ROOT_DIR
+import torch
+import yaml
+
+
+def get_gravity_orientation(quaternion):
+ qw = quaternion[0]
+ qx = quaternion[1]
+ qy = quaternion[2]
+ qz = quaternion[3]
+
+ gravity_orientation = np.zeros(3)
+
+ gravity_orientation[0] = 2 * (-qz * qx + qw * qy)
+ gravity_orientation[1] = -2 * (qz * qy + qw * qx)
+ gravity_orientation[2] = 1 - 2 * (qw * qw + qz * qz)
+
+ return gravity_orientation
+
+
+def pd_control(target_q, q, kp, target_dq, dq, kd):
+ """Calculates torques from position commands"""
+ return (target_q - q) * kp + (target_dq - dq) * kd
+
+
+if __name__ == "__main__":
+ # get config file name from command line
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("config_file", type=str, help="config file name in the config folder")
+ args = parser.parse_args()
+ config_file = args.config_file
+ with open(f"{LEGGED_GYM_ROOT_DIR}/deploy/deploy_mujoco/configs/{config_file}", "r") as f:
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ policy_path = config["policy_path"].replace("{LEGGED_GYM_ROOT_DIR}", LEGGED_GYM_ROOT_DIR)
+ xml_path = config["xml_path"].replace("{LEGGED_GYM_ROOT_DIR}", LEGGED_GYM_ROOT_DIR)
+
+ simulation_duration = config["simulation_duration"]
+ simulation_dt = config["simulation_dt"]
+ control_decimation = config["control_decimation"]
+
+ kps = np.array(config["kps"], dtype=np.float32)
+ kds = np.array(config["kds"], dtype=np.float32)
+
+ default_angles = np.array(config["default_angles"], dtype=np.float32)
+
+ ang_vel_scale = config["ang_vel_scale"]
+ dof_pos_scale = config["dof_pos_scale"]
+ dof_vel_scale = config["dof_vel_scale"]
+ action_scale = config["action_scale"]
+ cmd_scale = np.array(config["cmd_scale"], dtype=np.float32)
+
+ num_actions = config["num_actions"]
+ num_obs = config["num_obs"]
+
+ cmd = np.array(config["cmd_init"], dtype=np.float32)
+
+ # define context variables
+ action = np.zeros(num_actions, dtype=np.float32)
+ target_dof_pos = default_angles.copy()
+ obs = np.zeros(num_obs, dtype=np.float32)
+
+ counter = 0
+
+ # Load robot model
+ m = mujoco.MjModel.from_xml_path(xml_path)
+ d = mujoco.MjData(m)
+ m.opt.timestep = simulation_dt
+
+ # load policy
+ policy = torch.jit.load(policy_path)
+
+ with mujoco.viewer.launch_passive(m, d) as viewer:
+ # Close the viewer automatically after simulation_duration wall-seconds.
+ start = time.time()
+ while viewer.is_running() and time.time() - start < simulation_duration:
+ step_start = time.time()
+ tau = pd_control(target_dof_pos, d.qpos[7:], kps, np.zeros_like(kds), d.qvel[6:], kds)
+ d.ctrl[:] = tau
+ # mj_step can be replaced with code that also evaluates
+ # a policy and applies a control signal before stepping the physics.
+ mujoco.mj_step(m, d)
+
+ counter += 1
+ if counter % control_decimation == 0:
+ # Apply control signal here.
+
+ # create observation
+ qj = d.qpos[7:]
+ dqj = d.qvel[6:]
+ quat = d.qpos[3:7]
+ omega = d.qvel[3:6]
+
+ qj = (qj - default_angles) * dof_pos_scale
+ dqj = dqj * dof_vel_scale
+ gravity_orientation = get_gravity_orientation(quat)
+ omega = omega * ang_vel_scale
+
+ period = 0.8
+ count = counter * simulation_dt
+ phase = count % period / period
+ sin_phase = np.sin(2 * np.pi * phase)
+ cos_phase = np.cos(2 * np.pi * phase)
+
+ obs[:3] = omega
+ obs[3:6] = gravity_orientation
+ obs[6:9] = cmd * cmd_scale
+ obs[9 : 9 + num_actions] = qj
+ obs[9 + num_actions : 9 + 2 * num_actions] = dqj
+ obs[9 + 2 * num_actions : 9 + 3 * num_actions] = action
+ obs[9 + 3 * num_actions : 9 + 3 * num_actions + 2] = np.array([sin_phase, cos_phase])
+ obs_tensor = torch.from_numpy(obs).unsqueeze(0)
+ # policy inference
+ action = policy(obs_tensor).detach().numpy().squeeze()
+ # transform action to target_dof_pos
+ target_dof_pos = action * action_scale + default_angles
+
+ # Pick up changes to the physics state, apply perturbations, update options from GUI.
+ viewer.sync()
+
+ # Rudimentary time keeping, will drift relative to wall clock.
+ time_until_next_step = m.opt.timestep - (time.time() - step_start)
+ if time_until_next_step > 0:
+ time.sleep(time_until_next_step)
diff --git a/deploy/deploy_real/README.md b/deploy/deploy_real/README.md
new file mode 100644
index 0000000..2398d58
--- /dev/null
+++ b/deploy/deploy_real/README.md
@@ -0,0 +1,83 @@
+# Deploy on Physical Robot
+
+This code can deploy the trained network on physical robots. Currently supported robots include Unitree G1, H1, H1_2.
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) | [](https://oss-global-cdn.unitree.com/static/ea0084038d384e3eaa73b961f33e6210.mp4) | [](https://oss-global-cdn.unitree.com/static/12d041a7906e489fae79d55b091a63dd.mp4) |
+
+
+## Startup Usage
+
+```bash
+python deploy_real.py {net_interface} {config_name}
+```
+
+- `net_interface`: is the name of the network interface connected to the robot, such as `enp3s0`
+- `config_name`: is the file name of the configuration file. The configuration file will be found under `deploy/deploy_real/configs/`, such as `g1.yaml`, `h1.yaml`, `h1_2.yaml`.
+
+## Startup Process
+
+### 1. Start the robot
+
+Start the robot in the hoisting state and wait for the robot to enter `zero torque mode`
+
+### 2. Enter the debugging mode
+
+Make sure the robot is in `zero torque mode`, press the `L2+R2` key combination of the remote control; the robot will enter the `debugging mode`, and the robot joints are in the damping state in the `debugging mode`.
+
+
+### 3. Connect the robot
+
+Use an Ethernet cable to connect your computer to the network port on the robot. Modify the network configuration as follows
+
+
+
+class AFLock
+{
+ public:
+ AFLock() = default;
+ ~AFLock() = default;
+
+ void Lock()
+ {
+ while (mAFL.test_and_set(std::memory_order_acquire));
+ }
+
+ bool TryLock()
+ {
+ return mAFL.test_and_set(std::memory_order_acquire) ? false : true;
+ }
+
+ void Unlock()
+ {
+ mAFL.clear(std::memory_order_release);
+ }
+
+ private:
+ std::atomic_flag mAFL = ATOMIC_FLAG_INIT;
+};
+
+template
+class ScopedLock
+{
+ public:
+ explicit ScopedLock(L& lock) :
+ mLock(lock)
+ {
+ mLock.Lock();
+ }
+
+ ~ScopedLock()
+ {
+ mLock.Unlock();
+ }
+
+ private:
+ L& mLock;
+};
+#endif
diff --git a/deploy/deploy_real/cpp_g1/CMakeLists.txt b/deploy/deploy_real/cpp_g1/CMakeLists.txt
new file mode 100644
index 0000000..6001efb
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/CMakeLists.txt
@@ -0,0 +1,19 @@
+cmake_minimum_required(VERSION 3.16)
+project(g1_deploy_real)
+
+set(CMAKE_BUILD_TYPE Debug)
+
+include_directories(/usr/local/include/ddscxx)
+include_directories(/usr/local/include/iceoryx/v2.0.2)
+
+set(CMAKE_CXX_STANDARD 17)
+
+set(CMAKE_PREFIX_PATH "${CMAKE_CURRENT_LIST_DIR}/libtorch/share/cmake")
+find_package(Torch REQUIRED)
+include_directories(${TORCH_INCLUDE_DIRS})
+
+aux_source_directory(. SRC_LIST)
+add_executable(${PROJECT_NAME} ${SRC_LIST})
+
+find_package(yaml-cpp REQUIRED)
+target_link_libraries(${PROJECT_NAME} unitree_sdk2 ddsc ddscxx ${TORCH_LIBRARIES} yaml-cpp::yaml-cpp pthread)
diff --git a/deploy/deploy_real/cpp_g1/Controller.cpp b/deploy/deploy_real/cpp_g1/Controller.cpp
new file mode 100644
index 0000000..b1684a0
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/Controller.cpp
@@ -0,0 +1,250 @@
+#include "Controller.h"
+#include
+#include
+#include
+#include "utilities.h"
+
+#define TOPIC_LOWCMD "rt/lowcmd"
+#define TOPIC_LOWSTATE "rt/lowstate"
+
+Controller::Controller(const std::string &net_interface)
+{
+ YAML::Node yaml_node = YAML::LoadFile("../../configs/g1.yaml");
+
+ leg_joint2motor_idx = yaml_node["leg_joint2motor_idx"].as>();
+ kps = yaml_node["kps"].as>();
+ kds = yaml_node["kds"].as>();
+ default_angles = yaml_node["default_angles"].as>();
+ arm_waist_joint2motor_idx = yaml_node["arm_waist_joint2motor_idx"].as>();
+ arm_waist_kps = yaml_node["arm_waist_kps"].as>();
+ arm_waist_kds = yaml_node["arm_waist_kds"].as>();
+ arm_waist_target = yaml_node["arm_waist_target"].as>();
+ ang_vel_scale = yaml_node["ang_vel_scale"].as();
+ dof_pos_scale = yaml_node["dof_pos_scale"].as();
+ dof_vel_scale = yaml_node["dof_vel_scale"].as();
+ action_scale = yaml_node["action_scale"].as();
+ cmd_scale = yaml_node["cmd_scale"].as>();
+ num_actions = yaml_node["num_actions"].as();
+ num_obs = yaml_node["num_obs"].as();
+ max_cmd = yaml_node["max_cmd"].as>();
+
+ obs.setZero(num_obs);
+ act.setZero(num_actions);
+
+ module = torch::jit::load("../../../pre_train/g1/motion.pt");
+
+ unitree::robot::ChannelFactory::Instance()->Init(0, net_interface);
+
+ lowcmd_publisher.reset(new unitree::robot::ChannelPublisher(TOPIC_LOWCMD));
+ lowstate_subscriber.reset(new unitree::robot::ChannelSubscriber(TOPIC_LOWSTATE));
+
+ lowcmd_publisher->InitChannel();
+ lowstate_subscriber->InitChannel(std::bind(&Controller::low_state_message_handler, this, std::placeholders::_1));
+
+ while (!mLowStateBuf.GetDataPtr())
+ {
+ usleep(100000);
+ }
+
+ low_cmd_write_thread_ptr = unitree::common::CreateRecurrentThreadEx("low_cmd_write", UT_CPU_ID_NONE, 2000, &Controller::low_cmd_write_handler, this);
+ std::cout << "Controller init done!\n";
+}
+
+void Controller::zero_torque_state()
+{
+ const std::chrono::milliseconds cycle_time(20);
+ auto next_cycle = std::chrono::steady_clock::now();
+
+ std::cout << "zero_torque_state, press start\n";
+ while (!joy.btn.components.start)
+ {
+ auto low_cmd = std::make_shared();
+
+ for (auto &cmd : low_cmd->motor_cmd())
+ {
+ cmd.q() = 0;
+ cmd.dq() = 0;
+ cmd.kp() = 0;
+ cmd.kd() = 0;
+ cmd.tau() = 0;
+ }
+
+ mLowCmdBuf.SetDataPtr(low_cmd);
+
+ next_cycle += cycle_time;
+ std::this_thread::sleep_until(next_cycle);
+ }
+}
+
+void Controller::move_to_default_pos()
+{
+ std::cout << "move_to_default_pos, press A\n";
+ const std::chrono::milliseconds cycle_time(20);
+ auto next_cycle = std::chrono::steady_clock::now();
+
+ auto low_state = mLowStateBuf.GetDataPtr();
+ std::array jpos;
+ for (int i = 0; i < 35; i++)
+ {
+ jpos[i] = low_state->motor_state()[i].q();
+ }
+
+ int num_steps = 100;
+ int count = 0;
+
+ while (count <= num_steps || !joy.btn.components.A)
+ {
+ auto low_cmd = std::make_shared();
+ float phase = std::clamp(float(count++) / num_steps, 0, 1);
+
+ // leg
+ for (int i = 0; i < 12; i++)
+ {
+ low_cmd->motor_cmd()[i].q() = (1 - phase) * jpos[i] + phase * default_angles[i];
+ low_cmd->motor_cmd()[i].kp() = kps[i];
+ low_cmd->motor_cmd()[i].kd() = kds[i];
+ low_cmd->motor_cmd()[i].tau() = 0.0;
+ low_cmd->motor_cmd()[i].dq() = 0.0;
+ }
+
+ // waist arm
+ for (int i = 12; i < 29; i++)
+ {
+ low_cmd->motor_cmd()[i].q() = (1 - phase) * jpos[i] + phase * arm_waist_target[i - 12];
+ low_cmd->motor_cmd()[i].kp() = arm_waist_kps[i - 12];
+ low_cmd->motor_cmd()[i].kd() = arm_waist_kds[i - 12];
+ low_cmd->motor_cmd()[i].tau() = 0.0;
+ low_cmd->motor_cmd()[i].dq() = 0.0;
+ }
+
+ mLowCmdBuf.SetDataPtr(low_cmd);
+
+ next_cycle += cycle_time;
+ std::this_thread::sleep_until(next_cycle);
+ }
+}
+
+void Controller::run()
+{
+ std::cout << "run controller, press select\n";
+
+ const std::chrono::milliseconds cycle_time(20);
+ auto next_cycle = std::chrono::steady_clock::now();
+
+ float period = .8;
+ float time = 0;
+
+ while (!joy.btn.components.select)
+ {
+ auto low_state = mLowStateBuf.GetDataPtr();
+ // obs
+ Eigen::Matrix3f R = Eigen::Quaternionf(low_state->imu_state().quaternion()[0], low_state->imu_state().quaternion()[1], low_state->imu_state().quaternion()[2], low_state->imu_state().quaternion()[3]).toRotationMatrix();
+
+ for (int i = 0; i < 3; i++)
+ {
+ obs(i) = ang_vel_scale * low_state->imu_state().gyroscope()[i];
+ obs(i + 3) = -R(2, i);
+ }
+
+ if (obs(5) > 0)
+ {
+ break;
+ }
+
+ obs(6) = joy.ly * max_cmd[0] * cmd_scale[0];
+ obs(7) = joy.lx * -1 * max_cmd[1] * cmd_scale[1];
+ obs(8) = joy.rx * -1 * max_cmd[2] * cmd_scale[2];
+
+ for (int i = 0; i < 12; i++)
+ {
+ obs(9 + i) = (low_state->motor_state()[i].q() - default_angles[i]) * dof_pos_scale;
+ obs(21 + i) = low_state->motor_state()[i].dq() * dof_vel_scale;
+ }
+ obs.segment(33, 12) = act;
+
+ float phase = std::fmod(time / period, 1);
+ time += .02;
+ obs(45) = std::sin(2 * M_PI * phase);
+ obs(46) = std::cos(2 * M_PI * phase);
+
+ // policy forward
+ torch::Tensor torch_tensor = torch::from_blob(obs.data(), {1, obs.size()}, torch::kFloat).clone();
+ std::vector inputs;
+ inputs.push_back(torch_tensor);
+ torch::Tensor output_tensor = module.forward(inputs).toTensor();
+ std::memcpy(act.data(), output_tensor.data_ptr(), output_tensor.size(1) * sizeof(float));
+
+ auto low_cmd = std::make_shared();
+ // leg
+ for (int i = 0; i < 12; i++)
+ {
+ low_cmd->motor_cmd()[i].q() = act(i) * action_scale + default_angles[i];
+ low_cmd->motor_cmd()[i].kp() = kps[i];
+ low_cmd->motor_cmd()[i].kd() = kds[i];
+ low_cmd->motor_cmd()[i].dq() = 0;
+ low_cmd->motor_cmd()[i].tau() = 0;
+ }
+
+ // waist arm
+ for (int i = 12; i < 29; i++)
+ {
+ low_cmd->motor_cmd()[i].q() = arm_waist_target[i - 12];
+ low_cmd->motor_cmd()[i].kp() = arm_waist_kps[i - 12];
+ low_cmd->motor_cmd()[i].kd() = arm_waist_kds[i - 12];
+ low_cmd->motor_cmd()[i].dq() = 0;
+ low_cmd->motor_cmd()[i].tau() = 0;
+ }
+
+ mLowCmdBuf.SetDataPtr(low_cmd);
+
+ next_cycle += cycle_time;
+ std::this_thread::sleep_until(next_cycle);
+ }
+}
+
+void Controller::damp()
+{
+ std::cout << "damping\n";
+ const std::chrono::milliseconds cycle_time(20);
+ auto next_cycle = std::chrono::steady_clock::now();
+
+ while (true)
+ {
+ auto low_cmd = std::make_shared();
+ for (auto &cmd : low_cmd->motor_cmd())
+ {
+ cmd.kp() = 0;
+ cmd.kd() = 8;
+ cmd.dq() = 0;
+ cmd.tau() = 0;
+ }
+
+ mLowCmdBuf.SetDataPtr(low_cmd);
+
+ next_cycle += cycle_time;
+ std::this_thread::sleep_until(next_cycle);
+ }
+}
+
+
+void Controller::low_state_message_handler(const void *message)
+{
+ unitree_hg::msg::dds_::LowState_* ptr = (unitree_hg::msg::dds_::LowState_*)message;
+ mLowStateBuf.SetData(*ptr);
+ std::memcpy(&joy, ptr->wireless_remote().data(), ptr->wireless_remote().size() * sizeof(uint8_t));
+}
+
+void Controller::low_cmd_write_handler()
+{
+ if (auto lowCmdPtr = mLowCmdBuf.GetDataPtr())
+ {
+ lowCmdPtr->mode_machine() = mLowStateBuf.GetDataPtr()->mode_machine();
+ lowCmdPtr->mode_pr() = 0;
+ for (auto &cmd : lowCmdPtr->motor_cmd())
+ {
+ cmd.mode() = 1;
+ }
+ lowCmdPtr->crc() = crc32_core((uint32_t*)(lowCmdPtr.get()), (sizeof(unitree_hg::msg::dds_::LowCmd_) >> 2) - 1);
+ lowcmd_publisher->Write(*lowCmdPtr);
+ }
+}
diff --git a/deploy/deploy_real/cpp_g1/Controller.h b/deploy/deploy_real/cpp_g1/Controller.h
new file mode 100644
index 0000000..21c79c7
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/Controller.h
@@ -0,0 +1,66 @@
+#ifndef CONTROLLER_H
+#define CONTROLLER_H
+
+#include
+#include
+#include
+#include
+#include
+
+#include "torch/script.h"
+
+#include
+
+#include "joystick.h"
+#include "DataBuffer.h"
+#include
+
+class Controller
+{
+ public:
+ Controller(const std::string &net_interface);
+ void low_state_message_handler(const void *message);
+ void move_to_default_pos();
+ void run();
+ void damp();
+ void zero_torque_state();
+
+ private:
+ void low_cmd_write_handler();
+
+ unitree::common::ThreadPtr low_cmd_write_thread_ptr;
+
+ DataBuffer mLowCmdBuf;
+ DataBuffer mLowStateBuf;
+
+ unitree::robot::ChannelPublisherPtr lowcmd_publisher;
+ unitree::robot::ChannelSubscriberPtr lowstate_subscriber;
+
+ // joystick
+ xRockerBtnDataStruct joy;
+
+ // yaml config
+ std::vector leg_joint2motor_idx;
+ std::vector kps;
+ std::vector kds;
+ std::vector default_angles;
+ std::vector arm_waist_joint2motor_idx;
+ std::vector arm_waist_kps;
+ std::vector arm_waist_kds;
+ std::vector arm_waist_target;
+ float ang_vel_scale;
+ float dof_pos_scale;
+ float dof_vel_scale;
+ float action_scale;
+ std::vector cmd_scale;
+ float num_actions;
+ float num_obs;
+ std::vector max_cmd;
+
+ Eigen::VectorXf obs;
+ Eigen::VectorXf act;
+
+ torch::jit::script::Module module;
+};
+
+#endif
diff --git a/deploy/deploy_real/cpp_g1/DataBuffer.h b/deploy/deploy_real/cpp_g1/DataBuffer.h
new file mode 100644
index 0000000..3b6a428
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/DataBuffer.h
@@ -0,0 +1,77 @@
+#ifndef DATA_BUFFER_H
+#define DATA_BUFFER_H
+
+#include
+#include "AtomicLock.h"
+
+template
+class DataBuffer
+{
+ public:
+ explicit DataBuffer() = default;
+ ~DataBuffer() = default;
+
+ void SetDataPtr(const std::shared_ptr& dataPtr)
+ {
+ ScopedLock lock(mLock);
+ mDataPtr = dataPtr;
+ }
+
+ std::shared_ptr GetDataPtr(bool clear = false)
+ {
+ ScopedLock lock(mLock);
+ if (clear)
+ {
+ std::shared_ptr dataPtr = mDataPtr;
+ mDataPtr.reset();
+ return dataPtr;
+ }
+ else
+ {
+ return mDataPtr;
+ }
+ }
+
+ void SwapDataPtr(std::shared_ptr& dataPtr)
+ {
+ ScopedLock lock(mLock);
+ mDataPtr.swap(dataPtr);
+ }
+
+ void SetData(const T& data)
+ {
+ ScopedLock lock(mLock);
+ mDataPtr = std::shared_ptr(new T(data));
+ }
+
+ /*
+ * Not recommend because an additional data assignment.
+ */
+ bool GetData(T& data, bool clear = false)
+ {
+ ScopedLock lock(mLock);
+ if (mDataPtr == NULL)
+ {
+ return false;
+ }
+
+ data = *mDataPtr;
+ if (clear)
+ {
+ mDataPtr.reset();
+ }
+
+ return true;
+ }
+
+ void Clear()
+ {
+ ScopedLock lock(mLock);
+ mDataPtr.reset();
+ }
+
+ private:
+ std::shared_ptr mDataPtr;
+ AFLock mLock;
+};
+#endif
diff --git a/deploy/deploy_real/cpp_g1/joystick.h b/deploy/deploy_real/cpp_g1/joystick.h
new file mode 100644
index 0000000..4218efe
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/joystick.h
@@ -0,0 +1,41 @@
+#ifndef JOYSTICK_H
+#define JOYSTICK_H
+
+typedef union
+{
+ struct
+ {
+ uint8_t R1 : 1;
+ uint8_t L1 : 1;
+ uint8_t start : 1;
+ uint8_t select : 1;
+ uint8_t R2 : 1;
+ uint8_t L2 : 1;
+ uint8_t F1 : 1;
+ uint8_t F2 : 1;
+ uint8_t A : 1;
+ uint8_t B : 1;
+ uint8_t X : 1;
+ uint8_t Y : 1;
+ uint8_t up : 1;
+ uint8_t right : 1;
+ uint8_t down : 1;
+ uint8_t left : 1;
+ } components;
+ uint16_t value;
+} xKeySwitchUnion;
+
+typedef struct
+{
+ uint8_t head[2];
+ xKeySwitchUnion btn;
+ float lx;
+ float rx;
+ float ry;
+ float L2;
+ float ly;
+
+ uint8_t idle[16];
+} xRockerBtnDataStruct;
+
+#endif
diff --git a/deploy/deploy_real/cpp_g1/main.cpp b/deploy/deploy_real/cpp_g1/main.cpp
new file mode 100644
index 0000000..1d54043
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/main.cpp
@@ -0,0 +1,17 @@
+#include
+#include "Controller.h"
+
+int main(int argc, char **argv)
+{
+ if (argc != 2)
+ {
+ std::cout << "g1_deploy_real [net_interface]" << std::endl;
+ exit(1);
+ }
+ Controller controller(argv[1]);
+ controller.zero_torque_state();
+ controller.move_to_default_pos();
+ controller.run();
+ controller.damp();
+ return 0;
+}
diff --git a/deploy/deploy_real/cpp_g1/utilities.cpp b/deploy/deploy_real/cpp_g1/utilities.cpp
new file mode 100644
index 0000000..1072dc6
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/utilities.cpp
@@ -0,0 +1,32 @@
+#include "utilities.h"
+
+unsigned int crc32_core(unsigned int* ptr, unsigned int len)
+{
+ unsigned int xbit = 0;
+ unsigned int data = 0;
+ unsigned int CRC32 = 0xFFFFFFFF;
+ const unsigned int dwPolynomial = 0x04c11db7;
+ for (unsigned int i = 0; i < len; i++)
+ {
+ xbit = 1 << 31;
+ data = ptr[i];
+ for (unsigned int bits = 0; bits < 32; bits++)
+ {
+ if (CRC32 & 0x80000000)
+ {
+ CRC32 <<= 1;
+ CRC32 ^= dwPolynomial;
+ }
+ else
+ {
+ CRC32 <<= 1;
+ }
+ if (data & xbit)
+ {
+ CRC32 ^= dwPolynomial;
+ }
+ xbit >>= 1;
+ }
+ }
+ return CRC32;
+}
diff --git a/deploy/deploy_real/cpp_g1/utilities.h b/deploy/deploy_real/cpp_g1/utilities.h
new file mode 100644
index 0000000..4b536f2
--- /dev/null
+++ b/deploy/deploy_real/cpp_g1/utilities.h
@@ -0,0 +1,6 @@
+#ifndef UTILITIES_H
+#define UTILITIES_H
+
+unsigned int crc32_core(unsigned int* ptr, unsigned int len);
+
+#endif
diff --git a/deploy/deploy_real/deploy_real.py b/deploy/deploy_real/deploy_real.py
new file mode 100644
index 0000000..e94dce2
--- /dev/null
+++ b/deploy/deploy_real/deploy_real.py
@@ -0,0 +1,265 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from typing import Union
+import numpy as np
+import time
+import torch
+
+from unitree_sdk2py.core.channel import ChannelPublisher, ChannelFactoryInitialize
+from unitree_sdk2py.core.channel import ChannelSubscriber, ChannelFactoryInitialize
+from unitree_sdk2py.idl.default import unitree_hg_msg_dds__LowCmd_, unitree_hg_msg_dds__LowState_
+from unitree_sdk2py.idl.default import unitree_go_msg_dds__LowCmd_, unitree_go_msg_dds__LowState_
+from unitree_sdk2py.idl.unitree_hg.msg.dds_ import LowCmd_ as LowCmdHG
+from unitree_sdk2py.idl.unitree_go.msg.dds_ import LowCmd_ as LowCmdGo
+from unitree_sdk2py.idl.unitree_hg.msg.dds_ import LowState_ as LowStateHG
+from unitree_sdk2py.idl.unitree_go.msg.dds_ import LowState_ as LowStateGo
+from unitree_sdk2py.utils.crc import CRC
+
+from common.command_helper import create_damping_cmd, create_zero_cmd, init_cmd_hg, init_cmd_go, MotorMode
+from common.rotation_helper import get_gravity_orientation, transform_imu_data
+from common.remote_controller import RemoteController, KeyMap
+from config import Config
+
+
+class Controller:
+ def __init__(self, config: Config) -> None:
+ self.config = config
+ self.remote_controller = RemoteController()
+
+ # Initialize the policy network
+ self.policy = torch.jit.load(config.policy_path)
+ # Initializing process variables
+ self.qj = np.zeros(config.num_actions, dtype=np.float32)
+ self.dqj = np.zeros(config.num_actions, dtype=np.float32)
+ self.action = np.zeros(config.num_actions, dtype=np.float32)
+ self.target_dof_pos = config.default_angles.copy()
+ self.obs = np.zeros(config.num_obs, dtype=np.float32)
+ self.cmd = np.array([0.0, 0, 0])
+ self.counter = 0
+
+ if config.msg_type == "hg":
+ # g1 and h1_2 use the hg msg type
+ self.low_cmd = unitree_hg_msg_dds__LowCmd_()
+ self.low_state = unitree_hg_msg_dds__LowState_()
+ self.mode_pr_ = MotorMode.PR
+ self.mode_machine_ = 0
+
+ self.lowcmd_publisher_ = ChannelPublisher(config.lowcmd_topic, LowCmdHG)
+ self.lowcmd_publisher_.Init()
+
+ self.lowstate_subscriber = ChannelSubscriber(config.lowstate_topic, LowStateHG)
+ self.lowstate_subscriber.Init(self.LowStateHgHandler, 10)
+
+ elif config.msg_type == "go":
+ # h1 uses the go msg type
+ self.low_cmd = unitree_go_msg_dds__LowCmd_()
+ self.low_state = unitree_go_msg_dds__LowState_()
+
+ self.lowcmd_publisher_ = ChannelPublisher(config.lowcmd_topic, LowCmdGo)
+ self.lowcmd_publisher_.Init()
+
+ self.lowstate_subscriber = ChannelSubscriber(config.lowstate_topic, LowStateGo)
+ self.lowstate_subscriber.Init(self.LowStateGoHandler, 10)
+
+ else:
+ raise ValueError("Invalid msg_type")
+
+ # wait for the subscriber to receive data
+ self.wait_for_low_state()
+
+ # Initialize the command msg
+ if config.msg_type == "hg":
+ init_cmd_hg(self.low_cmd, self.mode_machine_, self.mode_pr_)
+ elif config.msg_type == "go":
+ init_cmd_go(self.low_cmd, weak_motor=self.config.weak_motor)
+
+ def LowStateHgHandler(self, msg: LowStateHG):
+ self.low_state = msg
+ self.mode_machine_ = self.low_state.mode_machine
+ self.remote_controller.set(self.low_state.wireless_remote)
+
+ def LowStateGoHandler(self, msg: LowStateGo):
+ self.low_state = msg
+ self.remote_controller.set(self.low_state.wireless_remote)
+
+ def send_cmd(self, cmd: Union[LowCmdGo, LowCmdHG]):
+ cmd.crc = CRC().Crc(cmd)
+ self.lowcmd_publisher_.Write(cmd)
+
+ def wait_for_low_state(self):
+ while self.low_state.tick == 0:
+ time.sleep(self.config.control_dt)
+ print("Successfully connected to the robot.")
+
+ def zero_torque_state(self):
+ print("Enter zero torque state.")
+ print("Waiting for the start signal...")
+ while self.remote_controller.button[KeyMap.start] != 1:
+ create_zero_cmd(self.low_cmd)
+ self.send_cmd(self.low_cmd)
+ time.sleep(self.config.control_dt)
+
+ def move_to_default_pos(self):
+ print("Moving to default pos.")
+ # move time 2s
+ total_time = 2
+ num_step = int(total_time / self.config.control_dt)
+
+ dof_idx = self.config.leg_joint2motor_idx + self.config.arm_waist_joint2motor_idx
+ kps = self.config.kps + self.config.arm_waist_kps
+ kds = self.config.kds + self.config.arm_waist_kds
+ default_pos = np.concatenate((self.config.default_angles, self.config.arm_waist_target), axis=0)
+ dof_size = len(dof_idx)
+
+ # record the current pos
+ init_dof_pos = np.zeros(dof_size, dtype=np.float32)
+ for i in range(dof_size):
+ init_dof_pos[i] = self.low_state.motor_state[dof_idx[i]].q
+
+ # move to default pos
+ for i in range(num_step):
+ alpha = i / num_step
+ for j in range(dof_size):
+ motor_idx = dof_idx[j]
+ target_pos = default_pos[j]
+ self.low_cmd.motor_cmd[motor_idx].q = init_dof_pos[j] * (1 - alpha) + target_pos * alpha
+ self.low_cmd.motor_cmd[motor_idx].qd = 0
+ self.low_cmd.motor_cmd[motor_idx].kp = kps[j]
+ self.low_cmd.motor_cmd[motor_idx].kd = kds[j]
+ self.low_cmd.motor_cmd[motor_idx].tau = 0
+ self.send_cmd(self.low_cmd)
+ time.sleep(self.config.control_dt)
+
+ def default_pos_state(self):
+ print("Enter default pos state.")
+ print("Waiting for the Button A signal...")
+ while self.remote_controller.button[KeyMap.A] != 1:
+ for i in range(len(self.config.leg_joint2motor_idx)):
+ motor_idx = self.config.leg_joint2motor_idx[i]
+ self.low_cmd.motor_cmd[motor_idx].q = self.config.default_angles[i]
+ self.low_cmd.motor_cmd[motor_idx].qd = 0
+ self.low_cmd.motor_cmd[motor_idx].kp = self.config.kps[i]
+ self.low_cmd.motor_cmd[motor_idx].kd = self.config.kds[i]
+ self.low_cmd.motor_cmd[motor_idx].tau = 0
+ for i in range(len(self.config.arm_waist_joint2motor_idx)):
+ motor_idx = self.config.arm_waist_joint2motor_idx[i]
+ self.low_cmd.motor_cmd[motor_idx].q = self.config.arm_waist_target[i]
+ self.low_cmd.motor_cmd[motor_idx].qd = 0
+ self.low_cmd.motor_cmd[motor_idx].kp = self.config.arm_waist_kps[i]
+ self.low_cmd.motor_cmd[motor_idx].kd = self.config.arm_waist_kds[i]
+ self.low_cmd.motor_cmd[motor_idx].tau = 0
+ self.send_cmd(self.low_cmd)
+ time.sleep(self.config.control_dt)
+
+ def run(self):
+ self.counter += 1
+ # Get the current joint position and velocity
+ for i in range(len(self.config.leg_joint2motor_idx)):
+ self.qj[i] = self.low_state.motor_state[self.config.leg_joint2motor_idx[i]].q
+ self.dqj[i] = self.low_state.motor_state[self.config.leg_joint2motor_idx[i]].dq
+
+ # imu_state quaternion: w, x, y, z
+ quat = self.low_state.imu_state.quaternion
+ ang_vel = np.array([self.low_state.imu_state.gyroscope], dtype=np.float32)
+
+ if self.config.imu_type == "torso":
+ # h1 and h1_2 imu is on the torso
+ # imu data needs to be transformed to the pelvis frame
+ waist_yaw = self.low_state.motor_state[self.config.arm_waist_joint2motor_idx[0]].q
+ waist_yaw_omega = self.low_state.motor_state[self.config.arm_waist_joint2motor_idx[0]].dq
+ quat, ang_vel = transform_imu_data(waist_yaw=waist_yaw, waist_yaw_omega=waist_yaw_omega, imu_quat=quat, imu_omega=ang_vel)
+
+ # create observation
+ gravity_orientation = get_gravity_orientation(quat)
+ qj_obs = self.qj.copy()
+ dqj_obs = self.dqj.copy()
+ qj_obs = (qj_obs - self.config.default_angles) * self.config.dof_pos_scale
+ dqj_obs = dqj_obs * self.config.dof_vel_scale
+ ang_vel = ang_vel * self.config.ang_vel_scale
+ period = 0.8
+ count = self.counter * self.config.control_dt
+ phase = count % period / period
+ sin_phase = np.sin(2 * np.pi * phase)
+ cos_phase = np.cos(2 * np.pi * phase)
+
+ self.cmd[0] = self.remote_controller.ly
+ self.cmd[1] = self.remote_controller.lx * -1
+ self.cmd[2] = self.remote_controller.rx * -1
+
+ num_actions = self.config.num_actions
+ self.obs[:3] = ang_vel
+ self.obs[3:6] = gravity_orientation
+ self.obs[6:9] = self.cmd * self.config.cmd_scale * self.config.max_cmd
+ self.obs[9 : 9 + num_actions] = qj_obs
+ self.obs[9 + num_actions : 9 + num_actions * 2] = dqj_obs
+ self.obs[9 + num_actions * 2 : 9 + num_actions * 3] = self.action
+ self.obs[9 + num_actions * 3] = sin_phase
+ self.obs[9 + num_actions * 3 + 1] = cos_phase
+
+ # Get the action from the policy network
+ obs_tensor = torch.from_numpy(self.obs).unsqueeze(0)
+ self.action = self.policy(obs_tensor).detach().numpy().squeeze()
+
+ # transform action to target_dof_pos
+ target_dof_pos = self.config.default_angles + self.action * self.config.action_scale
+
+ # Build low cmd
+ for i in range(len(self.config.leg_joint2motor_idx)):
+ motor_idx = self.config.leg_joint2motor_idx[i]
+ self.low_cmd.motor_cmd[motor_idx].q = target_dof_pos[i]
+ self.low_cmd.motor_cmd[motor_idx].qd = 0
+ self.low_cmd.motor_cmd[motor_idx].kp = self.config.kps[i]
+ self.low_cmd.motor_cmd[motor_idx].kd = self.config.kds[i]
+ self.low_cmd.motor_cmd[motor_idx].tau = 0
+
+ for i in range(len(self.config.arm_waist_joint2motor_idx)):
+ motor_idx = self.config.arm_waist_joint2motor_idx[i]
+ self.low_cmd.motor_cmd[motor_idx].q = self.config.arm_waist_target[i]
+ self.low_cmd.motor_cmd[motor_idx].qd = 0
+ self.low_cmd.motor_cmd[motor_idx].kp = self.config.arm_waist_kps[i]
+ self.low_cmd.motor_cmd[motor_idx].kd = self.config.arm_waist_kds[i]
+ self.low_cmd.motor_cmd[motor_idx].tau = 0
+
+ # send the command
+ self.send_cmd(self.low_cmd)
+
+ time.sleep(self.config.control_dt)
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("net", type=str, help="network interface")
+ parser.add_argument("config", type=str, help="config file name in the configs folder", default="g1.yaml")
+ args = parser.parse_args()
+
+ # Load config
+ config_path = f"{LEGGED_GYM_ROOT_DIR}/deploy/deploy_real/configs/{args.config}"
+ config = Config(config_path)
+
+ # Initialize DDS communication
+ ChannelFactoryInitialize(0, args.net)
+
+ controller = Controller(config)
+
+ # Enter the zero torque state, press the start key to continue executing
+ controller.zero_torque_state()
+
+ # Move to the default position
+ controller.move_to_default_pos()
+
+ # Enter the default position state, press the A key to continue executing
+ controller.default_pos_state()
+
+ while True:
+ try:
+ controller.run()
+ # Press the select key to exit
+ if controller.remote_controller.button[KeyMap.select] == 1:
+ break
+ except KeyboardInterrupt:
+ break
+ # Enter the damping state
+ create_damping_cmd(controller.low_cmd)
+ controller.send_cmd(controller.low_cmd)
+ print("Exit")
diff --git a/deploy/pre_train/g1/motion.pt b/deploy/pre_train/g1/motion.pt
new file mode 100644
index 0000000..91a042a
Binary files /dev/null and b/deploy/pre_train/g1/motion.pt differ
diff --git a/deploy/pre_train/h1/motion.pt b/deploy/pre_train/h1/motion.pt
new file mode 100644
index 0000000..3cb2148
Binary files /dev/null and b/deploy/pre_train/h1/motion.pt differ
diff --git a/deploy/pre_train/h1_2/motion.pt b/deploy/pre_train/h1_2/motion.pt
new file mode 100644
index 0000000..9e75d63
Binary files /dev/null and b/deploy/pre_train/h1_2/motion.pt differ
diff --git a/deploy/pre_train/smallgray/policy_lstm_1.pt b/deploy/pre_train/smallgray/policy_lstm_1.pt
new file mode 100644
index 0000000..3c61b34
Binary files /dev/null and b/deploy/pre_train/smallgray/policy_lstm_1.pt differ
diff --git a/doc/setup_en.md b/doc/setup_en.md
new file mode 100644
index 0000000..ca20ff5
--- /dev/null
+++ b/doc/setup_en.md
@@ -0,0 +1,159 @@
+# Installation Guide
+
+## System Requirements
+
+- **Operating System**: Recommended Ubuntu 18.04 or later
+- **GPU**: Nvidia GPU
+- **Driver Version**: Recommended version 525 or later
+
+---
+
+## 1. Creating a Virtual Environment
+
+It is recommended to run training or deployment programs in a virtual environment. Conda is recommended for creating virtual environments. If Conda is already installed on your system, you can skip step 1.1.
+
+### 1.1 Download and Install MiniConda
+
+MiniConda is a lightweight distribution of Conda, suitable for creating and managing virtual environments. Use the following commands to download and install:
+
+```bash
+mkdir -p ~/miniconda3
+wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
+bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
+rm ~/miniconda3/miniconda.sh
+```
+
+After installation, initialize Conda:
+
+```bash
+~/miniconda3/bin/conda init --all
+source ~/.bashrc
+```
+
+### 1.2 Create a New Environment
+
+Use the following command to create a virtual environment:
+
+```bash
+conda create -n unitree-rl python=3.8
+```
+
+### 1.3 Activate the Virtual Environment
+
+```bash
+conda activate unitree-rl
+```
+
+---
+
+## 2. Installing Dependencies
+
+### 2.1 Install PyTorch
+
+PyTorch is a neural network computation framework used for model training and inference. Install it using the following command:
+
+```bash
+conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
+```
+
+### 2.2 Install Isaac Gym
+
+Isaac Gym is a rigid body simulation and training framework provided by Nvidia.
+
+#### 2.2.1 Download
+
+Download [Isaac Gym](https://developer.nvidia.com/isaac-gym) from Nvidia’s official website.
+
+#### 2.2.2 Install
+
+After extracting the package, navigate to the `isaacgym/python` folder and install it using the following commands:
+
+```bash
+cd isaacgym/python
+pip install -e .
+```
+
+#### 2.2.3 Verify Installation
+
+Run the following command. If a window opens displaying 1080 balls falling, the installation was successful:
+
+```bash
+cd examples
+python 1080_balls_of_solitude.py
+```
+
+If you encounter any issues, refer to the official documentation at `isaacgym/docs/index.html`.
+
+### 2.3 Install rsl_rl
+
+`rsl_rl` is a library implementing reinforcement learning algorithms.
+
+#### 2.3.1 Download
+
+Clone the repository using Git:
+
+```bash
+git clone https://github.com/leggedrobotics/rsl_rl.git
+```
+
+#### 2.3.2 Switch Branch
+
+Switch to the v1.0.2 branch:
+
+```bash
+cd rsl_rl
+git checkout v1.0.2
+```
+
+#### 2.3.3 Install
+
+```bash
+pip install -e .
+```
+
+### 2.4 Install unitree_rl_gym
+
+#### 2.4.1 Download
+
+Clone the repository using Git:
+
+```bash
+git clone https://github.com/unitreerobotics/unitree_rl_gym.git
+```
+
+#### 2.4.2 Install
+
+Navigate to the directory and install it:
+
+```bash
+cd unitree_rl_gym
+pip install -e .
+```
+
+### 2.5 Install unitree_sdk2py (Optional)
+
+`unitree_sdk2py` is a library used for communication with real robots. If you need to deploy the trained model on a physical robot, install this library.
+
+#### 2.5.1 Download
+
+Clone the repository using Git:
+
+```bash
+git clone https://github.com/unitreerobotics/unitree_sdk2_python.git
+```
+
+#### 2.5.2 Install
+
+Navigate to the directory and install it:
+
+```bash
+cd unitree_sdk2_python
+pip install -e .
+```
+
+---
+
+## Summary
+
+After completing the above steps, you are ready to run the related programs in the virtual environment. If you encounter any issues, refer to the official documentation of each component or check if the dependencies are installed correctly.
+
diff --git a/doc/setup_zh.md b/doc/setup_zh.md
new file mode 100644
index 0000000..fe4c310
--- /dev/null
+++ b/doc/setup_zh.md
@@ -0,0 +1,159 @@
+# 安装配置文档
+
+## 系统要求
+
+- **操作系统**:推荐使用 Ubuntu 18.04 或更高版本
+- **显卡**:Nvidia 显卡
+- **驱动版本**:建议使用 525 或更高版本
+
+---
+
+## 1. 创建虚拟环境
+
+建议在虚拟环境中运行训练或部署程序,推荐使用 Conda 创建虚拟环境。如果您的系统中已经安装了 Conda,可以跳过步骤 1.1。
+
+### 1.1 下载并安装 MiniConda
+
+MiniConda 是 Conda 的轻量级发行版,适用于创建和管理虚拟环境。使用以下命令下载并安装:
+
+```bash
+mkdir -p ~/miniconda3
+wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
+bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
+rm ~/miniconda3/miniconda.sh
+```
+
+安装完成后,初始化 Conda:
+
+```bash
+~/miniconda3/bin/conda init --all
+source ~/.bashrc
+```
+
+### 1.2 创建新环境
+
+使用以下命令创建虚拟环境:
+
+```bash
+conda create -n unitree-rl python=3.8
+```
+
+### 1.3 激活虚拟环境
+
+```bash
+conda activate unitree-rl
+```
+
+---
+
+## 2. 安装依赖
+
+### 2.1 安装 PyTorch
+
+PyTorch 是一个神经网络计算框架,用于模型训练和推理。使用以下命令安装:
+
+```bash
+conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
+```
+
+### 2.2 安装 Isaac Gym
+
+Isaac Gym 是 Nvidia 提供的刚体仿真和训练框架。
+
+#### 2.2.1 下载
+
+从 Nvidia 官网下载 [Isaac Gym](https://developer.nvidia.com/isaac-gym)。
+
+#### 2.2.2 安装
+
+解压后进入 `isaacgym/python` 文件夹,执行以下命令安装:
+
+```bash
+cd isaacgym/python
+pip install -e .
+```
+
+#### 2.2.3 验证安装
+
+运行以下命令,若弹出窗口并显示 1080 个球下落,则安装成功:
+
+```bash
+cd examples
+python 1080_balls_of_solitude.py
+```
+
+如有问题,可参考 `isaacgym/docs/index.html` 中的官方文档。
+
+### 2.3 安装 rsl_rl
+
+`rsl_rl` 是一个强化学习算法库。
+
+#### 2.3.1 下载
+
+通过 Git 克隆仓库:
+
+```bash
+git clone https://github.com/leggedrobotics/rsl_rl.git
+```
+
+#### 2.3.2 切换分支
+
+切换到 v1.0.2 分支:
+
+```bash
+cd rsl_rl
+git checkout v1.0.2
+```
+
+#### 2.3.3 安装
+
+```bash
+pip install -e .
+```
+
+### 2.4 安装 unitree_rl_gym
+
+#### 2.4.1 下载
+
+通过 Git 克隆仓库:
+
+```bash
+git clone https://github.com/unitreerobotics/unitree_rl_gym.git
+```
+
+#### 2.4.2 安装
+
+进入目录并安装:
+
+```bash
+cd unitree_rl_gym
+pip install -e .
+```
+
+### 2.5 安装 unitree_sdk2py(可选)
+
+`unitree_sdk2py` 是用于与真实机器人通信的库。如果需要将训练的模型部署到物理机器人上运行,可以安装此库。
+
+#### 2.5.1 下载
+
+通过 Git 克隆仓库:
+
+```bash
+git clone https://github.com/unitreerobotics/unitree_sdk2_python.git
+```
+
+#### 2.5.2 安装
+
+进入目录并安装:
+
+```bash
+cd unitree_sdk2_python
+pip install -e .
+```
+
+---
+
+## 总结
+
+按照上述步骤完成后,您已经准备好在虚拟环境中运行相关程序。若遇到问题,请参考各组件的官方文档或检查依赖安装是否正确。
+
diff --git a/legged_gym/LICENSE b/legged_gym/LICENSE
new file mode 100644
index 0000000..92e75a2
--- /dev/null
+++ b/legged_gym/LICENSE
@@ -0,0 +1,31 @@
+Copyright (c) 2021, ETH Zurich, Nikita Rudin
+Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without modification,
+are permitted provided that the following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice,
+ this list of conditions and the following disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+3. Neither the name of the copyright holder nor the names of its contributors
+ may be used to endorse or promote products derived from this software without
+ specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
+ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
+WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
+ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
+(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
+LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
+ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
+(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
+SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+
+See licenses/assets for license information for assets included in this repository.
+See licenses/dependencies for license information of dependencies of this package.
diff --git a/legged_gym/__init__.py b/legged_gym/__init__.py
new file mode 100644
index 0000000..203ddd4
--- /dev/null
+++ b/legged_gym/__init__.py
@@ -0,0 +1,4 @@
+import os
+
+LEGGED_GYM_ROOT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
+LEGGED_GYM_ENVS_DIR = os.path.join(LEGGED_GYM_ROOT_DIR, 'legged_gym', 'envs')
\ No newline at end of file
diff --git a/legged_gym/envs/__init__.py b/legged_gym/envs/__init__.py
new file mode 100644
index 0000000..42554ff
--- /dev/null
+++ b/legged_gym/envs/__init__.py
@@ -0,0 +1,12 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, LEGGED_GYM_ENVS_DIR
+
+from legged_gym.envs.fh.fh_config import FHRoughCfg, FHRoughCfgPPO
+from legged_gym.envs.fh.fh_env import FH_Env
+
+from legged_gym.envs.proto.pro_config import PRORoughCfg, PRORoughCfgPPO
+from legged_gym.envs.proto.pro_env import PRO_Env
+
+from legged_gym.utils.task_registry import task_registry
+
+task_registry.register("fh",FH_Env, FHRoughCfg(), FHRoughCfgPPO())
+task_registry.register("proto",PRO_Env, PRORoughCfg(), PRORoughCfgPPO())
diff --git a/legged_gym/envs/base/base_config.py b/legged_gym/envs/base/base_config.py
new file mode 100644
index 0000000..147ae05
--- /dev/null
+++ b/legged_gym/envs/base/base_config.py
@@ -0,0 +1,25 @@
+import inspect
+
+class BaseConfig:
+ def __init__(self) -> None:
+ """ Initializes all member classes recursively. Ignores all namse starting with '__' (buit-in methods)."""
+ self.init_member_classes(self)
+
+ @staticmethod
+ def init_member_classes(obj):
+ # iterate over all attributes names
+ for key in dir(obj):
+ # disregard builtin attributes
+ # if key.startswith("__"):
+ if key=="__class__":
+ continue
+ # get the corresponding attribute object
+ var = getattr(obj, key)
+ # check if it the attribute is a class
+ if inspect.isclass(var):
+ # instantate the class
+ i_var = var()
+ # set the attribute to the instance instead of the type
+ setattr(obj, key, i_var)
+ # recursively init members of the attribute
+ BaseConfig.init_member_classes(i_var)
\ No newline at end of file
diff --git a/legged_gym/envs/base/base_task.py b/legged_gym/envs/base/base_task.py
new file mode 100644
index 0000000..325fcce
--- /dev/null
+++ b/legged_gym/envs/base/base_task.py
@@ -0,0 +1,115 @@
+
+import sys
+from isaacgym import gymapi
+from isaacgym import gymutil
+import numpy as np
+import torch
+
+# Base class for RL tasks
+class BaseTask():
+
+ def __init__(self, cfg, sim_params, physics_engine, sim_device, headless):
+ self.gym = gymapi.acquire_gym()
+
+ self.sim_params = sim_params
+ self.physics_engine = physics_engine
+ self.sim_device = sim_device
+ sim_device_type, self.sim_device_id = gymutil.parse_device_str(self.sim_device)
+ self.headless = headless
+
+ # env device is GPU only if sim is on GPU and use_gpu_pipeline=True, otherwise returned tensors are copied to CPU by physX.
+ if sim_device_type=='cuda' and sim_params.use_gpu_pipeline:
+ self.device = self.sim_device
+ else:
+ self.device = 'cpu'
+
+ # graphics device for rendering, -1 for no rendering
+ self.graphics_device_id = self.sim_device_id
+ if self.headless == True:
+ self.graphics_device_id = -1
+
+ self.num_envs = cfg.env.num_envs
+ self.num_obs = cfg.env.num_observations
+ self.num_privileged_obs = cfg.env.num_privileged_obs
+ self.num_actions = cfg.env.num_actions
+
+ # optimization flags for pytorch JIT
+ torch._C._jit_set_profiling_mode(False)
+ torch._C._jit_set_profiling_executor(False)
+
+ # allocate buffers
+ self.obs_buf = torch.zeros(self.num_envs, self.num_obs, device=self.device, dtype=torch.float)
+ self.rew_buf = torch.zeros(self.num_envs, device=self.device, dtype=torch.float)
+ self.reset_buf = torch.ones(self.num_envs, device=self.device, dtype=torch.long)
+ self.episode_length_buf = torch.zeros(self.num_envs, device=self.device, dtype=torch.long)
+ self.time_out_buf = torch.zeros(self.num_envs, device=self.device, dtype=torch.bool)
+ if self.num_privileged_obs is not None:
+ self.privileged_obs_buf = torch.zeros(self.num_envs, self.num_privileged_obs, device=self.device, dtype=torch.float)
+ else:
+ self.privileged_obs_buf = None
+ # self.num_privileged_obs = self.num_obs
+
+ self.extras = {}
+
+ # create envs, sim and viewer
+ self.create_sim()
+ self.gym.prepare_sim(self.sim)
+
+ # todo: read from config
+ self.enable_viewer_sync = True
+ self.viewer = None
+
+ # if running with a viewer, set up keyboard shortcuts and camera
+ if self.headless == False:
+ # subscribe to keyboard shortcuts
+ self.viewer = self.gym.create_viewer(
+ self.sim, gymapi.CameraProperties())
+ self.gym.subscribe_viewer_keyboard_event(
+ self.viewer, gymapi.KEY_ESCAPE, "QUIT")
+ self.gym.subscribe_viewer_keyboard_event(
+ self.viewer, gymapi.KEY_V, "toggle_viewer_sync")
+
+ def get_observations(self):
+ return self.obs_buf
+
+ def get_privileged_observations(self):
+ return self.privileged_obs_buf
+
+ def reset_idx(self, env_ids):
+ """Reset selected robots"""
+ raise NotImplementedError
+
+ def reset(self):
+ """ Reset all robots"""
+ self.reset_idx(torch.arange(self.num_envs, device=self.device))
+ obs, privileged_obs, _, _, _ = self.step(torch.zeros(self.num_envs, self.num_actions, device=self.device, requires_grad=False))
+ return obs, privileged_obs
+
+ def step(self, actions):
+ raise NotImplementedError
+
+ def render(self, sync_frame_time=True):
+ if self.viewer:
+ # check for window closed
+ if self.gym.query_viewer_has_closed(self.viewer):
+ sys.exit()
+
+ # check for keyboard events
+ for evt in self.gym.query_viewer_action_events(self.viewer):
+ if evt.action == "QUIT" and evt.value > 0:
+ sys.exit()
+ elif evt.action == "toggle_viewer_sync" and evt.value > 0:
+ self.enable_viewer_sync = not self.enable_viewer_sync
+
+ # fetch results
+ if self.device != 'cpu':
+ self.gym.fetch_results(self.sim, True)
+
+ # step graphics
+ if self.enable_viewer_sync:
+ self.gym.step_graphics(self.sim)
+ self.gym.draw_viewer(self.viewer, self.sim, True)
+ if sync_frame_time:
+ self.gym.sync_frame_time(self.sim)
+ else:
+ self.gym.poll_viewer_events(self.viewer)
\ No newline at end of file
diff --git a/legged_gym/envs/base/legged_robot.py b/legged_gym/envs/base/legged_robot.py
new file mode 100644
index 0000000..11e1047
--- /dev/null
+++ b/legged_gym/envs/base/legged_robot.py
@@ -0,0 +1,893 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, envs
+import time
+from warnings import WarningMessage
+import numpy as np
+import os
+
+from isaacgym.torch_utils import *
+from isaacgym import gymtorch, gymapi, gymutil
+
+import torch
+from torch import Tensor
+from typing import Tuple, Dict
+
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from legged_gym.envs.base.base_task import BaseTask
+from legged_gym.utils.math import quat_apply_yaw, wrap_to_pi, torch_rand_sqrt_float
+from legged_gym.utils.isaacgym_utils import get_euler_xyz as get_euler_xyz_in_tensor
+from legged_gym.utils.helpers import class_to_dict
+from .legged_robot_config import LeggedRobotCfg
+
+class LeggedRobot(BaseTask):
+ def __init__(self, cfg: LeggedRobotCfg, sim_params, physics_engine, sim_device, headless):
+ """ Parses the provided config file,
+ calls create_sim() (which creates, simulation and environments),
+ initilizes pytorch buffers used during training
+
+ Args:
+ cfg (Dict): Environment config file
+ sim_params (gymapi.SimParams): simulation parameters
+ physics_engine (gymapi.SimType): gymapi.SIM_PHYSX (must be PhysX)
+ device_type (string): 'cuda' or 'cpu'
+ device_id (int): 0, 1, ...
+ headless (bool): Run without rendering if True
+ """
+ self.cfg = cfg
+ self.sim_params = sim_params
+ self.height_samples = None
+ self.debug_viz = False
+ self.init_done = False
+ self._parse_cfg(self.cfg)
+ super().__init__(self.cfg, sim_params, physics_engine, sim_device, headless)
+
+ if not self.headless:
+ self.set_camera(self.cfg.viewer.pos, self.cfg.viewer.lookat)
+ self._init_buffers()
+ self._prepare_reward_function()
+ self.init_done = True
+
+ def step(self, actions):
+ """ Apply actions, simulate, call self.post_physics_step()
+
+ Args:
+ actions (torch.Tensor): Tensor of shape (num_envs, num_actions_per_env)
+ """
+
+ clip_actions = self.cfg.normalization.clip_actions
+ self.actions = torch.clip(actions, -clip_actions, clip_actions).to(self.device)
+ # step physics and render each frame
+ self.render()
+ for _ in range(self.cfg.control.decimation):
+ self.torques = self._compute_torques(self.actions).view(self.torques.shape)
+ self.gym.set_dof_actuation_force_tensor(self.sim, gymtorch.unwrap_tensor(self.torques))
+ self.gym.simulate(self.sim)
+ if self.cfg.env.test:
+ elapsed_time = self.gym.get_elapsed_time(self.sim)
+ sim_time = self.gym.get_sim_time(self.sim)
+ if sim_time-elapsed_time>0:
+ time.sleep(sim_time-elapsed_time)
+
+ if self.device == 'cpu':
+ self.gym.fetch_results(self.sim, True)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.post_physics_step()
+
+ # return clipped obs, clipped states (None), rewards, dones and infos
+ clip_obs = self.cfg.normalization.clip_observations
+ self.obs_buf = torch.clip(self.obs_buf, -clip_obs, clip_obs)
+ if self.privileged_obs_buf is not None:
+ self.privileged_obs_buf = torch.clip(self.privileged_obs_buf, -clip_obs, clip_obs)
+ return self.obs_buf, self.privileged_obs_buf, self.rew_buf, self.reset_buf, self.extras
+
+ def update_cmd_action_latency_buffer(self):
+ actions_scaled = self.actions * self.cfg.control.action_scale
+ if self.cfg.domain_rand.add_cmd_action_latency:
+ self.cmd_action_latency_buffer[:, :, 1:] = self.cmd_action_latency_buffer[
+ :, :, :self.cfg.domain_rand.range_cmd_action_latency[1]].clone()
+ self.cmd_action_latency_buffer[:, :, 0] = actions_scaled.clone()
+ action_delayed = self.cmd_action_latency_buffer[
+ torch.arange(self.num_envs), :, self.cmd_action_latency_simstep.long()]
+ else:
+ action_delayed = actions_scaled
+
+ return action_delayed
+
+ def update_obs_latency_buffer(self):
+ if self.cfg.domain_rand.randomize_obs_motor_latency:
+ q = (self.dof_pos - self.default_dof_pos) * self.obs_scales.dof_pos
+ dq = self.dof_vel * self.obs_scales.dof_vel
+ self.obs_motor_latency_buffer[:, :, 1:] = self.obs_motor_latency_buffer[
+ :, :, :self.cfg.domain_rand.range_obs_motor_latency[1]].clone()
+ self.obs_motor_latency_buffer[:, :, 0] = torch.cat((q, dq) , 1).clone()
+ if self.cfg.domain_rand.randomize_obs_imu_latency:
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ self.obs_imu_latency_buffer[:, :, 1:] = self.obs_imu_latency_buffer[
+ :, :, :self.cfg.domain_rand.range_obs_imu_latency[1]].clone()
+ self.obs_imu_latency_buffer[:, :, 0] = torch.cat(
+ (self.base_ang_vel * self.obs_scales.ang_vel, self.projected_gravity), 1).clone()
+
+ def post_physics_step(self):
+ """ check terminations, compute observations and rewards
+ calls self._post_physics_step_callback() for common computations
+ calls self._draw_debug_vis() if needed
+ """
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ self.episode_length_buf += 1
+ self.common_step_counter += 1
+
+ # prepare quantities
+ self.base_pos[:] = self.root_states[:, 0:3]
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.rpy[:] = get_euler_xyz_in_tensor(self.base_quat[:])
+ self.base_lin_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+
+ self._post_physics_step_callback()
+
+ # compute observations, rewards, resets, ...
+ self.check_termination()
+ self.compute_reward()
+ env_ids = self.reset_buf.nonzero(as_tuple=False).flatten()
+ self.reset_idx(env_ids)
+
+ if self.cfg.domain_rand.push_robots:
+ self._push_robots()
+
+ self.compute_observations() # in some cases a simulation step might be required to refresh some obs (for example body positions)
+
+ self.last_actions[:] = self.actions[:]
+ self.last_dof_vel[:] = self.dof_vel[:]
+ self.last_root_vel[:] = self.root_states[:, 7:13]
+
+ def check_termination(self):
+ """ Check if environments need to be reset
+ """
+ self.reset_buf = torch.any(torch.norm(self.contact_forces[:, self.termination_contact_indices, :], dim=-1) > 1., dim=1)
+ self.reset_buf |= torch.logical_or(torch.abs(self.rpy[:,1])>1.0, torch.abs(self.rpy[:,0])>0.8)
+ self.time_out_buf = self.episode_length_buf > self.max_episode_length # no terminal reward for time-outs
+ self.reset_buf |= self.time_out_buf
+
+ def reset_idx(self, env_ids):
+ """ Reset some environments.
+ Calls self._reset_dofs(env_ids), self._reset_root_states(env_ids), and self._resample_commands(env_ids)
+ [Optional] calls self._update_terrain_curriculum(env_ids), self.update_command_curriculum(env_ids) and
+ Logs episode info
+ Resets some buffers
+
+ Args:
+ env_ids (list[int]): List of environment ids which must be reset
+ """
+ if len(env_ids) == 0:
+ return
+
+ # reset robot states
+ self._reset_dofs(env_ids)
+ self._reset_root_states(env_ids)
+
+ self._resample_commands(env_ids)
+
+ # reset buffers
+ self.actions[env_ids] = 0.
+ self.last_actions[env_ids] = 0.
+ self.last_dof_vel[env_ids] = 0.
+ self.feet_air_time[env_ids] = 0.
+ self.episode_length_buf[env_ids] = 0
+ self.reset_buf[env_ids] = 1
+ # fill extras
+ self.extras["episode"] = {}
+ for key in self.episode_sums.keys():
+ self.extras["episode"]['rew_' + key] = torch.mean(self.episode_sums[key][env_ids]) / self.max_episode_length_s
+ self.episode_sums[key][env_ids] = 0.
+ if self.cfg.commands.curriculum:
+ self.extras["episode"]["max_command_x"] = self.command_ranges["lin_vel_x"][1]
+ # send timeout info to the algorithm
+ if self.cfg.env.send_timeouts:
+ self.extras["time_outs"] = self.time_out_buf
+
+ def compute_reward(self):
+ """ Compute rewards
+ Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
+ adds each terms to the episode sums and to the total reward
+ """
+ self.rew_buf[:] = 0.
+ for i in range(len(self.reward_functions)):
+ name = self.reward_names[i]
+ rew = self.reward_functions[i]() * self.reward_scales[name]
+ self.rew_buf += rew
+ self.episode_sums[name] += rew
+ if self.cfg.rewards.only_positive_rewards:
+ self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
+ # add termination reward after clipping
+ if "termination" in self.reward_scales:
+ rew = self._reward_termination() * self.reward_scales["termination"]
+ self.rew_buf += rew
+ self.episode_sums["termination"] += rew
+
+ def compute_observations(self):
+ """ Computes observations
+ """
+ self.obs_buf = torch.cat(( self.base_lin_vel * self.obs_scales.lin_vel,
+ self.base_ang_vel * self.obs_scales.ang_vel,
+ self.projected_gravity,
+ self.commands[:, :3] * self.commands_scale,
+ (self.dof_pos - self.default_dof_pos) * self.obs_scales.dof_pos,
+ self.dof_vel * self.obs_scales.dof_vel,
+ self.actions
+ ),dim=-1)
+ # add perceptive inputs if not blind
+ # add noise if needed
+ if self.add_noise:
+ self.obs_buf += (2 * torch.rand_like(self.obs_buf) - 1) * self.noise_scale_vec
+
+ def create_sim(self):
+ """ Creates simulation, terrain and evironments
+ """
+ self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
+ self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine, self.sim_params)
+ self._create_ground_plane()
+ self._create_envs()
+
+ def set_camera(self, position, lookat):
+ """ Set camera position and direction
+ """
+ cam_pos = gymapi.Vec3(position[0], position[1], position[2])
+ cam_target = gymapi.Vec3(lookat[0], lookat[1], lookat[2])
+ self.gym.viewer_camera_look_at(self.viewer, None, cam_pos, cam_target)
+
+ #------------- Callbacks --------------
+ def _process_rigid_shape_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the rigid shape properties of each environment.
+ Called During environment creation.
+ Base behavior: randomizes the friction of each environment
+
+ Args:
+ props (List[gymapi.RigidShapeProperties]): Properties of each shape of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [List[gymapi.RigidShapeProperties]]: Modified rigid shape properties
+ """
+ if self.cfg.domain_rand.randomize_friction:
+ if env_id==0:
+ # prepare friction randomization
+ friction_range = self.cfg.domain_rand.friction_range
+ restitution_range = self.cfg.domain_rand.restitution_range
+ num_buckets = 256
+ bucket_ids = torch.randint(0, num_buckets, (self.num_envs, 1))
+ friction_buckets = torch_rand_float(friction_range[0], friction_range[1], (num_buckets,1), device='cpu')
+ restitution_buckets = torch_rand_float(restitution_range[0], restitution_range[1], (num_buckets, 1),device='cpu')
+ self.friction_coeffs = friction_buckets[bucket_ids]
+ self.restitution_coeffs = restitution_buckets[bucket_ids]
+
+ for s in range(len(props)):
+ props[s].friction = self.friction_coeffs[env_id]
+ props[s].restitution = self.restitution_coeffs[env_id]
+
+ self.env_frictions[env_id] = self.friction_coeffs[env_id]
+
+ return props
+
+ def _process_dof_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the DOF properties of each environment.
+ Called During environment creation.
+ Base behavior: stores position, velocity and torques limits defined in the URDF
+
+ Args:
+ props (numpy.array): Properties of each DOF of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [numpy.array]: Modified DOF properties
+ """
+ if env_id==0:
+ self.dof_pos_limits = torch.zeros(self.num_dof, 2, dtype=torch.float, device=self.device, requires_grad=False)
+ self.dof_vel_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.torque_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(len(props)):
+ self.dof_pos_limits[i, 0] = props["lower"][i].item()
+ self.dof_pos_limits[i, 1] = props["upper"][i].item()
+ self.dof_vel_limits[i] = props["velocity"][i].item()
+ self.torque_limits[i] = props["effort"][i].item()
+ # soft limits
+ m = (self.dof_pos_limits[i, 0] + self.dof_pos_limits[i, 1]) / 2
+ r = self.dof_pos_limits[i, 1] - self.dof_pos_limits[i, 0]
+ self.dof_pos_limits[i, 0] = m - 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ self.dof_pos_limits[i, 1] = m + 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+
+ # randomization of the motor torques for real machine
+ if self.cfg.domain_rand.randomize_calculated_torque:
+ self.torque_multiplier[env_id, :] = torch_rand_float(self.cfg.domain_rand.torque_multiplier_range[0],
+ self.cfg.domain_rand.torque_multiplier_range[1],
+ (1, self.num_actions), device=self.device)
+
+ # randomization of the motor zero calibration for real machine
+ if self.cfg.domain_rand.randomize_motor_zero_offset:
+ self.motor_zero_offsets[env_id, :] = torch_rand_float(self.cfg.domain_rand.motor_zero_offset_range[0],
+ self.cfg.domain_rand.motor_zero_offset_range[1],
+ (1, self.num_actions), device=self.device)
+
+ # randomization of the motor pd gains
+ if self.cfg.domain_rand.randomize_pd_gains:
+ self.p_gains_multiplier[env_id, :] = torch_rand_float(self.cfg.domain_rand.stiffness_multiplier_range[0],
+ self.cfg.domain_rand.stiffness_multiplier_range[1],
+ (1, self.num_actions), device=self.device)
+ self.d_gains_multiplier[env_id, :] = torch_rand_float(self.cfg.domain_rand.damping_multiplier_range[0],
+ self.cfg.domain_rand.damping_multiplier_range[1],
+ (1, self.num_actions), device=self.device)
+
+ # randomization of the motor frictions in issac gym
+ if self.cfg.domain_rand.randomize_joint_friction:
+ self.joint_friction_coeffs[env_id, 0] = torch_rand_float(self.cfg.domain_rand.joint_friction_range[0],
+ self.cfg.domain_rand.joint_friction_range[1],
+ (1, 1), device=self.device)
+
+ # randomization of the motor dampings in issac gym
+ if self.cfg.domain_rand.randomize_joint_damping:
+ self.joint_damping_coeffs[env_id, 0] = torch_rand_float(self.cfg.domain_rand.joint_damping_range[0],
+ self.cfg.domain_rand.joint_damping_range[1], (1, 1),
+ device=self.device)
+
+ # randomization of the motor armature in issac gym
+ if self.cfg.domain_rand.randomize_joint_armature:
+ self.joint_armatures[env_id, 0] = torch_rand_float(self.cfg.domain_rand.joint_armature_range[0],
+ self.cfg.domain_rand.joint_armature_range[1], (1, 1),
+ device=self.device)
+
+ for i in range(len(props)):
+ props["friction"][i] *= self.joint_friction_coeffs[env_id, 0]
+ props["damping"][i] *= self.joint_damping_coeffs[env_id, 0]
+ props["armature"][i] = self.joint_armatures[env_id, 0]
+
+ return props
+
+ def _process_rigid_body_props(self, props, env_id):
+ # if env_id==0:
+ # sum = 0
+ # for i, p in enumerate(props):
+ # sum += p.mass
+ # print(f"Mass of body {i}: {p.mass} (before randomization)")
+ # print(f"Total mass {sum} (before randomization)")
+ # randomize base mass
+ if self.cfg.domain_rand.randomize_base_mass:
+ self.added_base_masses = torch_rand_float(self.cfg.domain_rand.added_base_mass_range[0],
+ self.cfg.domain_rand.added_base_mass_range[1], (1, 1),
+ device=self.device)
+ props[0].mass += self.added_base_masses
+
+ self.body_mass[:] = props[0].mass
+
+ # randomize link masses
+ if self.cfg.domain_rand.randomize_link_mass:
+ self.multiplied_link_masses_ratio = torch_rand_float(self.cfg.domain_rand.multiplied_link_mass_range[0],
+ self.cfg.domain_rand.multiplied_link_mass_range[1],
+ (1, self.num_bodies - 1), device=self.device)
+
+ for i in range(1, len(props)):
+ props[i].mass *= self.multiplied_link_masses_ratio[0, i - 1]
+
+ # randomize base com
+ if self.cfg.domain_rand.randomize_base_com:
+ self.added_base_com = torch_rand_float(self.cfg.domain_rand.added_base_com_range[0],
+ self.cfg.domain_rand.added_base_com_range[1], (1, 3),
+ device=self.device)
+ props[0].com += gymapi.Vec3(self.added_base_com[0, 0], self.added_base_com[0, 1],
+ self.added_base_com[0, 2])
+
+ return props
+
+ def _post_physics_step_callback(self):
+ """ Callback called before computing terminations, rewards, and observations
+ Default behaviour: Compute ang vel command based on target and heading, compute measured terrain heights and randomly push robots
+ """
+ #
+ env_ids = (self.episode_length_buf % int(self.cfg.commands.resampling_time / self.dt)==0).nonzero(as_tuple=False).flatten()
+ self._resample_commands(env_ids)
+ if self.cfg.commands.heading_command:
+ forward = quat_apply(self.base_quat, self.forward_vec)
+ heading = torch.atan2(forward[:, 1], forward[:, 0])
+ self.commands[:, 2] = torch.clip(0.5*wrap_to_pi(self.commands[:, 3] - heading), -1., 1.)
+
+ if self.cfg.domain_rand.push_robots and (self.common_step_counter % self.cfg.domain_rand.push_interval == 0):
+ self._push_robots()
+
+
+ def _resample_commands(self, env_ids):
+ """ Randommly select commands of some environments
+
+ Args:
+ env_ids (List[int]): Environments ids for which new commands are needed
+ """
+ self.commands[env_ids, 0] = torch_rand_float(self.command_ranges["lin_vel_x"][0], self.command_ranges["lin_vel_x"][1], (len(env_ids), 1), device=self.device).squeeze(1)
+ self.commands[env_ids, 1] = torch_rand_float(self.command_ranges["lin_vel_y"][0], self.command_ranges["lin_vel_y"][1], (len(env_ids), 1), device=self.device).squeeze(1)
+ if self.cfg.commands.heading_command:
+ self.commands[env_ids, 3] = torch_rand_float(self.command_ranges["heading"][0], self.command_ranges["heading"][1], (len(env_ids), 1), device=self.device).squeeze(1)
+ else:
+ self.commands[env_ids, 2] = torch_rand_float(self.command_ranges["ang_vel_yaw"][0], self.command_ranges["ang_vel_yaw"][1], (len(env_ids), 1), device=self.device).squeeze(1)
+
+ # set small commands to zero
+ self.commands[env_ids, :2] *= (torch.norm(self.commands[env_ids, :2], dim=1) > 0.2).unsqueeze(1)
+
+ def _compute_torques(self, actions):
+ """ Compute torques from actions.
+ Actions can be interpreted as position or velocity targets given to a PD controller, or directly as scaled torques.
+ [NOTE]: torques must have the same dimension as the number of DOFs, even if some DOFs are not actuated.
+
+ Args:
+ actions (torch.Tensor): Actions
+
+ Returns:
+ [torch.Tensor]: Torques sent to the simulation
+ """
+ #pd controller
+ actions_scaled = actions * self.cfg.control.action_scale
+ control_type = self.cfg.control.control_type
+ if control_type=="P":
+ torques = self.p_gains*(actions_scaled + self.default_dof_pos - self.dof_pos) - self.d_gains*self.dof_vel
+ elif control_type=="V":
+ torques = self.p_gains*(actions_scaled - self.dof_vel) - self.d_gains*(self.dof_vel - self.last_dof_vel)/self.sim_params.dt
+ elif control_type=="T":
+ torques = actions_scaled
+ else:
+ raise NameError(f"Unknown controller type: {control_type}")
+ return torch.clip(torques, -self.torque_limits, self.torque_limits)
+
+ def _reset_dofs(self, env_ids):
+ """ Resets DOF position and velocities of selected environmments
+ Positions are randomly selected within 0.5:1.5 x default positions.
+ Velocities are set to zero.
+
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ self.dof_pos[env_ids] = self.default_dof_pos * torch_rand_float(0.5, 1.5, (len(env_ids), self.num_dof), device=self.device)
+ self.dof_vel[env_ids] = 0.
+
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_dof_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.dof_state),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+ def _reset_root_states(self, env_ids):
+ """ Resets ROOT states position and velocities of selected environmments
+ Sets base position based on the curriculum
+ Selects randomized base velocities within -0.5:0.5 [m/s, rad/s]
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ # base position
+ if self.custom_origins:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ self.root_states[env_ids, :2] += torch_rand_float(-1., 1., (len(env_ids), 2), device=self.device) # xy position within 1m of the center
+ else:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ # base velocities
+ self.root_states[env_ids, 7:13] = torch_rand_float(-0.5, 0.5, (len(env_ids), 6), device=self.device) # [7:10]: lin vel, [10:13]: ang vel
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ if self.cfg.domain_rand.randomize_imu_init:
+ yaw_angles = torch_rand_sqrt_float(self.cfg.domain_rand.imu_init_yaw_range[0],
+ self.cfg.domain_rand.imu_init_yaw_range[1], (len(env_ids),),
+ device=self.device)
+ # 构造四元数
+ quat = torch.zeros((len(env_ids), 4), device=self.device)
+ quat[:, 2] = torch.sin(yaw_angles / 2)
+ quat[:, 3] = torch.cos(yaw_angles / 2)
+ # 直接覆盖
+ self.root_states[env_ids, 3:7] = quat
+
+ def _push_robots(self):
+ """ Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
+ """
+ env_ids = torch.arange(self.num_envs, device=self.device)
+ push_env_ids = env_ids[self.episode_length_buf[env_ids] % int(self.cfg.domain_rand.push_interval) == 0]
+ if len(push_env_ids) == 0:
+ return
+ max_vel = self.cfg.domain_rand.max_push_vel_xy
+ self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2), device=self.device) # lin vel x/y
+
+ env_ids_int32 = push_env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+
+
+ def update_command_curriculum(self, env_ids):
+ """ Implements a curriculum of increasing commands
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # If the tracking reward is above 80% of the maximum, increase the range of commands
+ if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * self.reward_scales["tracking_lin_vel"]:
+ self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5, -self.cfg.commands.max_curriculum, 0.)
+ self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0., self.cfg.commands.max_curriculum)
+
+
+ def _get_noise_scale_vec(self, cfg):
+ """ Sets a vector used to scale the noise added to the observations.
+ [NOTE]: Must be adapted when changing the observations structure
+
+ Args:
+ cfg (Dict): Environment config file
+
+ Returns:
+ [torch.Tensor]: Vector of scales used to multiply a uniform distribution in [-1, 1]
+ """
+ noise_vec = torch.zeros_like(self.obs_buf[0])
+ self.add_noise = self.cfg.noise.add_noise
+ noise_scales = self.cfg.noise.noise_scales
+ noise_level = self.cfg.noise.noise_level
+ noise_vec[:3] = noise_scales.lin_vel * noise_level * self.obs_scales.lin_vel
+ noise_vec[3:6] = noise_scales.ang_vel * noise_level * self.obs_scales.ang_vel
+ noise_vec[6:9] = noise_scales.gravity * noise_level
+ noise_vec[9:12] = 0. # commands
+ noise_vec[12:12+self.num_actions] = noise_scales.dof_pos * noise_level * self.obs_scales.dof_pos
+ noise_vec[12+self.num_actions:12+2*self.num_actions] = noise_scales.dof_vel * noise_level * self.obs_scales.dof_vel
+ noise_vec[12+2*self.num_actions:12+3*self.num_actions] = 0. # previous actions
+
+ return noise_vec
+
+ #----------------------------------------
+ def _init_buffers(self):
+ """ Initialize torch tensors which will contain simulation states and processed quantities
+ """
+ # get gym GPU state tensors
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+ rigid_body_state = self.gym.acquire_rigid_body_state_tensor(self.sim)
+
+
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+
+ # create some wrapper tensors for different slices
+ self.root_states = gymtorch.wrap_tensor(actor_root_state)
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+ self.rpy = get_euler_xyz_in_tensor(self.base_quat)
+ self.base_pos = self.root_states[:self.num_envs, 0:3]
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1, 3) # shape: num_envs, num_bodies, xyz axis
+
+ # initialize some data used later on
+ self.common_step_counter = 0
+ self.extras = {}
+ self.noise_scale_vec = self._get_noise_scale_vec(self.cfg)
+ self.gravity_vec = to_torch(get_axis_params(-1., self.up_axis_idx), device=self.device).repeat((self.num_envs, 1))
+ self.forward_vec = to_torch([1., 0., 0.], device=self.device).repeat((self.num_envs, 1))
+ self.torques = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.last_actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.last_dof_vel = torch.zeros_like(self.dof_vel)
+ self.last_root_vel = torch.zeros_like(self.root_states[:, 7:13])
+ self.commands = torch.zeros(self.num_envs, self.cfg.commands.num_commands, dtype=torch.float, device=self.device, requires_grad=False) # x vel, y vel, yaw vel, heading
+ self.commands_scale = torch.tensor([self.obs_scales.lin_vel, self.obs_scales.lin_vel, self.obs_scales.ang_vel], device=self.device, requires_grad=False,) # TODO change this
+ self.feet_air_time = torch.zeros(self.num_envs, self.feet_indices.shape[0], dtype=torch.float, device=self.device, requires_grad=False)
+ self.last_contacts = torch.zeros(self.num_envs, len(self.feet_indices), dtype=torch.bool, device=self.device, requires_grad=False)
+ self.base_lin_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+
+
+ # joint positions offsets and PD gains
+ self.default_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(self.num_dofs):
+ name = self.dof_names[i]
+ angle = self.cfg.init_state.default_joint_angles[name]
+ self.default_dof_pos[i] = angle
+ found = False
+ for dof_name in self.cfg.control.stiffness.keys():
+ if dof_name in name:
+ self.p_gains[i] = self.cfg.control.stiffness[dof_name]
+ self.d_gains[i] = self.cfg.control.damping[dof_name]
+ found = True
+ if not found:
+ self.p_gains[i] = 0.
+ self.d_gains[i] = 0.
+ if self.cfg.control.control_type in ["P", "V"]:
+ print(f"PD gain of joint {name} were not defined, setting them to zero")
+
+ self.rand_push_force = torch.zeros((self.num_envs, 3), dtype=torch.float32, device=self.device)
+ self.rand_push_torque = torch.zeros((self.num_envs, 3), dtype=torch.float32, device=self.device)
+ self.default_dof_pos = self.default_dof_pos.unsqueeze(0)
+
+ self.default_joint_pd_target = self.default_dof_pos.clone()
+ self.cmd_action_latency_buffer = torch.zeros(self.num_envs, self.num_actions,
+ self.cfg.domain_rand.range_cmd_action_latency[1] + 1,
+ device=self.device)
+ self.obs_motor_latency_buffer = torch.zeros(self.num_envs, self.num_actions * 2,
+ self.cfg.domain_rand.range_obs_motor_latency[1] + 1,
+ device=self.device)
+ self.obs_imu_latency_buffer = torch.zeros(self.num_envs, 6, self.cfg.domain_rand.range_obs_imu_latency[1] + 1,
+ device=self.device)
+ self.cmd_action_latency_simstep = torch.zeros(self.num_envs, dtype=torch.long, device=self.device)
+ self.obs_motor_latency_simstep = torch.zeros(self.num_envs, dtype=torch.long, device=self.device)
+ self.obs_imu_latency_simstep = torch.zeros(self.num_envs, dtype=torch.long, device=self.device)
+
+ def _prepare_reward_function(self):
+ """ Prepares a list of reward functions, whcih will be called to compute the total reward.
+ Looks for self._reward_, where are names of all non zero reward scales in the cfg.
+ """
+ # remove zero scales + multiply non-zero ones by dt
+ for key in list(self.reward_scales.keys()):
+ scale = self.reward_scales[key]
+ if scale==0:
+ self.reward_scales.pop(key)
+ else:
+ self.reward_scales[key] *= self.dt
+ # prepare list of functions
+ self.reward_functions = []
+ self.reward_names = []
+ for name, scale in self.reward_scales.items():
+ if name=="termination":
+ continue
+ self.reward_names.append(name)
+ name = '_reward_' + name
+ self.reward_functions.append(getattr(self, name))
+
+ # reward episode sums
+ self.episode_sums = {name: torch.zeros(self.num_envs, dtype=torch.float, device=self.device, requires_grad=False)
+ for name in self.reward_scales.keys()}
+
+ def _create_ground_plane(self):
+ """ Adds a ground plane to the simulation, sets friction and restitution based on the cfg.
+ """
+ plane_params = gymapi.PlaneParams()
+ plane_params.normal = gymapi.Vec3(0.0, 0.0, 1.0)
+ plane_params.static_friction = self.cfg.terrain.static_friction
+ plane_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ plane_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_ground(self.sim, plane_params)
+
+ def _create_envs(self):
+ """ Creates environments:
+ 1. loads the robot URDF/MJCF asset,
+ 2. For each environment
+ 2.1 creates the environment,
+ 2.2 calls DOF and Rigid shape properties callbacks,
+ 2.3 create actor with these properties and add them to the env
+ 3. Store indices of different bodies of the robot
+ """
+ asset_path = self.cfg.asset.file.format(LEGGED_GYM_ROOT_DIR=LEGGED_GYM_ROOT_DIR)
+ asset_root = os.path.dirname(asset_path)
+ asset_file = os.path.basename(asset_path)
+
+ asset_options = gymapi.AssetOptions()
+ asset_options.default_dof_drive_mode = self.cfg.asset.default_dof_drive_mode
+ asset_options.collapse_fixed_joints = self.cfg.asset.collapse_fixed_joints
+ asset_options.replace_cylinder_with_capsule = self.cfg.asset.replace_cylinder_with_capsule
+ asset_options.flip_visual_attachments = self.cfg.asset.flip_visual_attachments
+ asset_options.fix_base_link = self.cfg.asset.fix_base_link
+ asset_options.density = self.cfg.asset.density
+ asset_options.angular_damping = self.cfg.asset.angular_damping
+ asset_options.linear_damping = self.cfg.asset.linear_damping
+ asset_options.max_angular_velocity = self.cfg.asset.max_angular_velocity
+ asset_options.max_linear_velocity = self.cfg.asset.max_linear_velocity
+ asset_options.armature = self.cfg.asset.armature
+ asset_options.thickness = self.cfg.asset.thickness
+ asset_options.disable_gravity = self.cfg.asset.disable_gravity
+
+ robot_asset = self.gym.load_asset(self.sim, asset_root, asset_file, asset_options)
+ self.num_dof = self.gym.get_asset_dof_count(robot_asset)
+ self.num_bodies = self.gym.get_asset_rigid_body_count(robot_asset)
+ dof_props_asset = self.gym.get_asset_dof_properties(robot_asset)
+ rigid_shape_props_asset = self.gym.get_asset_rigid_shape_properties(robot_asset)
+
+ # save body names from the asset
+ body_names = self.gym.get_asset_rigid_body_names(robot_asset)
+ self.dof_names = self.gym.get_asset_dof_names(robot_asset)
+
+ self.num_bodies = len(body_names)
+ self.num_dofs = len(self.dof_names)
+
+ feet_names = [s for s in body_names if self.cfg.asset.foot_name in s]
+ penalized_contact_names = []
+ for name in self.cfg.asset.penalize_contacts_on:
+ penalized_contact_names.extend([s for s in body_names if name in s])
+ termination_contact_names = []
+ for name in self.cfg.asset.terminate_after_contacts_on:
+ termination_contact_names.extend([s for s in body_names if name in s])
+
+ wheel_names = []
+ for name in self.cfg.asset.wheel_name:
+ wheel_names.extend([s for s in self.dof_names if name in s])
+
+ base_init_state_list = self.cfg.init_state.pos + self.cfg.init_state.rot + self.cfg.init_state.lin_vel + self.cfg.init_state.ang_vel
+ self.base_init_state = to_torch(base_init_state_list, device=self.device, requires_grad=False)
+ start_pose = gymapi.Transform()
+ start_pose.p = gymapi.Vec3(*self.base_init_state[:3])
+
+ self.joint_friction_coeffs = torch.ones(self.num_envs, 1, dtype=torch.float, device=self.device,
+ requires_grad=False)
+
+ self.joint_damping_coeffs = torch.ones(self.num_envs, 1, dtype=torch.float, device=self.device,
+ requires_grad=False)
+
+ self.joint_armatures = torch.zeros(self.num_envs, 1, dtype=torch.float, device=self.device, requires_grad=False)
+
+ self.torque_multiplier = torch.ones(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.motor_zero_offsets = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.p_gains_multiplier = torch.ones(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.d_gains_multiplier = torch.ones(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+
+ self._get_env_origins()
+ env_lower = gymapi.Vec3(0., 0., 0.)
+ env_upper = gymapi.Vec3(0., 0., 0.)
+ self.actor_handles = []
+ self.envs = []
+ self.env_frictions = torch.zeros(self.num_envs, 1, dtype=torch.float32, device=self.device)
+ self.body_mass = torch.zeros(self.num_envs, 1, dtype=torch.float32, device=self.device, requires_grad=False)
+
+ for i in range(self.num_envs):
+ # create env instance
+ env_handle = self.gym.create_env(self.sim, env_lower, env_upper, int(np.sqrt(self.num_envs)))
+ pos = self.env_origins[i].clone()
+ pos[:2] += torch_rand_float(-1., 1., (2,1), device=self.device).squeeze(1)
+ start_pose.p = gymapi.Vec3(*pos)
+
+ rigid_shape_props = self._process_rigid_shape_props(rigid_shape_props_asset, i)
+ self.gym.set_asset_rigid_shape_properties(robot_asset, rigid_shape_props)
+ actor_handle = self.gym.create_actor(env_handle, robot_asset, start_pose, self.cfg.asset.name, i, self.cfg.asset.self_collisions, 0)
+ dof_props = self._process_dof_props(dof_props_asset, i)
+ self.gym.set_actor_dof_properties(env_handle, actor_handle, dof_props)
+ body_props = self.gym.get_actor_rigid_body_properties(env_handle, actor_handle)
+ body_props = self._process_rigid_body_props(body_props, i)
+ self.gym.set_actor_rigid_body_properties(env_handle, actor_handle, body_props, recomputeInertia=True)
+ self.envs.append(env_handle)
+ self.actor_handles.append(actor_handle)
+
+ self.feet_indices = torch.zeros(len(feet_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(feet_names)):
+ self.feet_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0], feet_names[i])
+
+ self.penalised_contact_indices = torch.zeros(len(penalized_contact_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(penalized_contact_names)):
+ self.penalised_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0], penalized_contact_names[i])
+
+ self.termination_contact_indices = torch.zeros(len(termination_contact_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(termination_contact_names)):
+ self.termination_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0], termination_contact_names[i])
+
+ def _get_env_origins(self):
+ """ Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
+ Otherwise create a grid.
+ """
+
+ self.custom_origins = False
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # create a grid of robots
+ num_cols = np.floor(np.sqrt(self.num_envs))
+ num_rows = np.ceil(self.num_envs / num_cols)
+ xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
+ spacing = self.cfg.env.env_spacing
+ self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
+ self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
+ self.env_origins[:, 2] = 0.
+
+ def _parse_cfg(self, cfg):
+ self.dt = self.cfg.control.decimation * self.sim_params.dt
+ self.obs_scales = self.cfg.normalization.obs_scales
+ self.reward_scales = class_to_dict(self.cfg.rewards.scales)
+ self.command_ranges = class_to_dict(self.cfg.commands.ranges)
+
+
+ self.max_episode_length_s = self.cfg.env.episode_length_s
+ self.max_episode_length = np.ceil(self.max_episode_length_s / self.dt)
+
+ self.cfg.domain_rand.push_interval = np.ceil(self.cfg.domain_rand.push_interval_s / self.dt)
+
+ #------------ reward functions----------------
+ def _reward_lin_vel_z(self):
+ # Penalize z axis base linear velocity
+ return torch.square(self.base_lin_vel[:, 2])
+
+ def _reward_ang_vel_xy(self):
+ # Penalize xy axes base angular velocity
+ return torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1)
+
+ def _reward_orientation(self):
+ # Penalize non flat base orientation
+ return torch.sum(torch.square(self.projected_gravity[:, :2]), dim=1)
+
+ def _reward_base_height(self):
+ # Penalize base height away from target
+ base_height = self.root_states[:, 2]
+ return torch.square(base_height - self.cfg.rewards.base_height_target)
+
+ def _reward_torques(self):
+ # Penalize torques
+ return torch.sum(torch.square(self.torques), dim=1)
+
+ def _reward_dof_vel(self):
+ # Penalize dof velocities
+ return torch.sum(torch.square(self.dof_vel), dim=1)
+
+ def _reward_dof_acc(self):
+ # Penalize dof accelerations
+ return torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1)
+
+ def _reward_action_rate(self):
+ # Penalize changes in actions
+ return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
+
+ def _reward_collision(self):
+ # Penalize collisions on selected bodies
+ return torch.sum(1.*(torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1), dim=1)
+
+ def _reward_termination(self):
+ # Terminal reward / penalty
+ return self.reset_buf * ~self.time_out_buf
+
+ def _reward_dof_pos_limits(self):
+ # Penalize dof positions too close to the limit
+ out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) # lower limit
+ out_of_limits += (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.)
+ return torch.sum(out_of_limits, dim=1)
+
+ def _reward_dof_vel_limits(self):
+ # Penalize dof velocities too close to the limit
+ # clip to max error = 1 rad/s per joint to avoid huge penalties
+ return torch.sum((torch.abs(self.dof_vel) - self.dof_vel_limits*self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.), dim=1)
+
+ def _reward_torque_limits(self):
+ # penalize torques too close to the limit
+ return torch.sum((torch.abs(self.torques) - self.torque_limits*self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1)
+
+ def _reward_tracking_lin_vel(self):
+ # Tracking of linear velocity commands (xy axes)
+ lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
+ return torch.exp(-lin_vel_error/self.cfg.rewards.tracking_sigma)
+
+ def _reward_tracking_ang_vel(self):
+ # Tracking of angular velocity commands (yaw)
+ ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
+ return torch.exp(-ang_vel_error/self.cfg.rewards.tracking_sigma)
+
+ def _reward_feet_air_time(self):
+ # Reward long steps
+ # Need to filter the contacts because the contact reporting of PhysX is unreliable on meshes
+ contact = self.contact_forces[:, self.feet_indices, 2] > 1.
+ contact_filt = torch.logical_or(contact, self.last_contacts)
+ self.last_contacts = contact
+ first_contact = (self.feet_air_time > 0.) * contact_filt
+ self.feet_air_time += self.dt
+ rew_airTime = torch.sum((self.feet_air_time - 0.5) * first_contact, dim=1) # reward only on first contact with the ground
+ rew_airTime *= torch.norm(self.commands[:, :2], dim=1) > 0.1 #no reward for zero command
+ self.feet_air_time *= ~contact_filt
+ return rew_airTime
+
+ def _reward_stumble(self):
+ # Penalize feet hitting vertical surfaces
+ return torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) >\
+ 5 *torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1)
+
+ def _reward_stand_still(self):
+ # Penalize motion at zero commands
+ return torch.sum(torch.abs(self.dof_pos - self.default_dof_pos), dim=1) * (torch.norm(self.commands[:, :2], dim=1) < 0.1)
+
+ def _reward_feet_contact_forces(self):
+ # penalize high contact forces
+ return torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :], dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1)
diff --git a/legged_gym/envs/base/legged_robot_config.py b/legged_gym/envs/base/legged_robot_config.py
new file mode 100644
index 0000000..8486b68
--- /dev/null
+++ b/legged_gym/envs/base/legged_robot_config.py
@@ -0,0 +1,270 @@
+from .base_config import BaseConfig
+
+class LeggedRobotCfg(BaseConfig):
+ class env:
+ num_envs = 4096
+ num_observations = 54
+ num_privileged_obs = None # if not None a priviledge_obs_buf will be returned by step() (critic obs for assymetric training). None is returned otherwise
+ num_actions = 14
+ env_spacing = 3. # not used with heightfields/trimeshes
+ send_timeouts = True # send time out information to the algorithm
+ episode_length_s = 20 # episode length in seconds
+ test = False
+
+ class terrain:
+ mesh_type = 'plane' # "heightfield" # none, plane, heightfield or trimesh
+ horizontal_scale = 0.1 # [m]
+ vertical_scale = 0.005 # [m]
+ border_size = 25 # [m]
+ curriculum = True
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # rough terrain only:
+ measure_heights = True
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] # 1mx1.6m rectangle (without center line)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows= 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+ # terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
+ terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
+ # trimesh only:
+ slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces
+
+
+ class commands:
+ curriculum = True
+ max_curriculum = 1.
+ num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
+ resampling_time = 10. # time before command are changed[s]
+ heading_command = True # if true: compute ang vel command from heading error
+ class ranges:
+ lin_vel_x = [-1.0, 1.0] # min max [m/s]
+ lin_vel_y = [-1.0, 1.0] # min max [m/s]
+ ang_vel_yaw = [-1, 1] # min max [rad/s]
+ heading = [-3.14, 3.14]
+
+ # lin_vel_x = [0, 1.0] # min max [m/s]
+ # lin_vel_y = [0, 0] # min max [m/s]
+ # ang_vel_yaw = [0, 0] # min max [rad/s]
+ # heading = [0, 0]
+
+ class init_state:
+ pos = [0.0, 0.0, 1.] # x,y,z [m]
+ rot = [0.0, 0.0, 0.0, 1.0] # x,y,z,w [quat]
+ lin_vel = [0.0, 0.0, 0.0] # x,y,z [m/s]
+ ang_vel = [0.0, 0.0, 0.0] # x,y,z [rad/s]
+ default_joint_angles = { # target angles when action = 0.0
+ "joint_a": 0.,
+ "joint_b": 0.}
+
+ class control:
+ control_type = 'P' # P: position, V: velocity, T: torques
+ # PD Drive parameters:
+ stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
+ damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
+ # action scale: target angle = actionScale * action + defaultAngle
+ action_scale = 0.5
+ # decimation: Number of control action updates @ sim DT per policy DT
+ decimation = 4
+
+ class asset:
+ file = ""
+ name = "legged_robot" # actor name
+ foot_name = "None" # name of the feet bodies, used to index body state and contact force tensors
+ penalize_contacts_on = []
+ terminate_after_contacts_on = []
+ disable_gravity = False
+ collapse_fixed_joints = True # merge bodies connected by fixed joints. Specific fixed joints can be kept by adding " <... dont_collapse="true">
+ fix_base_link = False # fixe the base of the robot
+ default_dof_drive_mode = 3 # see GymDofDriveModeFlags (0 is none, 1 is pos tgt, 2 is vel tgt, 3 effort)
+ self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter
+ replace_cylinder_with_capsule = True # replace collision cylinders with capsules, leads to faster/more stable simulation
+ flip_visual_attachments = True # Some .obj meshes must be flipped from y-up to z-up
+
+ density = 0.001
+ angular_damping = 0.
+ linear_damping = 0.
+ max_angular_velocity = 1000.
+ max_linear_velocity = 1000.
+ armature = 0.
+ thickness = 0.01
+
+ class domain_rand:
+ randomize_friction = False
+ friction_range = [-0.2, 1.3]
+
+ push_robots = False
+ push_interval_s = 4
+ max_push_vel_xy = 0.4
+ max_push_ang_vel = 0.6
+
+ continuous_push = False
+ max_push_force = 0.5
+ max_push_torque = 0.5
+ push_force_noise = 0.5
+ push_torque_noise = 0.5
+
+ randomize_base_mass = False
+ added_base_mass_range = [-2.5, 2.5]
+
+ randomize_link_mass = False
+ multiplied_link_mass_range = [0.9, 1.1]
+
+ randomize_base_com = False
+ added_base_com_range = [-0.05, 0.05]
+
+ randomize_pd_gains = False
+ stiffness_multiplier_range = [0.8, 1.2]
+ damping_multiplier_range = [0.8, 1.2]
+
+ randomize_calculated_torque = False
+ torque_multiplier_range = [0.8, 1.2]
+
+ randomize_motor_zero_offset = False
+ motor_zero_offset_range = [-0.035, 0.035] # Offset to add to the motor angles
+
+ randomize_joint_friction = False
+ joint_friction_range = [0.01, 1.15]
+
+ randomize_joint_damping = False
+ joint_damping_range = [0.3, 1.5]
+
+ randomize_joint_armature = False
+ joint_armature_range = [0.0001, 0.05] # range to contain the real joint armature
+
+ add_obs_latency = False
+ randomize_obs_motor_latency = False
+ range_obs_motor_latency = [2, 10]
+ randomize_obs_imu_latency = False
+ range_obs_imu_latency = [1, 2]
+
+ add_cmd_action_latency = False
+ randomize_cmd_action_latency = False
+ range_cmd_action_latency = [2, 4]
+
+ randomize_imu_init = True
+ imu_init_yaw_range = [-1.57, 1.57]
+ imu_yaw_range = 0.5
+
+
+ class rewards:
+ class scales:
+ termination = -0.0
+ tracking_lin_vel = 1.0
+ tracking_ang_vel = 0.5
+ lin_vel_z = -2.0
+ ang_vel_xy = -0.05
+ orientation = -0.
+ torques = -0.00001
+ dof_vel = -0.
+ dof_acc = -2.5e-7
+ base_height = -0.
+ feet_air_time = 1.0
+ collision = -1.
+ feet_stumble = -0.0
+ action_rate = -0.01
+ stand_still = -0.
+
+ only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
+ tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
+ soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
+ soft_dof_vel_limit = 1.
+ soft_torque_limit = 1.
+ base_height_target = 1.
+ max_contact_force = 100. # forces above this value are penalized
+
+ class normalization:
+ class obs_scales:
+ lin_vel = 2.0
+ ang_vel = 0.25
+ dof_pos = 1.0
+ dof_vel = 0.05
+ height_measurements = 5.0
+ clip_observations = 100.
+ clip_actions = 100.
+
+ class noise:
+ add_noise = True
+ noise_level = 1.0 # scales other values
+ class noise_scales:
+ dof_pos = 0.01
+ dof_vel = 1.5
+ lin_vel = 0.1
+ ang_vel = 0.2
+ gravity = 0.05
+ height_measurements = 0.1
+
+ # viewer camera:
+ class viewer:
+ ref_env = 0
+ pos = [10, 0, 6] # [m]
+ lookat = [11., 5, 3.] # [m]
+
+ class sim:
+ dt = 0.005
+ substeps = 1
+ gravity = [0., 0. ,-9.81] # [m/s^2]
+ up_axis = 1 # 0 is y, 1 is z
+
+ class physx:
+ num_threads = 10
+ solver_type = 1 # 0: pgs, 1: tgs
+ num_position_iterations = 4
+ num_velocity_iterations = 0
+ contact_offset = 0.01 # [m]
+ rest_offset = 0.0 # [m]
+ bounce_threshold_velocity = 0.5 #0.5 [m/s]
+ max_depenetration_velocity = 1.0
+ max_gpu_contact_pairs = 2**23 #2**24 -> needed for 8000 envs and more
+ default_buffer_size_multiplier = 5
+ contact_collection = 2 # 0: never, 1: last sub-step, 2: all sub-steps (default=2)
+
+class LeggedRobotCfgPPO(BaseConfig):
+ seed = 1
+ runner_class_name = 'OnPolicyRunner'
+ class policy:
+ init_noise_std = 1.0
+ actor_hidden_dims = [512, 256, 128]
+ critic_hidden_dims = [512, 256, 128]
+ activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
+ # only for 'ActorCriticRecurrent':
+ # rnn_type = 'lstm'
+ # rnn_hidden_size = 512
+ # rnn_num_layers = 1
+
+ class algorithm:
+ # training params
+ value_loss_coef = 1.0
+ use_clipped_value_loss = True
+ clip_param = 0.2
+ entropy_coef = 0.01
+ num_learning_epochs = 5
+ num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
+ learning_rate = 1.e-3 #5.e-4
+ schedule = 'adaptive' # could be adaptive, fixed
+ gamma = 0.99
+ lam = 0.95
+ desired_kl = 0.01
+ max_grad_norm = 1.
+
+ class runner:
+ policy_class_name = 'ActorCritic'
+ algorithm_class_name = 'PPO'
+ num_steps_per_env = 24 # per iteration
+ max_iterations = 1500 # number of policy updates
+
+ # logging
+ save_interval = 50 # check for potential saves every this many iterations
+ experiment_name = 'test'
+ run_name = ''
+ # load and resume
+ resume = False
+ load_run = -1 # -1 = last run
+ checkpoint = -1 # -1 = last saved model
+ resume_path = None # updated from load_run and chkpt
\ No newline at end of file
diff --git a/legged_gym/envs/base/legged_robot_config_fh.py b/legged_gym/envs/base/legged_robot_config_fh.py
new file mode 100644
index 0000000..689c2ee
--- /dev/null
+++ b/legged_gym/envs/base/legged_robot_config_fh.py
@@ -0,0 +1,223 @@
+from .base_config import BaseConfig
+
+class LeggedRobotCfg_FH(BaseConfig):
+ class env:
+ num_envs = 4096
+ num_observations = 235
+ num_privileged_obs = None # if not None a priviledge_obs_buf will be returned by step() (critic obs for assymetric training). None is returned otherwise
+ num_actions = 12
+ env_spacing = 3. # not used with heightfields/trimeshes
+ send_timeouts = True # send time out information to the algorithm
+ episode_length_s = 20 # episode length in seconds
+
+ class terrain:
+ mesh_type = 'trimesh' # "heightfield" # none, plane, heightfield or trimesh
+ horizontal_scale = 0.1 # [m]
+ vertical_scale = 0.005 # [m]
+ border_size = 25 # [m]
+ curriculum = True
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # rough terrain only:
+ measure_heights = True
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
+ 0.8] # 1mx1.6m rectangle (without center line)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows = 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+ # terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
+ terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
+ # trimesh only:
+ slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces
+
+ class commands:
+ curriculum = False
+ max_curriculum = 1.
+ num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
+ resampling_time = 10. # time before command are changed[s]
+ heading_command = True # if true: compute ang vel command from heading error
+
+ class ranges:
+ lin_vel_x = [-1.0, 1.0] # min max [m/s]
+ lin_vel_y = [-1.0, 1.0] # min max [m/s]
+ ang_vel_yaw = [-1, 1] # min max [rad/s]
+ heading = [-3.14, 3.14]
+
+ class init_state:
+ pos = [0.0, 0.0, 1.] # x,y,z [m]
+ rot = [0.0, 0.0, 0.0, 1.0] # x,y,z,w [quat]
+ lin_vel = [0.0, 0.0, 0.0] # x,y,z [m/s]
+ ang_vel = [0.0, 0.0, 0.0] # x,y,z [rad/s]
+ default_joint_angles = { # target angles when action = 0.0
+ "joint_a": 0.,
+ "joint_b": 0.}
+
+ class control:
+ control_type = 'P' # P: position, V: velocity, T: torques
+ # PD Drive parameters:
+ stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
+ damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
+ # action scale: target angle = actionScale * action + defaultAngle
+ action_scale = 0.5
+ # decimation: Number of control action updates @ sim DT per policy DT
+ decimation = 4
+ wheel_speed = 1
+ arm_pos = 0
+
+ class asset:
+ file = ""
+ name = "legged_robot" # actor name
+ arm_name = ""
+ foot_name = "None" # name of the feet bodies, used to index body state and contact force tensors
+ penalize_contacts_on = []
+ terminate_after_contacts_on = []
+ disable_gravity = False
+ collapse_fixed_joints = True # merge bodies connected by fixed joints. Specific fixed joints can be kept by adding " <... dont_collapse="true">
+ fix_base_link = False # fixe the base of the robot
+ default_dof_drive_mode = 3 # see GymDofDriveModeFlags (0 is none, 1 is pos tgt, 2 is vel tgt, 3 effort)
+ self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter
+ replace_cylinder_with_capsule = True # replace collision cylinders with capsules, leads to faster/more stable simulation
+ flip_visual_attachments = False # Some .obj meshes must be flipped from y-up to z-up
+
+ density = 0.001
+ angular_damping = 0.
+ linear_damping = 0.
+ max_angular_velocity = 1000.
+ max_linear_velocity = 1000.
+ armature = 0.
+ thickness = 0.01
+
+ class domain_rand:
+ randomize_friction = True
+ friction_range = [0.5, 1.25]
+ randomize_base_mass = False
+ added_mass_range = [-1., 1.]
+ push_robots = True
+ push_interval_s = 15
+ max_push_vel_xy = 1.
+
+ class rewards:
+ class scales:
+ termination = -0.0
+ tracking_lin_vel = 1.0
+ tracking_ang_vel = 0.5
+ lin_vel_z = -2.0
+ ang_vel_xy = -0.05
+ orientation = -0.
+ torques = -0.00001
+ dof_vel = -0.
+ dof_acc = -2.5e-7
+ base_height = -0.
+ feet_air_time = 1.0
+ collision = -1.
+ feet_stumble = -0.0
+ action_rate = -0.01
+ stand_still = -0.
+
+ only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
+ tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
+ soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
+ soft_dof_vel_limit = 1.
+ soft_torque_limit = 1.
+ base_height_target = 1.
+ max_contact_force = 100. # forces above this value are penalized
+
+ class normalization:
+ class obs_scales:
+ lin_vel = 2.0
+ ang_vel = 0.25
+ dof_pos = 1.0
+ dof_vel = 0.05
+ height_measurements = 5.0
+
+ clip_observations = 100.
+ clip_actions = 100.
+
+ class noise:
+ add_noise = True
+ noise_level = 1.0 # scales other values
+
+ class noise_scales:
+ dof_pos = 0.01
+ dof_vel = 1.5
+ lin_vel = 0.1
+ ang_vel = 0.2
+ gravity = 0.05
+ height_measurements = 0.1
+
+ # viewer camera:
+ class viewer:
+ ref_env = 0
+ pos = [10, 0, 6] # [m]
+ lookat = [11., 5, 3.] # [m]
+
+ class sim:
+ dt = 0.005
+ substeps = 1
+ gravity = [0., 0., -9.81] # [m/s^2]
+ up_axis = 1 # 0 is y, 1 is z
+
+ class physx:
+ num_threads = 10
+ solver_type = 1 # 0: pgs, 1: tgs
+ num_position_iterations = 4
+ num_velocity_iterations = 0
+ contact_offset = 0.01 # [m]
+ rest_offset = 0.0 # [m]
+ bounce_threshold_velocity = 0.5 # 0.5 [m/s]
+ max_depenetration_velocity = 1.0
+ max_gpu_contact_pairs = 2 ** 23 # 2**24 -> needed for 8000 envs and more
+ default_buffer_size_multiplier = 5
+ contact_collection = 2 # 0: never, 1: last sub-step, 2: all sub-steps (default=2)
+
+
+class LeggedRobotCfgPPO_FH(BaseConfig):
+ seed = 1
+ runner_class_name = 'OnPolicyRunner'
+
+ class policy:
+ init_noise_std = 1.0
+ actor_hidden_dims = [512, 256, 128]
+ critic_hidden_dims = [512, 256, 128]
+ activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
+ # only for 'ActorCriticRecurrent':
+ # rnn_type = 'lstm'
+ # rnn_hidden_size = 512
+ # rnn_num_layers = 1
+
+ class algorithm:
+ # training params
+ value_loss_coef = 1.0
+ use_clipped_value_loss = True
+ clip_param = 0.2
+ entropy_coef = 0.01
+ num_learning_epochs = 5
+ num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
+ learning_rate = 1.e-3 # 5.e-4
+ schedule = 'adaptive' # could be adaptive, fixed
+ gamma = 0.99
+ lam = 0.95
+ desired_kl = 0.01
+ max_grad_norm = 1.
+
+ class runner:
+ policy_class_name = 'ActorCritic'
+ algorithm_class_name = 'PPO'
+ num_steps_per_env = 24 # per iteration
+ max_iterations = 1500 # number of policy updates
+
+ # logging
+ save_interval = 50 # check for potential saves every this many iterations
+ experiment_name = 'test'
+ run_name = ''
+ # load and resume
+ resume = False
+ load_run = -1 # -1 = last run
+ checkpoint = -1 # -1 = last saved model
+ resume_path = None # updated from load_run and chkpt
\ No newline at end of file
diff --git a/legged_gym/envs/base/legged_robot_fh.py b/legged_gym/envs/base/legged_robot_fh.py
new file mode 100644
index 0000000..b28fe89
--- /dev/null
+++ b/legged_gym/envs/base/legged_robot_fh.py
@@ -0,0 +1,937 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, envs
+import time
+from warnings import WarningMessage
+import numpy as np
+import os
+
+from isaacgym.torch_utils import *
+from isaacgym import gymtorch, gymapi, gymutil
+
+import torch
+from torch import Tensor
+from typing import Tuple, Dict
+
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from legged_gym.envs.base.base_task import BaseTask
+from legged_gym.utils.terrain import Terrain
+from legged_gym.utils.math import quat_apply_yaw, wrap_to_pi, torch_rand_sqrt_float
+from legged_gym.utils.isaacgym_utils import get_euler_xyz as get_euler_xyz_in_tensor
+from legged_gym.utils.helpers import class_to_dict
+from .legged_robot_config_fh import LeggedRobotCfg_FH
+
+class LeggedRobot_FH(BaseTask):
+ def __init__(self, cfg: LeggedRobotCfg_FH, sim_params, physics_engine, sim_device, headless):
+ """ Parses the provided config file,
+ calls create_sim() (which creates, simulation, terrain and environments),
+ initilizes pytorch buffers used during training
+
+ Args:
+ cfg (Dict): Environment config file
+ sim_params (gymapi.SimParams): simulation parameters
+ physics_engine (gymapi.SimType): gymapi.SIM_PHYSX (must be PhysX)
+ device_type (string): 'cuda' or 'cpu'
+ device_id (int): 0, 1, ...
+ headless (bool): Run without rendering if True
+ """
+ self.cfg = cfg
+ self.sim_params = sim_params
+ self.height_samples = None
+ self.debug_viz = False
+ self.init_done = False
+ self._parse_cfg(self.cfg)
+ super().__init__(self.cfg, sim_params, physics_engine, sim_device, headless)
+
+ if not self.headless:
+ self.set_camera(self.cfg.viewer.pos, self.cfg.viewer.lookat)
+ self._init_buffers()
+ self._prepare_reward_function()
+ self.init_done = True
+
+ def step(self, actions):
+ """ Apply actions, simulate, call self.post_physics_step()
+
+ Args:
+ actions (torch.Tensor): Tensor of shape (num_envs, num_actions_per_env)
+ """
+ clip_actions = self.cfg.normalization.clip_actions
+ self.actions = torch.clip(actions, -clip_actions, clip_actions).to(self.device)
+ # step physics and render each frame
+ self.render()
+ for _ in range(self.cfg.control.decimation):
+ self.torques = self._compute_torques(self.actions).view(self.torques.shape)
+ self.gym.set_dof_actuation_force_tensor(self.sim, gymtorch.unwrap_tensor(self.torques))
+ self.gym.simulate(self.sim)
+ if self.device == 'cpu':
+ self.gym.fetch_results(self.sim, True)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.post_physics_step()
+
+ # return clipped obs, clipped states (None), rewards, dones and infos
+ clip_obs = self.cfg.normalization.clip_observations
+ self.obs_buf = torch.clip(self.obs_buf, -clip_obs, clip_obs)
+ if self.privileged_obs_buf is not None:
+ self.privileged_obs_buf = torch.clip(self.privileged_obs_buf, -clip_obs, clip_obs)
+ return self.obs_buf, self.privileged_obs_buf, self.rew_buf, self.reset_buf, self.extras
+
+ def post_physics_step(self):
+ """ check terminations, compute observations and rewards
+ calls self._post_physics_step_callback() for common computations
+ calls self._draw_debug_vis() if needed
+ """
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ self.episode_length_buf += 1
+ self.common_step_counter += 1
+
+ # prepare quantities
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.base_lin_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+
+ self._post_physics_step_callback()
+
+ # compute observations, rewards, resets, ...
+ self.check_termination()
+ self.compute_reward()
+ env_ids = self.reset_buf.nonzero(as_tuple=False).flatten()
+ self.reset_idx(env_ids)
+ self.compute_observations() # in some cases a simulation step might be required to refresh some obs (for example body positions)
+
+ self.last_actions[:] = self.actions[:]
+ self.last_dof_vel[:] = self.dof_vel[:]
+ self.last_root_vel[:] = self.root_states[:, 7:13]
+
+ if self.viewer and self.enable_viewer_sync and self.debug_viz:
+ self._draw_debug_vis()
+
+ def check_termination(self):
+ """ Check if environments need to be reset
+ """
+ self.reset_buf = torch.any(torch.norm(self.contact_forces[:, self.termination_contact_indices, :], dim=-1) > 1.,
+ dim=1)
+ self.time_out_buf = self.episode_length_buf > self.max_episode_length # no terminal reward for time-outs
+ self.reset_buf |= self.time_out_buf
+
+ def reset_idx(self, env_ids):
+ """ Reset some environments.
+ Calls self._reset_dofs(env_ids), self._reset_root_states(env_ids), and self._resample_commands(env_ids)
+ [Optional] calls self._update_terrain_curriculum(env_ids), self.update_command_curriculum(env_ids) and
+ Logs episode info
+ Resets some buffers
+
+ Args:
+ env_ids (list[int]): List of environment ids which must be reset
+ """
+ if len(env_ids) == 0:
+ return
+ # update curriculum
+ if self.cfg.terrain.curriculum:
+ self._update_terrain_curriculum(env_ids)
+ # avoid updating command curriculum at each step since the maximum command is common to all envs
+ if self.cfg.commands.curriculum and (self.common_step_counter % self.max_episode_length == 0):
+ self.update_command_curriculum(env_ids)
+
+ # reset robot states
+ self._reset_dofs(env_ids)
+ self._reset_root_states(env_ids)
+
+ self._resample_commands(env_ids)
+
+ # reset buffers
+ self.last_actions[env_ids] = 0.
+ self.last_dof_vel[env_ids] = 0.
+ self.feet_air_time[env_ids] = 0.
+ self.episode_length_buf[env_ids] = 0
+ self.reset_buf[env_ids] = 1
+ # fill extras
+ self.extras["episode"] = {}
+ for key in self.episode_sums.keys():
+ self.extras["episode"]['rew_' + key] = torch.mean(
+ self.episode_sums[key][env_ids]) / self.max_episode_length_s
+ self.episode_sums[key][env_ids] = 0.
+ # log additional curriculum info
+ if self.cfg.terrain.curriculum:
+ self.extras["episode"]["terrain_level"] = torch.mean(self.terrain_levels.float())
+ if self.cfg.commands.curriculum:
+ self.extras["episode"]["max_command_x"] = self.command_ranges["lin_vel_x"][1]
+ # send timeout info to the algorithm
+ if self.cfg.env.send_timeouts:
+ self.extras["time_outs"] = self.time_out_buf
+
+ def compute_reward(self):
+ """ Compute rewards
+ Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
+ adds each terms to the episode sums and to the total reward
+ """
+ self.rew_buf[:] = 0.
+ for i in range(len(self.reward_functions)):
+ name = self.reward_names[i]
+ rew = self.reward_functions[i]() * self.reward_scales[name]
+ self.rew_buf += rew
+ self.episode_sums[name] += rew
+ if self.cfg.rewards.only_positive_rewards:
+ self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
+ # add termination reward after clipping
+ if "termination" in self.reward_scales:
+ rew = self._reward_termination() * self.reward_scales["termination"]
+ self.rew_buf += rew
+ self.episode_sums["termination"] += rew
+
+ def compute_observations(self):
+ """ Computes observations
+ """
+ self.obs_buf = torch.cat((self.base_lin_vel * self.obs_scales.lin_vel,
+ self.base_ang_vel * self.obs_scales.ang_vel,
+ self.projected_gravity,
+ self.commands[:, :3] * self.commands_scale,
+ (self.dof_pos - self.default_dof_pos) * self.obs_scales.dof_pos,
+ self.dof_vel * self.obs_scales.dof_vel,
+ self.actions
+ ), dim=-1)
+ # add perceptive inputs if not blind
+ if self.cfg.terrain.measure_heights:
+ heights = torch.clip(self.root_states[:, 2].unsqueeze(1) - 0.5 - self.measured_heights, -1,
+ 1.) * self.obs_scales.height_measurements
+ self.obs_buf = torch.cat((self.obs_buf, heights), dim=-1)
+ # add noise if needed
+ if self.add_noise:
+ self.obs_buf += (2 * torch.rand_like(self.obs_buf) - 1) * self.noise_scale_vec
+
+ def create_sim(self):
+ """ Creates simulation, terrain and evironments
+ """
+ self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
+ self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine,
+ self.sim_params)
+ mesh_type = self.cfg.terrain.mesh_type
+ if mesh_type in ['heightfield', 'trimesh']:
+ self.terrain = Terrain(self.cfg.terrain, self.num_envs)
+ if mesh_type == 'plane':
+ self._create_ground_plane()
+ elif mesh_type == 'heightfield':
+ self._create_heightfield()
+ elif mesh_type == 'trimesh':
+ self._create_trimesh()
+ elif mesh_type is not None:
+ raise ValueError("Terrain mesh type not recognised. Allowed types are [None, plane, heightfield, trimesh]")
+ self._create_envs()
+
+ def set_camera(self, position, lookat):
+ """ Set camera position and direction
+ """
+ cam_pos = gymapi.Vec3(position[0], position[1], position[2])
+ cam_target = gymapi.Vec3(lookat[0], lookat[1], lookat[2])
+ self.gym.viewer_camera_look_at(self.viewer, None, cam_pos, cam_target)
+
+ # ------------- Callbacks --------------
+ def _process_rigid_shape_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the rigid shape properties of each environment.
+ Called During environment creation.
+ Base behavior: randomizes the friction of each environment
+
+ Args:
+ props (List[gymapi.RigidShapeProperties]): Properties of each shape of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [List[gymapi.RigidShapeProperties]]: Modified rigid shape properties
+ """
+ if self.cfg.domain_rand.randomize_friction:
+ if env_id == 0:
+ # prepare friction randomization
+ friction_range = self.cfg.domain_rand.friction_range
+ num_buckets = 64
+ bucket_ids = torch.randint(0, num_buckets, (self.num_envs, 1))
+ friction_buckets = torch_rand_float(friction_range[0], friction_range[1], (num_buckets, 1),
+ device='cpu')
+ self.friction_coeffs = friction_buckets[bucket_ids]
+
+ for s in range(len(props)):
+ props[s].friction = self.friction_coeffs[env_id]
+ return props
+
+ def _process_dof_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the DOF properties of each environment.
+ Called During environment creation.
+ Base behavior: stores position, velocity and torques limits defined in the URDF
+
+ Args:
+ props (numpy.array): Properties of each DOF of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [numpy.array]: Modified DOF properties
+ """
+ if env_id == 0:
+ self.dof_pos_limits = torch.zeros(self.num_dof, 2, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.dof_vel_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.torque_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(len(props)):
+ self.dof_pos_limits[i, 0] = props["lower"][i].item()
+ self.dof_pos_limits[i, 1] = props["upper"][i].item()
+ self.dof_vel_limits[i] = props["velocity"][i].item()
+ self.torque_limits[i] = props["effort"][i].item()
+ # soft limits
+ m = (self.dof_pos_limits[i, 0] + self.dof_pos_limits[i, 1]) / 2
+ r = self.dof_pos_limits[i, 1] - self.dof_pos_limits[i, 0]
+ self.dof_pos_limits[i, 0] = m - 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ self.dof_pos_limits[i, 1] = m + 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ return props
+
+ def _process_rigid_body_props(self, props, env_id):
+ # if env_id==0:
+ # sum = 0
+ # for i, p in enumerate(props):
+ # sum += p.mass
+ # print(f"Mass of body {i}: {p.mass} (before randomization)")
+ # print(f"Total mass {sum} (before randomization)")
+ # randomize base mass
+ if self.cfg.domain_rand.randomize_base_mass:
+ rng = self.cfg.domain_rand.added_mass_range
+ props[0].mass += np.random.uniform(rng[0], rng[1])
+ return props
+
+ def _post_physics_step_callback(self):
+ """ Callback called before computing terminations, rewards, and observations
+ Default behaviour: Compute ang vel command based on target and heading, compute measured terrain heights and randomly push robots
+ """
+ #
+ env_ids = (self.episode_length_buf % int(self.cfg.commands.resampling_time / self.dt) == 0).nonzero(
+ as_tuple=False).flatten()
+ self._resample_commands(env_ids)
+ if self.cfg.commands.heading_command:
+ forward = quat_apply(self.base_quat, self.forward_vec)
+ heading = torch.atan2(forward[:, 1], forward[:, 0])
+ self.commands[:, 2] = torch.clip(0.5 * wrap_to_pi(self.commands[:, 3] - heading), -1., 1.)
+
+ if self.cfg.terrain.measure_heights:
+ self.measured_heights = self._get_heights()
+ if self.cfg.domain_rand.push_robots and (self.common_step_counter % self.cfg.domain_rand.push_interval == 0):
+ self._push_robots()
+
+ def _resample_commands(self, env_ids):
+ """ Randommly select commands of some environments
+
+ Args:
+ env_ids (List[int]): Environments ids for which new commands are needed
+ """
+ self.commands[env_ids, 0] = torch_rand_float(self.command_ranges["lin_vel_x"][0],
+ self.command_ranges["lin_vel_x"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ self.commands[env_ids, 1] = torch_rand_float(self.command_ranges["lin_vel_y"][0],
+ self.command_ranges["lin_vel_y"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ if self.cfg.commands.heading_command:
+ self.commands[env_ids, 3] = torch_rand_float(self.command_ranges["heading"][0],
+ self.command_ranges["heading"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ else:
+ self.commands[env_ids, 2] = torch_rand_float(self.command_ranges["ang_vel_yaw"][0],
+ self.command_ranges["ang_vel_yaw"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+
+ # set small commands to zero
+ self.commands[env_ids, :2] *= (torch.norm(self.commands[env_ids, :2], dim=1) > 0.2).unsqueeze(1)
+
+ def _compute_torques(self, actions):
+ """ Compute torques from actions.
+ Actions can be interpreted as position or velocity targets given to a PD controller, or directly as scaled torques.
+ [NOTE]: torques must have the same dimension as the number of DOFs, even if some DOFs are not actuated.
+
+ Args:
+ actions (torch.Tensor): Actions
+
+ Returns:
+ [torch.Tensor]: Torques sent to the simulation
+ """
+ # pd controller
+ actions_scaled = actions * self.cfg.control.action_scale
+ control_type = self.cfg.control.control_type
+ if control_type == "P":
+ torques = self.p_gains * (
+ actions_scaled + self.default_dof_pos - self.dof_pos) - self.d_gains * self.dof_vel
+ elif control_type == "V":
+ torques = self.p_gains * (actions_scaled - self.dof_vel) - self.d_gains * (
+ self.dof_vel - self.last_dof_vel) / self.sim_params.dt
+ elif control_type == "T":
+ torques = actions_scaled
+ else:
+ raise NameError(f"Unknown controller type: {control_type}")
+ return torch.clip(torques, -self.torque_limits, self.torque_limits)
+
+ def _reset_dofs(self, env_ids):
+ """ Resets DOF position and velocities of selected environmments
+ Positions are randomly selected within 0.5:1.5 x default positions.
+ Velocities are set to zero.
+
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ self.dof_pos[env_ids] = self.default_dof_pos * torch_rand_float(0.5, 1.5, (len(env_ids), self.num_dof),
+ device=self.device)
+ self.dof_vel[env_ids] = 0.
+
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_dof_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.dof_state),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _reset_root_states(self, env_ids):
+ """ Resets ROOT states position and velocities of selected environmments
+ Sets base position based on the curriculum
+ Selects randomized base velocities within -0.5:0.5 [m/s, rad/s]
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ # base position
+ if self.custom_origins:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ self.root_states[env_ids, :2] += torch_rand_float(-1., 1., (len(env_ids), 2),
+ device=self.device) # xy position within 1m of the center
+ else:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ # base velocities
+ self.root_states[env_ids, 7:13] = torch_rand_float(-0.5, 0.5, (len(env_ids), 6),
+ device=self.device) # [7:10]: lin vel, [10:13]: ang vel
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _push_robots(self):
+ """ Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
+ """
+ max_vel = self.cfg.domain_rand.max_push_vel_xy
+ self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2),
+ device=self.device) # lin vel x/y
+ self.gym.set_actor_root_state_tensor(self.sim, gymtorch.unwrap_tensor(self.root_states))
+
+ def _update_terrain_curriculum(self, env_ids):
+ """ Implements the game-inspired curriculum.
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # Implement Terrain curriculum
+ if not self.init_done:
+ # don't change on initial reset
+ return
+ distance = torch.norm(self.root_states[env_ids, :2] - self.env_origins[env_ids, :2], dim=1)
+ # robots that walked far enough progress to harder terains
+ move_up = distance > self.terrain.env_length / 2
+ # robots that walked less than half of their required distance go to simpler terrains
+ move_down = (distance < torch.norm(self.commands[env_ids, :2],
+ dim=1) * self.max_episode_length_s * 0.5) * ~move_up
+ self.terrain_levels[env_ids] += 1 * move_up - 1 * move_down
+ # Robots that solve the last level are sent to a random one
+ self.terrain_levels[env_ids] = torch.where(self.terrain_levels[env_ids] >= self.max_terrain_level,
+ torch.randint_like(self.terrain_levels[env_ids],
+ self.max_terrain_level),
+ torch.clip(self.terrain_levels[env_ids],
+ 0)) # (the minumum level is zero)
+ self.env_origins[env_ids] = self.terrain_origins[self.terrain_levels[env_ids], self.terrain_types[env_ids]]
+
+ def update_command_curriculum(self, env_ids):
+ """ Implements a curriculum of increasing commands
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # If the tracking reward is above 80% of the maximum, increase the range of commands
+ if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * \
+ self.reward_scales["tracking_lin_vel"]:
+ self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5,
+ -self.cfg.commands.max_curriculum, 0.)
+ self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0.,
+ self.cfg.commands.max_curriculum)
+
+ def _get_noise_scale_vec(self, cfg):
+ """ Sets a vector used to scale the noise added to the observations.
+ [NOTE]: Must be adapted when changing the observations structure
+
+ Args:
+ cfg (Dict): Environment config file
+
+ Returns:
+ [torch.Tensor]: Vector of scales used to multiply a uniform distribution in [-1, 1]
+ """
+ noise_vec = torch.zeros_like(self.obs_buf[0])
+ self.add_noise = self.cfg.noise.add_noise
+ noise_scales = self.cfg.noise.noise_scales
+ noise_level = self.cfg.noise.noise_level
+ noise_vec[:3] = noise_scales.lin_vel * noise_level * self.obs_scales.lin_vel
+ noise_vec[3:6] = noise_scales.ang_vel * noise_level * self.obs_scales.ang_vel
+ noise_vec[6:9] = noise_scales.gravity * noise_level
+ noise_vec[9:12] = 0. # commands
+ noise_vec[12:24] = noise_scales.dof_pos * noise_level * self.obs_scales.dof_pos
+ noise_vec[24:36] = noise_scales.dof_vel * noise_level * self.obs_scales.dof_vel
+ noise_vec[36:48] = 0. # previous actions
+ if self.cfg.terrain.measure_heights:
+ noise_vec[48:235] = noise_scales.height_measurements * noise_level * self.obs_scales.height_measurements
+ return noise_vec
+
+ # ----------------------------------------
+ def _init_buffers(self):
+ """ Initialize torch tensors which will contain simulation states and processed quantities
+ """
+ # get gym GPU state tensors
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ # create some wrapper tensors for different slices
+ self.root_states = gymtorch.wrap_tensor(actor_root_state)
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1,
+ 3) # shape: num_envs, num_bodies, xyz axis
+
+ # initialize some data used later on
+ self.common_step_counter = 0
+ self.extras = {}
+ self.noise_scale_vec = self._get_noise_scale_vec(self.cfg)
+ self.gravity_vec = to_torch(get_axis_params(-1., self.up_axis_idx), device=self.device).repeat(
+ (self.num_envs, 1))
+ self.forward_vec = to_torch([1., 0., 0.], device=self.device).repeat((self.num_envs, 1))
+ self.torques = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_dof_vel = torch.zeros_like(self.dof_vel)
+ self.last_root_vel = torch.zeros_like(self.root_states[:, 7:13])
+ self.commands = torch.zeros(self.num_envs, self.cfg.commands.num_commands, dtype=torch.float,
+ device=self.device, requires_grad=False) # x vel, y vel, yaw vel, heading
+ self.commands_scale = torch.tensor([self.obs_scales.lin_vel, self.obs_scales.lin_vel, self.obs_scales.ang_vel],
+ device=self.device, requires_grad=False, ) # TODO change this
+ self.feet_air_time = torch.zeros(self.num_envs, self.feet_indices.shape[0], dtype=torch.float,
+ device=self.device, requires_grad=False)
+ self.last_contacts = torch.zeros(self.num_envs, len(self.feet_indices), dtype=torch.bool, device=self.device,
+ requires_grad=False)
+ self.base_lin_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ if self.cfg.terrain.measure_heights:
+ self.height_points = self._init_height_points()
+ self.measured_heights = 0
+
+ # joint positions offsets and PD gains
+ self.default_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(self.num_dofs):
+ name = self.dof_names[i]
+ angle = self.cfg.init_state.default_joint_angles[name]
+ self.default_dof_pos[i] = angle
+ found = False
+ for dof_name in self.cfg.control.stiffness.keys():
+ if dof_name in name:
+ self.p_gains[i] = self.cfg.control.stiffness[dof_name]
+ self.d_gains[i] = self.cfg.control.damping[dof_name]
+ found = True
+ if not found:
+ self.p_gains[i] = 0.
+ self.d_gains[i] = 0.
+ if self.cfg.control.control_type in ["P", "V"]:
+ print(f"PD gain of joint {name} were not defined, setting them to zero")
+ self.default_dof_pos = self.default_dof_pos.unsqueeze(0)
+
+ def _prepare_reward_function(self):
+ """ Prepares a list of reward functions, whcih will be called to compute the total reward.
+ Looks for self._reward_, where are names of all non zero reward scales in the cfg.
+ """
+ # remove zero scales + multiply non-zero ones by dt
+ for key in list(self.reward_scales.keys()):
+ scale = self.reward_scales[key]
+ if scale == 0:
+ self.reward_scales.pop(key)
+ else:
+ self.reward_scales[key] *= self.dt
+ # prepare list of functions
+ self.reward_functions = []
+ self.reward_names = []
+ for name, scale in self.reward_scales.items():
+ if name == "termination":
+ continue
+ self.reward_names.append(name)
+ name = '_reward_' + name
+ self.reward_functions.append(getattr(self, name))
+
+ # reward episode sums
+ self.episode_sums = {
+ name: torch.zeros(self.num_envs, dtype=torch.float, device=self.device, requires_grad=False)
+ for name in self.reward_scales.keys()}
+
+ def _create_ground_plane(self):
+ """ Adds a ground plane to the simulation, sets friction and restitution based on the cfg.
+ """
+ plane_params = gymapi.PlaneParams()
+ plane_params.normal = gymapi.Vec3(0.0, 0.0, 1.0)
+ plane_params.static_friction = self.cfg.terrain.static_friction
+ plane_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ plane_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_ground(self.sim, plane_params)
+
+ def _create_heightfield(self):
+ """ Adds a heightfield terrain to the simulation, sets parameters based on the cfg.
+ """
+ hf_params = gymapi.HeightFieldParams()
+ hf_params.column_scale = self.terrain.cfg.horizontal_scale
+ hf_params.row_scale = self.terrain.cfg.horizontal_scale
+ hf_params.vertical_scale = self.terrain.cfg.vertical_scale
+ hf_params.nbRows = self.terrain.tot_cols
+ hf_params.nbColumns = self.terrain.tot_rows
+ hf_params.transform.p.x = -self.terrain.cfg.border_size
+ hf_params.transform.p.y = -self.terrain.cfg.border_size
+ hf_params.transform.p.z = 0.0
+ hf_params.static_friction = self.cfg.terrain.static_friction
+ hf_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ hf_params.restitution = self.cfg.terrain.restitution
+
+ self.gym.add_heightfield(self.sim, self.terrain.heightsamples, hf_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_trimesh(self):
+ """ Adds a triangle mesh terrain to the simulation, sets parameters based on the cfg.
+ # """
+ tm_params = gymapi.TriangleMeshParams()
+ tm_params.nb_vertices = self.terrain.vertices.shape[0]
+ tm_params.nb_triangles = self.terrain.triangles.shape[0]
+
+ tm_params.transform.p.x = -self.terrain.cfg.border_size
+ tm_params.transform.p.y = -self.terrain.cfg.border_size
+ tm_params.transform.p.z = 0.0
+ tm_params.static_friction = self.cfg.terrain.static_friction
+ tm_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ tm_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_triangle_mesh(self.sim, self.terrain.vertices.flatten(order='C'),
+ self.terrain.triangles.flatten(order='C'), tm_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_envs(self):
+ """ Creates environments:
+ 1. loads the robot URDF/MJCF asset,
+ 2. For each environment
+ 2.1 creates the environment,
+ 2.2 calls DOF and Rigid shape properties callbacks,
+ 2.3 create actor with these properties and add them to the env
+ 3. Store indices of different bodies of the robot
+ """
+ asset_path = self.cfg.asset.file.format(LOCO_MANI_GYM_ROOT_DIR=LOCO_MANI_GYM_ROOT_DIR)
+ asset_root = os.path.dirname(asset_path)
+ asset_file = os.path.basename(asset_path)
+
+ asset_options = gymapi.AssetOptions()
+ asset_options.default_dof_drive_mode = self.cfg.asset.default_dof_drive_mode
+ asset_options.collapse_fixed_joints = self.cfg.asset.collapse_fixed_joints
+ asset_options.replace_cylinder_with_capsule = self.cfg.asset.replace_cylinder_with_capsule
+ asset_options.flip_visual_attachments = self.cfg.asset.flip_visual_attachments
+ asset_options.fix_base_link = self.cfg.asset.fix_base_link
+ asset_options.density = self.cfg.asset.density
+ asset_options.angular_damping = self.cfg.asset.angular_damping
+ asset_options.linear_damping = self.cfg.asset.linear_damping
+ asset_options.max_angular_velocity = self.cfg.asset.max_angular_velocity
+ asset_options.max_linear_velocity = self.cfg.asset.max_linear_velocity
+ asset_options.armature = self.cfg.asset.armature
+ asset_options.thickness = self.cfg.asset.thickness
+ asset_options.disable_gravity = self.cfg.asset.disable_gravity
+
+ robot_asset = self.gym.load_asset(self.sim, asset_root, asset_file, asset_options)
+ self.num_dof = self.gym.get_asset_dof_count(robot_asset)
+ self.num_bodies = self.gym.get_asset_rigid_body_count(robot_asset)
+ dof_props_asset = self.gym.get_asset_dof_properties(robot_asset)
+ rigid_shape_props_asset = self.gym.get_asset_rigid_shape_properties(robot_asset)
+
+ # save body names from the asset
+ body_names = self.gym.get_asset_rigid_body_names(robot_asset)
+ self.dof_names = self.gym.get_asset_dof_names(robot_asset)
+ self.num_bodies = len(body_names)
+ self.num_dofs = len(self.dof_names)
+ feet_names = [s for s in body_names if self.cfg.asset.foot_name in s]
+ penalized_contact_names = []
+ for name in self.cfg.asset.penalize_contacts_on:
+ penalized_contact_names.extend([s for s in body_names if name in s])
+ termination_contact_names = []
+ for name in self.cfg.asset.terminate_after_contacts_on:
+ termination_contact_names.extend([s for s in body_names if name in s])
+
+ base_init_state_list = self.cfg.init_state.pos + self.cfg.init_state.rot + self.cfg.init_state.lin_vel + self.cfg.init_state.ang_vel
+ self.base_init_state = to_torch(base_init_state_list, device=self.device, requires_grad=False)
+ start_pose = gymapi.Transform()
+ start_pose.p = gymapi.Vec3(*self.base_init_state[:3])
+
+ self._get_env_origins()
+ env_lower = gymapi.Vec3(0., 0., 0.)
+ env_upper = gymapi.Vec3(0., 0., 0.)
+ self.actor_handles = []
+ self.envs = []
+ for i in range(self.num_envs):
+ # create env instance
+ env_handle = self.gym.create_env(self.sim, env_lower, env_upper, int(np.sqrt(self.num_envs)))
+ pos = self.env_origins[i].clone()
+ pos[:2] += torch_rand_float(-1., 1., (2, 1), device=self.device).squeeze(1)
+ start_pose.p = gymapi.Vec3(*pos)
+
+ rigid_shape_props = self._process_rigid_shape_props(rigid_shape_props_asset, i)
+ self.gym.set_asset_rigid_shape_properties(robot_asset, rigid_shape_props)
+ actor_handle = self.gym.create_actor(env_handle, robot_asset, start_pose, self.cfg.asset.name, i,
+ self.cfg.asset.self_collisions, 0)
+ dof_props = self._process_dof_props(dof_props_asset, i)
+ self.gym.set_actor_dof_properties(env_handle, actor_handle, dof_props)
+ body_props = self.gym.get_actor_rigid_body_properties(env_handle, actor_handle)
+ body_props = self._process_rigid_body_props(body_props, i)
+ self.gym.set_actor_rigid_body_properties(env_handle, actor_handle, body_props, recomputeInertia=True)
+ self.envs.append(env_handle)
+ self.actor_handles.append(actor_handle)
+
+ self.feet_indices = torch.zeros(len(feet_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(feet_names)):
+ self.feet_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0],
+ feet_names[i])
+
+ self.penalised_contact_indices = torch.zeros(len(penalized_contact_names), dtype=torch.long, device=self.device,
+ requires_grad=False)
+ for i in range(len(penalized_contact_names)):
+ self.penalised_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ penalized_contact_names[i])
+
+ self.termination_contact_indices = torch.zeros(len(termination_contact_names), dtype=torch.long,
+ device=self.device, requires_grad=False)
+ for i in range(len(termination_contact_names)):
+ self.termination_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ termination_contact_names[i])
+
+ def _get_env_origins(self):
+ """ Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
+ Otherwise create a grid.
+ """
+ if self.cfg.terrain.mesh_type in ["heightfield", "trimesh"]:
+ self.custom_origins = True
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # put robots at the origins defined by the terrain
+ max_init_level = self.cfg.terrain.max_init_terrain_level
+ if not self.cfg.terrain.curriculum: max_init_level = self.cfg.terrain.num_rows - 1
+ self.terrain_levels = torch.randint(0, max_init_level + 1, (self.num_envs,), device=self.device)
+ self.terrain_types = torch.div(torch.arange(self.num_envs, device=self.device),
+ (self.num_envs / self.cfg.terrain.num_cols), rounding_mode='floor').to(
+ torch.long)
+ self.max_terrain_level = self.cfg.terrain.num_rows
+ self.terrain_origins = torch.from_numpy(self.terrain.env_origins).to(self.device).to(torch.float)
+ self.env_origins[:] = self.terrain_origins[self.terrain_levels, self.terrain_types]
+ else:
+ self.custom_origins = False
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # create a grid of robots
+ num_cols = np.floor(np.sqrt(self.num_envs))
+ num_rows = np.ceil(self.num_envs / num_cols)
+ xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
+ spacing = self.cfg.env.env_spacing
+ self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
+ self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
+ self.env_origins[:, 2] = 0.
+
+ def _parse_cfg(self, cfg):
+ self.dt = self.cfg.control.decimation * self.sim_params.dt
+ self.obs_scales = self.cfg.normalization.obs_scales
+ self.reward_scales = class_to_dict(self.cfg.rewards.scales)
+ self.command_ranges = class_to_dict(self.cfg.commands.ranges)
+ if self.cfg.terrain.mesh_type not in ['heightfield', 'trimesh']:
+ self.cfg.terrain.curriculum = False
+ self.max_episode_length_s = self.cfg.env.episode_length_s
+ self.max_episode_length = np.ceil(self.max_episode_length_s / self.dt)
+
+ self.cfg.domain_rand.push_interval = np.ceil(self.cfg.domain_rand.push_interval_s / self.dt)
+
+ def _draw_debug_vis(self):
+ """ Draws visualizations for dubugging (slows down simulation a lot).
+ Default behaviour: draws height measurement points
+ """
+ # draw height lines
+ if not self.terrain.cfg.measure_heights:
+ return
+ self.gym.clear_lines(self.viewer)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ sphere_geom = gymutil.WireframeSphereGeometry(0.02, 4, 4, None, color=(1, 1, 0))
+ for i in range(self.num_envs):
+ base_pos = (self.root_states[i, :3]).cpu().numpy()
+ heights = self.measured_heights[i].cpu().numpy()
+ height_points = quat_apply_yaw(self.base_quat[i].repeat(heights.shape[0]),
+ self.height_points[i]).cpu().numpy()
+ for j in range(heights.shape[0]):
+ x = height_points[j, 0] + base_pos[0]
+ y = height_points[j, 1] + base_pos[1]
+ z = heights[j]
+ sphere_pose = gymapi.Transform(gymapi.Vec3(x, y, z), r=None)
+ gymutil.draw_lines(sphere_geom, self.gym, self.viewer, self.envs[i], sphere_pose)
+
+ def _init_height_points(self):
+ """ Returns points at which the height measurments are sampled (in base frame)
+
+ Returns:
+ [torch.Tensor]: Tensor of shape (num_envs, self.num_height_points, 3)
+ """
+ y = torch.tensor(self.cfg.terrain.measured_points_y, device=self.device, requires_grad=False)
+ x = torch.tensor(self.cfg.terrain.measured_points_x, device=self.device, requires_grad=False)
+ grid_x, grid_y = torch.meshgrid(x, y)
+
+ self.num_height_points = grid_x.numel()
+ points = torch.zeros(self.num_envs, self.num_height_points, 3, device=self.device, requires_grad=False)
+ points[:, :, 0] = grid_x.flatten()
+ points[:, :, 1] = grid_y.flatten()
+ return points
+
+ def _get_heights(self, env_ids=None):
+ """ Samples heights of the terrain at required points around each robot.
+ The points are offset by the base's position and rotated by the base's yaw
+
+ Args:
+ env_ids (List[int], optional): Subset of environments for which to return the heights. Defaults to None.
+
+ Raises:
+ NameError: [description]
+
+ Returns:
+ [type]: [description]
+ """
+ if self.cfg.terrain.mesh_type == 'plane':
+ return torch.zeros(self.num_envs, self.num_height_points, device=self.device, requires_grad=False)
+ elif self.cfg.terrain.mesh_type == 'none':
+ raise NameError("Can't measure height with terrain mesh type 'none'")
+
+ if env_ids:
+ points = quat_apply_yaw(self.base_quat[env_ids].repeat(1, self.num_height_points),
+ self.height_points[env_ids]) + (self.root_states[env_ids, :3]).unsqueeze(1)
+ else:
+ points = quat_apply_yaw(self.base_quat.repeat(1, self.num_height_points), self.height_points) + (
+ self.root_states[:, :3]).unsqueeze(1)
+
+ points += self.terrain.cfg.border_size
+ points = (points / self.terrain.cfg.horizontal_scale).long()
+ px = points[:, :, 0].view(-1)
+ py = points[:, :, 1].view(-1)
+ px = torch.clip(px, 0, self.height_samples.shape[0] - 2)
+ py = torch.clip(py, 0, self.height_samples.shape[1] - 2)
+
+ heights1 = self.height_samples[px, py]
+ heights2 = self.height_samples[px + 1, py]
+ heights3 = self.height_samples[px, py + 1]
+ heights = torch.min(heights1, heights2)
+ heights = torch.min(heights, heights3)
+
+ return heights.view(self.num_envs, -1) * self.terrain.cfg.vertical_scale
+
+ # ------------ reward functions----------------
+ def _reward_lin_vel_z(self):
+ # Penalize z axis base linear velocity
+ return torch.square(self.base_lin_vel[:, 2])
+
+ def _reward_ang_vel_xy(self):
+ # Penalize xy axes base angular velocity
+ return torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1)
+
+ def _reward_orientation(self):
+ # Penalize non flat base orientation
+ return torch.sum(torch.square(self.projected_gravity[:, :2]), dim=1)
+
+ def _reward_base_height(self):
+ # Penalize base height away from target
+ base_height = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ return torch.square(base_height - self.cfg.rewards.base_height_target)
+
+ def _reward_torques(self):
+ # Penalize torques
+ return torch.sum(torch.square(self.torques), dim=1)
+
+ def _reward_dof_vel(self):
+ # Penalize dof velocities
+ return torch.sum(torch.square(self.dof_vel), dim=1)
+
+ def _reward_dof_acc(self):
+ # Penalize dof accelerations
+ return torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1)
+
+ def _reward_action_rate(self):
+ # Penalize changes in actions
+ return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
+
+ def _reward_collision(self):
+ # Penalize collisions on selected bodies
+ return torch.sum(1. * (torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1),
+ dim=1)
+
+ def _reward_termination(self):
+ # Terminal reward / penalty
+ return self.reset_buf * ~self.time_out_buf
+
+ def _reward_dof_pos_limits(self):
+ # Penalize dof positions too close to the limit
+ out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) # lower limit
+ out_of_limits += (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.)
+ return torch.sum(out_of_limits, dim=1)
+
+ def _reward_dof_vel_limits(self):
+ # Penalize dof velocities too close to the limit
+ # clip to max error = 1 rad/s per joint to avoid huge penalties
+ return torch.sum(
+ (torch.abs(self.dof_vel) - self.dof_vel_limits * self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.),
+ dim=1)
+
+ def _reward_torque_limits(self):
+ # penalize torques too close to the limit
+ return torch.sum(
+ (torch.abs(self.torques) - self.torque_limits * self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1)
+
+ def _reward_tracking_lin_vel(self):
+ # Tracking of linear velocity commands (xy axes)
+ lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
+ return torch.exp(-lin_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_tracking_ang_vel(self):
+ # Tracking of angular velocity commands (yaw)
+ ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
+ return torch.exp(-ang_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_feet_air_time(self):
+ # Reward long steps
+ # Need to filter the contacts because the contact reporting of PhysX is unreliable on meshes
+ contact = self.contact_forces[:, self.feet_indices, 2] > 1.
+ contact_filt = torch.logical_or(contact, self.last_contacts)
+ self.last_contacts = contact
+ first_contact = (self.feet_air_time > 0.) * contact_filt
+ self.feet_air_time += self.dt
+ rew_airTime = torch.sum((self.feet_air_time - 0.5) * first_contact,
+ dim=1) # reward only on first contact with the ground
+ rew_airTime *= torch.norm(self.commands[:, :2], dim=1) > 0.1 # no reward for zero command
+ self.feet_air_time *= ~contact_filt
+ return rew_airTime
+
+ def _reward_stumble(self):
+ # Penalize feet hitting vertical surfaces
+ return torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) > \
+ 5 * torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1)
+
+ def _reward_stand_still(self):
+ # Penalize motion at zero commands
+ return torch.sum(torch.abs(self.dof_pos - self.default_dof_pos), dim=1) * (
+ torch.norm(self.commands[:, :2], dim=1) < 0.1)
+
+ def _reward_feet_contact_forces(self):
+ # penalize high contact forces
+ return torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :],
+ dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1)
diff --git a/legged_gym/envs/fh/fh_config.py b/legged_gym/envs/fh/fh_config.py
new file mode 100644
index 0000000..f364343
--- /dev/null
+++ b/legged_gym/envs/fh/fh_config.py
@@ -0,0 +1,197 @@
+from legged_gym.envs.base.legged_robot_config_fh import LeggedRobotCfg_FH, LeggedRobotCfgPPO_FH
+
+
+class FHRoughCfg(LeggedRobotCfg_FH):
+ class env(LeggedRobotCfg_FH.env):
+ num_envs = 4096
+ num_actions = 14
+ num_observations = 69 #+ 187
+
+ class commands(LeggedRobotCfg_FH):
+ curriculum = False
+ max_curriculum = 1.5
+ num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
+ resampling_time = 10. # time before command are changed[s]
+ heading_command = False # if true: compute ang vel command from heading error
+
+ class ranges:
+ # lin_vel_x = [-1.5, 1.5] # min max [m/s]
+ # lin_vel_y = [-1.5, 1.5] # min max [m/s]
+ # ang_vel_yaw = [-1.0, 1.0] # min max [rad/s]
+ # heading = [-3.14, 3.14]
+
+ lin_vel_x = [-1.5, 1.5] # min max [m/s]
+ lin_vel_y = [-1.5, 1.5] # min max [m/s]
+ ang_vel_yaw = [-1.0, 1.0] # min max [rad/s]
+ heading = [-3.14, 3.14]
+
+ class terrain(LeggedRobotCfg_FH.terrain):
+ mesh_type = 'plane' # "heightfield" # none, plane, heightfield or trimesh
+ horizontal_scale = 0.1 # [m]
+ vertical_scale = 0.005 # [m]
+ border_size = 25 # [m]
+ curriculum = False
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # rough terrain only:
+ measure_heights = False
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
+ 0.8] # 1mx1.6m rectangle (without center line)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows = 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+ # terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
+ terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
+ # trimesh only:
+ slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces
+
+ class init_state(LeggedRobotCfg_FH.init_state):
+ pos = [0.0, 0.0, 0.65] # x,y,z [m]
+ default_joint_angles = { # = target angles [rad] when action = 0.0
+ 'LF_Joint': 0.05, # [rad]
+ 'RF_Joint': 0.05, # [rad]
+ 'LR_Joint': 0.0, # [rad]
+ 'RR_Joint': 0.0, # [rad]
+
+ 'L_hip_pitch_Joint': 0.0, # [rad]
+ 'R_hip_pitch_Joint': 0.0, # [rad]
+ 'L_behind_wheel_Joint': 0.0,
+ 'R_behind_wheel_Joint': 0.0,
+
+ 'L_knee_pitch_Joint': 0.0, # [rad]
+ 'R_knee_pitch_Joint': 0.0, # [rad]
+ 'L_knee_behind_Joint': 0.0,
+ 'R_knee_behind_Joint': 0.0,
+
+ 'L_front_wheel_Joint': 0.0,
+ 'R_front_wheel_Joint': 0.0,
+
+ }
+ init_joint_angles = { # = target angles [rad] when action = 0.0
+ 'LF_Joint': 0.0, # [rad]
+ 'RF_Joint': 0.0, # [rad]
+ 'LR_Joint': 0.0, # [rad]
+ 'RR_Joint': 0.0, # [rad]
+
+ 'L_hip_pitch_Joint': 0.0, # [rad]
+ 'R_hip_pitch_Joint': 0.0, # [rad]
+ 'L_behind_wheel_Joint': 0.0,
+ 'R_behind_wheel_Joint': 0.0,
+
+ 'L_knee_pitch_Joint': 0.0, # [rad]
+ 'R_knee_pitch_Joint': 0.0, # [rad]
+ 'L_knee_behind_Joint': 0.0,
+ 'R_knee_behind_Joint': 0.0,
+
+ 'L_front_wheel_Joint': 0.0,
+ 'R_front_wheel_Joint': 0.0,
+ }
+
+ class rewards:
+ class scales:
+ termination = -0.8
+ tracking_lin_vel = 3.0
+ tracking_ang_vel = 1.5
+ lin_vel_z = -0.1
+ ang_vel_xy = -0.05
+ orientation = 4
+ torques = -0.0001
+ dof_vel = -1e-7
+ dof_acc = -1e-7
+ base_height = -0.5
+ feet_air_time = 0
+ collision = -0.1
+ feet_stumble = -0.1
+ action_rate = -0.0002
+ stand_still = -0.01
+ dof_pos_limits = -0.9
+ arm_pos = -0.
+ hip_action_l2 = -0.1
+
+ only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
+ tracking_sigma = 0.4 # tracking reward = exp(-error^2/sigma)
+ soft_dof_pos_limit = 0.9 # percentage of urdf limits, values above this limit are penalized
+ soft_dof_vel_limit = 0.9
+ soft_torque_limit = 1.
+ base_height_target = 0.60
+ max_contact_force = 200. # forces above this value are penalized
+
+ class control(LeggedRobotCfg_FH.control):
+ # PD Drive parameters:
+ control_type = 'P'
+
+ stiffness = {'LF_Joint': 350.,
+ 'RF_Joint': 350.,
+ 'LR_Joint': 350.,
+ 'RR_Joint': 350.,
+
+ 'L_hip_pitch_Joint': 350., # [rad]
+ 'R_hip_pitch_Joint': 350., # [rad]
+ 'L_behind_wheel_Joint': 80.,
+ 'R_behind_wheel_Joint': 80.,
+
+ 'L_knee_pitch_Joint': 350., # [rad]
+ 'R_knee_pitch_Joint': 350., # [rad]
+ 'L_knee_behind_Joint': 400.,
+ 'R_knee_behind_Joint': 400.,
+
+ 'L_front_wheel_Joint': 80.,
+ 'R_front_wheel_Joint': 80.,
+ } # [N*m/rad]
+
+ damping = {'LF_Joint': 12.,
+ 'RF_Joint': 12.,
+ 'LR_Joint': 12.,
+ 'RR_Joint': 12.,
+
+ 'L_hip_pitch_Joint': 12., # [rad]
+ 'R_hip_pitch_Joint': 12., # [rad]
+ 'L_behind_wheel_Joint': 2.,
+ 'R_behind_wheel_Joint': 2.,
+
+ 'L_knee_pitch_Joint': 12., # [rad]
+ 'R_knee_pitch_Joint': 12., # [rad]
+ 'L_knee_behind_Joint': 12.,
+ 'R_knee_behind_Joint': 12.,
+
+ 'L_front_wheel_Joint': 2.,
+ 'R_front_wheel_Joint': 2.,
+ } # [N*m*s/rad]
+ # action scale: target angle = actionScale * action + defaultAngle
+ action_scale = 0.25
+ # decimation: Number of control action updates @ sim DT per policy DT
+ decimation = 4
+
+ class asset(LeggedRobotCfg_FH.asset):
+ file = '/home/hivecore/HiveCode_rl_gym/resources/robots/FHrobot/urdf/FHrobot.urdf' #######
+ name = "FHrobot"
+ arm_name = ""
+ foot_name = "wheel"
+ wheel_name = ["wheel"]
+ penalize_contacts_on = ["body_Link"]
+ terminate_after_contacts_on = []
+ self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter "base","calf","hip","thigh"
+ replace_cylinder_with_capsule = False
+ flip_visual_attachments = False
+
+
+class FHRoughCfgPPO(LeggedRobotCfgPPO_FH):
+ class algorithm(LeggedRobotCfgPPO_FH.algorithm):
+ entropy_coef = 0.003
+
+ class runner(LeggedRobotCfgPPO_FH.runner):
+ run_name = ''
+ experiment_name = 'fh'
+ resume = False
+ num_steps_per_env = 48 # per iteration
+ max_iterations = 10000
+ load_run = '' #''
+ checkpoint = 0
+
+
diff --git a/legged_gym/envs/fh/fh_env.py b/legged_gym/envs/fh/fh_env.py
new file mode 100644
index 0000000..238273d
--- /dev/null
+++ b/legged_gym/envs/fh/fh_env.py
@@ -0,0 +1,1035 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, envs
+import time
+from warnings import WarningMessage
+import numpy as np
+import os
+
+from isaacgym.torch_utils import *
+from isaacgym import gymtorch, gymapi, gymutil
+
+import torch
+from torch import Tensor
+from typing import Tuple, Dict
+
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from legged_gym.envs.base.base_task import BaseTask
+from legged_gym.envs.base.legged_robot_fh import LeggedRobot_FH
+from legged_gym.utils.terrain import Terrain
+from legged_gym.utils.math import quat_apply_yaw, wrap_to_pi, torch_rand_sqrt_float
+from legged_gym.utils.isaacgym_utils import get_euler_xyz as get_euler_xyz_in_tensor
+from legged_gym.utils.helpers import class_to_dict
+from .fh_config import FHRoughCfg
+
+def get_euler_xyz_tensor(quat):
+ r, p, w = get_euler_xyz(quat)
+ # stack r, p, w in dim1
+ euler_xyz = torch.stack((r, p, w), dim=1)
+ euler_xyz[euler_xyz > np.pi] -= 2 * np.pi
+ return euler_xyz
+
+class FH_Env(LeggedRobot_FH):
+ cfg: FHRoughCfg
+ def step(self, actions):
+ """ Apply actions, simulate, call self.post_physics_step()
+
+ Args:
+ actions (torch.Tensor): Tensor of shape (num_envs, num_actions_per_env)
+ """
+ # dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ # actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ # rigid_body_tensor = self.gym.acquire_rigid_body_state_tensor(self.sim)
+ # self.gym.refresh_dof_state_tensor(self.sim)
+ # self.gym.refresh_rigid_body_state_tensor(self.sim)
+ # self.gym.refresh_actor_root_state_tensor(self.sim)
+ # self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ # self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ # self.rigid_body_states = gymtorch.wrap_tensor(rigid_body_tensor).view(self.num_envs, -1, 13)
+ clip_actions = self.cfg.normalization.clip_actions
+ self.actions = torch.clip(actions, -clip_actions, clip_actions).to(self.device)
+ # step physics and render each frame
+ self.render()
+ for _ in range(self.cfg.control.decimation):
+ self.torques = self._compute_torques(self.actions).view(self.torques.shape)
+ self.gym.set_dof_actuation_force_tensor(self.sim, gymtorch.unwrap_tensor(self.torques))
+ self.gym.simulate(self.sim)
+ if self.device == 'cpu':
+ self.gym.fetch_results(self.sim, True)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.post_physics_step()
+
+ # return clipped obs, clipped states (None), rewards, dones and infos
+ clip_obs = self.cfg.normalization.clip_observations
+ self.obs_buf = torch.clip(self.obs_buf, -clip_obs, clip_obs)
+ if self.privileged_obs_buf is not None:
+ self.privileged_obs_buf = torch.clip(self.privileged_obs_buf, -clip_obs, clip_obs)
+ return self.obs_buf, self.privileged_obs_buf, self.rew_buf, self.reset_buf, self.extras
+
+ def post_physics_step(self):
+ """ check terminations, compute observations and rewards
+ calls self._post_physics_step_callback() for common computations
+ calls self._draw_debug_vis() if needed
+ """
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ rigid_body_tensor = self.gym.acquire_rigid_body_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ self.root_states = gymtorch.wrap_tensor(actor_root_state).view(-1, 13)
+
+ self.rigid_body_states = gymtorch.wrap_tensor(rigid_body_tensor).view(self.num_envs, -1, 13)
+ self.gripperMover_handles = self.gym.find_asset_rigid_body_index(self.robot_asset, "gripper_link")
+ self.base_handles = self.gym.find_asset_rigid_body_index(self.robot_asset, "base_link")
+ self._gripper_state = self.rigid_body_states[:, self.gripperMover_handles][:, 0:13]
+ self._gripper_pos = self.rigid_body_states[:, self.gripperMover_handles][:, 0:3]
+
+ self._gripper_rot = self.rigid_body_states[:, self.gripperMover_handles][:, 3:7]
+ self.base_pos = self.rigid_body_states[:, self.base_handles][:, 0:3]
+
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+ self._local_gripper_pos = quat_rotate_inverse(self.base_quat, self.base_pos - self._gripper_pos)
+ # get local frame quat
+ # self.local_frame_quat =
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1, 3)
+
+ self.episode_length_buf += 1
+ self.common_step_counter += 1
+
+ # prepare quantities
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.base_lin_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ self._post_physics_step_callback()
+
+ # compute observations, rewards, resets, ...
+ self.check_termination()
+ self.compute_reward()
+ # print("**self.reset_buf_buf:",self.reset_buf)
+ env_ids = self.reset_buf.nonzero(as_tuple=False).flatten()
+ self.reset_idx(env_ids)
+
+ # update_command
+
+ self.compute_observations() # in some cases a simulation step might be required to refresh some obs (for example body positions)
+
+ self.last_actions[:] = self.actions[:]
+ self.last_dof_vel[:] = self.dof_vel[:]
+ self.last_root_vel[:] = self.root_states[:, 7:13]
+
+ if self.viewer and self.enable_viewer_sync and self.debug_viz:
+ self._draw_debug_vis()
+
+ def check_termination(self):
+ """ Check if environments need to be reset
+ """
+ # print("self.contact_forces:",self.contact_forces[:, self.termination_contact_indices, :])
+ # print("self.feet_indices:",self.contact_forces[:, self.feet_indices , :])
+ self.reset_buf = torch.any(torch.norm(self.contact_forces[:, self.termination_contact_indices, :], dim=-1) > 1.,
+ dim=1)
+ self.time_out_buf = self.episode_length_buf > self.max_episode_length # no terminal reward for time-outs
+ # print("self.reset_buf_buf:",self.reset_buf)
+ self.reset_buf |= self.time_out_buf
+ contact_flag = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ self.base_contact_buf = torch.any(contact_flag.unsqueeze(1) < 0.20, dim=1)
+ self.reset_buf |= self.base_contact_buf
+
+ def reset_idx(self, env_ids):
+ """ Reset some environments.
+ Calls self._reset_dofs(env_ids), self._reset_root_states(env_ids), and self._resample_commands(env_ids)
+ [Optional] calls self._update_terrain_curriculum(env_ids), self.update_command_curriculum(env_ids) and
+ Logs episode info
+ Resets some buffers
+
+ Args:
+ env_ids (list[int]): List of environment ids which must be reset
+ """
+ if len(env_ids) == 0:
+ return
+ # update curriculum
+ if self.cfg.terrain.curriculum:
+ self._update_terrain_curriculum(env_ids)
+ # avoid updating command curriculum at each step since the maximum command is common to all envs
+ if self.cfg.commands.curriculum and (self.common_step_counter % self.max_episode_length == 0):
+ self.update_command_curriculum(env_ids)
+
+ # reset robot states
+ self._reset_dofs(env_ids)
+ self._reset_root_states(env_ids)
+
+ self._resample_commands(env_ids)
+
+ # reset buffers
+ self.last_actions[env_ids] = 0.
+ self.last_dof_vel[env_ids] = 0.
+ self.feet_air_time[env_ids] = 0.
+ self.episode_length_buf[env_ids] = 0
+ self.reset_buf[env_ids] = 1
+ # fill extras
+ self.extras["episode"] = {}
+ for key in self.episode_sums.keys():
+ self.extras["episode"]['rew_' + key] = torch.mean(
+ self.episode_sums[key][env_ids]) / self.max_episode_length_s
+ self.episode_sums[key][env_ids] = 0.
+ # log additional curriculum info
+ if self.cfg.terrain.curriculum:
+ self.extras["episode"]["terrain_level"] = torch.mean(self.terrain_levels.float())
+ if self.cfg.commands.curriculum:
+ self.extras["episode"]["max_command_x"] = self.command_ranges["lin_vel_x"][1]
+ # send timeout info to the algorithm
+ if self.cfg.env.send_timeouts:
+ self.extras["time_outs"] = self.time_out_buf
+
+ # fix reset gravity bug
+ self.base_quat[env_ids] = self.root_states[env_ids, 3:7]
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ def compute_reward(self):
+ """ Compute rewards
+ Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
+ adds each terms to the episode sums and to the total reward
+ """
+ self.rew_buf[:] = 0.
+ for i in range(len(self.reward_functions)):
+ name = self.reward_names[i]
+ rew = self.reward_functions[i]() * self.reward_scales[name]
+ self.rew_buf += rew
+ self.episode_sums[name] += rew
+ if self.cfg.rewards.only_positive_rewards:
+ self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
+ # add termination reward after clipping
+ if "termination" in self.reward_scales:
+ rew = self._reward_termination() * self.reward_scales["termination"]
+ self.rew_buf += rew
+ self.episode_sums["termination"] += rew
+
+ def compute_observations(self):
+ """ Computes observations
+ """
+
+ # self._local_gripper_pos = torch.zeros((self.num_envs,3),dtype=torch.float,device=self.device)
+
+ self.base_height_command = torch.tensor(self.cfg.rewards.base_height_target, dtype=torch.float,
+ device=self.device)
+ self.base_height_command = self.base_height_command.unsqueeze(0).repeat(self.num_envs, 1)
+ self.dof_err = self.dof_pos - self.default_dof_pos
+ self.dof_err[:, self.wheel_indices] = 0
+ self.dof_pos[:, self.wheel_indices] = 0
+ self.obs_buf = torch.cat((self.base_lin_vel * self.obs_scales.lin_vel,
+ self.base_ang_vel * self.obs_scales.ang_vel,
+ self.projected_gravity,
+ self.commands[:, :3] * self.commands_scale,
+ self.base_height_command,
+ self.dof_err * self.obs_scales.dof_pos,
+ self.dof_vel * self.obs_scales.dof_vel,
+ self.dof_pos,
+ self.actions,
+ ), dim=-1)
+ # add perceptive inputs if not blind
+ if self.cfg.terrain.measure_heights:
+ heights = torch.clip(self.root_states[:, 2].unsqueeze(1) - 0.5 - self.measured_heights, -1,
+ 1.) * self.obs_scales.height_measurements
+ self.obs_buf = torch.cat((self.obs_buf, heights), dim=-1)
+ # add noise if needed
+ if self.add_noise:
+ self.obs_buf += (2 * torch.rand_like(self.obs_buf) - 1) * self.noise_scale_vec
+
+ def create_sim(self):
+ """ Creates simulation, terrain and evironments
+ """
+ self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
+ self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine,
+ self.sim_params)
+ mesh_type = self.cfg.terrain.mesh_type
+ if mesh_type in ['heightfield', 'trimesh']:
+ self.terrain = Terrain(self.cfg.terrain, self.num_envs)
+ if mesh_type == 'plane':
+ self._create_ground_plane()
+ elif mesh_type == 'heightfield':
+ self._create_heightfield()
+ elif mesh_type == 'trimesh':
+ self._create_trimesh()
+ elif mesh_type is not None:
+ raise ValueError("Terrain mesh type not recognised. Allowed types are [None, plane, heightfield, trimesh]")
+ self._create_envs()
+
+ def set_camera(self, position, lookat):
+ """ Set camera position and direction
+ """
+ cam_pos = gymapi.Vec3(position[0], position[1], position[2])
+ cam_target = gymapi.Vec3(lookat[0], lookat[1], lookat[2])
+ self.gym.viewer_camera_look_at(self.viewer, None, cam_pos, cam_target)
+
+ # ------------- Callbacks --------------
+ def _process_rigid_shape_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the rigid shape properties of each environment.
+ Called During environment creation.
+ Base behavior: randomizes the friction of each environment
+
+ Args:
+ props (List[gymapi.RigidShapeProperties]): Properties of each shape of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [List[gymapi.RigidShapeProperties]]: Modified rigid shape properties
+ """
+ if self.cfg.domain_rand.randomize_friction:
+ if env_id == 0:
+ # prepare friction randomization
+ friction_range = self.cfg.domain_rand.friction_range
+ num_buckets = 64
+ bucket_ids = torch.randint(0, num_buckets, (self.num_envs, 1))
+ friction_buckets = torch_rand_float(friction_range[0], friction_range[1], (num_buckets, 1),
+ device='cpu')
+ self.friction_coeffs = friction_buckets[bucket_ids]
+
+ for s in range(len(props)):
+ props[s].friction = self.friction_coeffs[env_id]
+ return props
+
+ def _process_dof_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the DOF properties of each environment.
+ Called During environment creation.
+ Base behavior: stores position, velocity and torques limits defined in the URDF
+
+ Args:
+ props (numpy.array): Properties of each DOF of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [numpy.array]: Modified DOF properties
+ """
+ if env_id == 0:
+ self.dof_pos_limits = torch.zeros(self.num_dof, 2, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.dof_vel_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.torque_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(len(props)):
+ self.dof_pos_limits[i, 0] = props["lower"][i].item()
+ self.dof_pos_limits[i, 1] = props["upper"][i].item()
+ self.dof_vel_limits[i] = props["velocity"][i].item()
+ self.torque_limits[i] = props["effort"][i].item()
+ # soft limits
+ m = (self.dof_pos_limits[i, 0] + self.dof_pos_limits[i, 1]) / 2
+ r = self.dof_pos_limits[i, 1] - self.dof_pos_limits[i, 0]
+ self.dof_pos_limits[i, 0] = m - 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ self.dof_pos_limits[i, 1] = m + 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ return props
+
+ def _process_rigid_body_props(self, props, env_id):
+ # if env_id==0:
+ # sum = 0
+ # for i, p in enumerate(props):
+ # sum += p.mass
+ # print(f"Mass of body {i}: {p.mass} (before randomization)")
+ # print(f"Total mass {sum} (before randomization)")
+ # randomize base mass
+ if self.cfg.domain_rand.randomize_base_mass:
+ rng = self.cfg.domain_rand.added_mass_range
+ props[0].mass += np.random.uniform(rng[0], rng[1])
+ return props
+
+ def _post_physics_step_callback(self):
+ """ Callback called before computing terminations, rewards, and observations
+ Default behaviour: Compute ang vel command based on target and heading, compute measured terrain heights and randomly push robots
+ """
+ #
+ env_ids = (self.episode_length_buf % int(self.cfg.commands.resampling_time / self.dt) == 0).nonzero(
+ as_tuple=False).flatten()
+ self._resample_commands(env_ids)
+ if self.cfg.commands.heading_command:
+ forward = quat_apply(self.base_quat, self.forward_vec)
+ heading = torch.atan2(forward[:, 1], forward[:, 0])
+ self.commands[:, 2] = torch.clip(0.5 * wrap_to_pi(self.commands[:, 3] - heading), -1., 1.)
+
+ if self.cfg.terrain.measure_heights:
+ self.measured_heights = self._get_heights()
+ if self.cfg.domain_rand.push_robots and (self.common_step_counter % self.cfg.domain_rand.push_interval == 0):
+ self._push_robots()
+
+ def _resample_commands(self, env_ids):
+ """ Randommly select commands of some environments
+
+ Args:
+ env_ids (List[int]): Environments ids for which new commands are needed
+ """
+ self.commands[env_ids, 0] = torch_rand_float(self.command_ranges["lin_vel_x"][0],
+ self.command_ranges["lin_vel_x"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ self.commands[env_ids, 1] = torch_rand_float(self.command_ranges["lin_vel_y"][0],
+ self.command_ranges["lin_vel_y"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ if self.cfg.commands.heading_command:
+ self.commands[env_ids, 3] = torch_rand_float(self.command_ranges["heading"][0],
+ self.command_ranges["heading"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ else:
+ self.commands[env_ids, 2] = torch_rand_float(self.command_ranges["ang_vel_yaw"][0],
+ self.command_ranges["ang_vel_yaw"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+
+ # set small commands to zero
+ self.commands[env_ids, :2] *= (torch.norm(self.commands[env_ids, :2], dim=1) > 0.2).unsqueeze(1)
+
+ def _compute_torques(self, actions):
+ """ Compute torques from actions.
+ Actions can be interpreted as position or velocity targets given to a PD controller, or directly as scaled torques.
+ [NOTE]: torques must have the same dimension as the number of DOFs, even if some DOFs are not actuated.
+
+ Args:
+ actions (torch.Tensor): Actions
+
+ Returns:
+ [torch.Tensor]: Torques sent to the simulation
+ """
+ # pd controller
+ dof_err = self.default_dof_pos - self.dof_pos
+ dof_err[:, self.wheel_indices] = 0
+ self.dof_vel[:, self.wheel_indices] = -self.cfg.control.wheel_speed
+ dof_err[:, self.arm_indices] = self.cfg.control.arm_pos
+ actions_scaled = actions * self.cfg.control.action_scale
+ control_type = self.cfg.control.control_type
+ if control_type == "P":
+ torques = self.p_gains * (actions_scaled + dof_err) - self.d_gains * self.dof_vel
+ elif control_type == "V":
+ torques = self.p_gains * (actions_scaled - self.dof_vel) - self.d_gains * (
+ self.dof_vel - self.last_dof_vel) / self.sim_params.dt
+ elif control_type == "T":
+ torques = actions_scaled
+ else:
+ raise NameError(f"Unknown controller type: {control_type}")
+ return torch.clip(torques, -self.torque_limits, self.torque_limits)
+
+ def _reset_dofs(self, env_ids):
+ """ Resets DOF position and velocities of selected environmments
+ Positions are randomly selected within 0.5:1.5 x default positions.
+ Velocities are set to zero.
+
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ self.dof_pos[
+ env_ids] = self.init_dof_pos # * torch_rand_float(1, 1, (len(env_ids), self.num_dof), device=self.device)
+
+ self.dof_vel[env_ids] = 0.
+ # print("_reset_dofs:",env_ids)
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_dof_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.dof_state),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _reset_root_states(self, env_ids):
+ """ Resets ROOT states position and velocities of selected environmments
+ Sets base position based on the curriculum
+ Selects randomized base velocities within -0.5:0.5 [m/s, rad/s]
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ # base position
+ # print("_reset_root_states:",env_ids)
+ if self.custom_origins:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ self.root_states[env_ids, :2] += torch_rand_float(-1., 1., (len(env_ids), 2),
+ device=self.device) # xy position within 1m of the center
+ else:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ # base velocities
+ self.root_states[env_ids, 7:13] = torch_rand_float(-0.5, 0.5, (len(env_ids), 6), device=self.device)
+ # torch_rand_float(-0.5, 0.5, (len(env_ids), 6), device=self.device) # [7:10]: lin vel, [10:13]: ang vel
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _push_robots(self):
+ """ Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
+ """
+ max_vel = self.cfg.domain_rand.max_push_vel_xy
+ self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2),
+ device=self.device) # lin vel x/y
+ self.gym.set_actor_root_state_tensor(self.sim, gymtorch.unwrap_tensor(self.root_states))
+
+ def _update_terrain_curriculum(self, env_ids):
+ """ Implements the game-inspired curriculum.
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # Implement Terrain curriculum
+ if not self.init_done:
+ # don't change on initial reset
+ return
+ distance = torch.norm(self.root_states[env_ids, :2] - self.env_origins[env_ids, :2], dim=1)
+ # robots that walked far enough progress to harder terains
+ move_up = distance > self.terrain.env_length / 2
+ # robots that walked less than half of their required distance go to simpler terrains
+ move_down = (distance < torch.norm(self.commands[env_ids, :2],
+ dim=1) * self.max_episode_length_s * 0.5) * ~move_up
+ self.terrain_levels[env_ids] += 1 * move_up - 1 * move_down
+ # Robots that solve the last level are sent to a random one
+ self.terrain_levels[env_ids] = torch.where(self.terrain_levels[env_ids] >= self.max_terrain_level,
+ torch.randint_like(self.terrain_levels[env_ids],
+ self.max_terrain_level),
+ torch.clip(self.terrain_levels[env_ids],
+ 0)) # (the minumum level is zero)
+ self.env_origins[env_ids] = self.terrain_origins[self.terrain_levels[env_ids], self.terrain_types[env_ids]]
+
+ def update_command_curriculum(self, env_ids):
+ """ Implements a curriculum of increasing commands
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # If the tracking reward is above 80% of the maximum, increase the range of commands
+ if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * \
+ self.reward_scales["tracking_lin_vel"]:
+ self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5,
+ -self.cfg.commands.max_curriculum, 0.)
+ self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0.,
+ self.cfg.commands.max_curriculum)
+
+ def _get_noise_scale_vec(self, cfg):
+ """ Sets a vector used to scale the noise added to the observations.
+ [NOTE]: Must be adapted when changing the observations structure
+
+ Args:
+ cfg (Dict): Environment config file
+
+ Returns:
+ [torch.Tensor]: Vector of scales used to multiply a uniform distribution in [-1, 1]
+ """
+ noise_vec = torch.zeros_like(self.obs_buf[0])
+ self.add_noise = self.cfg.noise.add_noise
+ noise_scales = self.cfg.noise.noise_scales
+ noise_level = self.cfg.noise.noise_level
+ noise_vec[:3] = noise_scales.lin_vel * noise_level * self.obs_scales.lin_vel
+ noise_vec[3:6] = noise_scales.ang_vel * noise_level * self.obs_scales.ang_vel
+ noise_vec[6:9] = noise_scales.gravity * noise_level
+ noise_vec[9:12] = 0. # commands
+ noise_vec[12:26] = noise_scales.dof_pos * noise_level * self.obs_scales.dof_pos
+ noise_vec[26:40] = noise_scales.dof_vel * noise_level * self.obs_scales.dof_vel
+ noise_vec[40:54] = 0. # previous actions
+ if self.cfg.terrain.measure_heights:
+ noise_vec[54:235] = noise_scales.height_measurements * noise_level * self.obs_scales.height_measurements
+ return noise_vec
+
+ # ----------------------------------------
+ def _init_buffers(self):
+ """ Initialize torch tensors which will contain simulation states and processed quantities
+ """
+ # get gym GPU state tensors
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ # create some wrapper tensors for different slices
+ self.root_states = gymtorch.wrap_tensor(actor_root_state)
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1,
+ 3) # shape: num_envs, num_bodies, xyz axis
+
+ # initialize some data used later on
+ self.common_step_counter = 0
+ self.extras = {}
+ self.noise_scale_vec = self._get_noise_scale_vec(self.cfg)
+ self.gravity_vec = to_torch(get_axis_params(-1., self.up_axis_idx), device=self.device).repeat(
+ (self.num_envs, 1))
+ self.forward_vec = to_torch([1., 0., 0.], device=self.device).repeat((self.num_envs, 1))
+ self.torques = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_dof_vel = torch.zeros_like(self.dof_vel)
+ self.last_root_vel = torch.zeros_like(self.root_states[:, 7:13])
+ self.commands = torch.zeros(self.num_envs, self.cfg.commands.num_commands, dtype=torch.float,
+ device=self.device, requires_grad=False) # x vel, y vel, yaw vel, heading
+ self.commands_scale = torch.tensor([self.obs_scales.lin_vel, self.obs_scales.lin_vel, self.obs_scales.ang_vel],
+ device=self.device, requires_grad=False, ) # TODO change this
+ self.feet_air_time = torch.zeros(self.num_envs, self.feet_indices.shape[0], dtype=torch.float,
+ device=self.device, requires_grad=False)
+ self.last_contacts = torch.zeros(self.num_envs, len(self.feet_indices), dtype=torch.bool, device=self.device,
+ requires_grad=False)
+ self.base_lin_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ self._local_cube_object_pos = torch.zeros((self.num_envs, 3), dtype=torch.float, device=self.device)
+ self._local_cube_object_pos = torch.tensor([0.25, 0.004, 0.3], dtype=torch.float, device=self.device).repeat(
+ self.num_envs, 1)
+ if self.cfg.terrain.measure_heights:
+ self.height_points = self._init_height_points()
+ self.measured_heights = 0
+
+ # joint positions offsets and PD gains
+ self.default_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.init_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(self.num_dofs):
+ name = self.dof_names[i]
+ angle = self.cfg.init_state.default_joint_angles[name]
+ self.default_dof_pos[i] = angle
+ self.init_dof_pos[i] = self.cfg.init_state.init_joint_angles[name]
+ found = False
+ for dof_name in self.cfg.control.stiffness.keys():
+ if dof_name in name:
+ self.p_gains[i] = self.cfg.control.stiffness[dof_name]
+ self.d_gains[i] = self.cfg.control.damping[dof_name]
+ found = True
+ if not found:
+ self.p_gains[i] = 0.
+ self.d_gains[i] = 0.
+ if self.cfg.control.control_type in ["P", "V"]:
+ print(f"PD gain of joint {name} were not defined, setting them to zero")
+ self.default_dof_pos = self.default_dof_pos.unsqueeze(0)
+ self.init_dof_pos = self.init_dof_pos.unsqueeze(0)
+
+ def _prepare_reward_function(self):
+ """ Prepares a list of reward functions, whcih will be called to compute the total reward.
+ Looks for self._reward_, where are names of all non zero reward scales in the cfg.
+ """
+ # remove zero scales + multiply non-zero ones by dt
+ for key in list(self.reward_scales.keys()):
+ scale = self.reward_scales[key]
+ if scale == 0:
+ self.reward_scales.pop(key)
+ else:
+ self.reward_scales[key] *= self.dt
+ # prepare list of functions
+ self.reward_functions = []
+ self.reward_names = []
+ for name, scale in self.reward_scales.items():
+ if name == "termination":
+ continue
+ self.reward_names.append(name)
+ name = '_reward_' + name
+ self.reward_functions.append(getattr(self, name))
+
+ # reward episode sums
+ self.episode_sums = {
+ name: torch.zeros(self.num_envs, dtype=torch.float, device=self.device, requires_grad=False)
+ for name in self.reward_scales.keys()}
+
+ def _create_ground_plane(self):
+ """ Adds a ground plane to the simulation, sets friction and restitution based on the cfg.
+ """
+ plane_params = gymapi.PlaneParams()
+ plane_params.normal = gymapi.Vec3(0.0, 0.0, 1.0)
+ plane_params.static_friction = self.cfg.terrain.static_friction
+ plane_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ plane_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_ground(self.sim, plane_params)
+
+ def _create_heightfield(self):
+ """ Adds a heightfield terrain to the simulation, sets parameters based on the cfg.
+ """
+ hf_params = gymapi.HeightFieldParams()
+ hf_params.column_scale = self.terrain.cfg.horizontal_scale
+ hf_params.row_scale = self.terrain.cfg.horizontal_scale
+ hf_params.vertical_scale = self.terrain.cfg.vertical_scale
+ hf_params.nbRows = self.terrain.tot_cols
+ hf_params.nbColumns = self.terrain.tot_rows
+ hf_params.transform.p.x = -self.terrain.cfg.border_size
+ hf_params.transform.p.y = -self.terrain.cfg.border_size
+ hf_params.transform.p.z = 0.0
+ hf_params.static_friction = self.cfg.terrain.static_friction
+ hf_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ hf_params.restitution = self.cfg.terrain.restitution
+
+ self.gym.add_heightfield(self.sim, self.terrain.heightsamples, hf_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_trimesh(self):
+ """ Adds a triangle mesh terrain to the simulation, sets parameters based on the cfg.
+ # """
+ tm_params = gymapi.TriangleMeshParams()
+ tm_params.nb_vertices = self.terrain.vertices.shape[0]
+ tm_params.nb_triangles = self.terrain.triangles.shape[0]
+
+ tm_params.transform.p.x = -self.terrain.cfg.border_size
+ tm_params.transform.p.y = -self.terrain.cfg.border_size
+ tm_params.transform.p.z = 0.0
+ tm_params.static_friction = self.cfg.terrain.static_friction
+ tm_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ tm_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_triangle_mesh(self.sim, self.terrain.vertices.flatten(order='C'),
+ self.terrain.triangles.flatten(order='C'), tm_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_envs(self):
+ """ Creates environments:
+ 1. loads the robot URDF/MJCF asset,
+ 2. For each environment
+ 2.1 creates the environment,
+ 2.2 calls DOF and Rigid shape properties callbacks,
+ 2.3 create actor with these properties and add them to the env
+ 3. Store indices of different bodies of the robot
+ """
+ asset_path = self.cfg.asset.file.format(LEGGED_GYM_ROOT_DIR=LEGGED_GYM_ROOT_DIR)
+ asset_root = os.path.dirname(asset_path)
+ asset_file = os.path.basename(asset_path)
+
+ asset_options = gymapi.AssetOptions()
+ asset_options.default_dof_drive_mode = self.cfg.asset.default_dof_drive_mode
+ asset_options.collapse_fixed_joints = self.cfg.asset.collapse_fixed_joints
+ asset_options.replace_cylinder_with_capsule = self.cfg.asset.replace_cylinder_with_capsule
+ asset_options.flip_visual_attachments = self.cfg.asset.flip_visual_attachments
+ asset_options.fix_base_link = self.cfg.asset.fix_base_link
+ asset_options.density = self.cfg.asset.density
+ asset_options.angular_damping = self.cfg.asset.angular_damping
+ asset_options.linear_damping = self.cfg.asset.linear_damping
+ asset_options.max_angular_velocity = self.cfg.asset.max_angular_velocity
+ asset_options.max_linear_velocity = self.cfg.asset.max_linear_velocity
+ asset_options.armature = self.cfg.asset.armature
+ asset_options.thickness = self.cfg.asset.thickness
+ asset_options.disable_gravity = self.cfg.asset.disable_gravity
+
+ robot_asset = self.gym.load_asset(self.sim, asset_root, asset_file, asset_options)
+ self.robot_asset = robot_asset
+ self.num_dof = self.gym.get_asset_dof_count(robot_asset)
+ self.num_bodies = self.gym.get_asset_rigid_body_count(robot_asset)
+ dof_props_asset = self.gym.get_asset_dof_properties(robot_asset)
+ rigid_shape_props_asset = self.gym.get_asset_rigid_shape_properties(robot_asset)
+
+ # save body names from the asset
+ body_names = self.gym.get_asset_rigid_body_names(robot_asset)
+ self.dof_names = self.gym.get_asset_dof_names(robot_asset)
+ self.num_bodies = len(body_names)
+ self.num_dofs = len(self.dof_names)
+ feet_names = [s for s in body_names if self.cfg.asset.foot_name in s]
+ penalized_contact_names = []
+ for name in self.cfg.asset.penalize_contacts_on:
+ penalized_contact_names.extend([s for s in body_names if name in s])
+ termination_contact_names = []
+ for name in self.cfg.asset.terminate_after_contacts_on:
+ termination_contact_names.extend([s for s in body_names if name in s])
+ wheel_names = []
+ for name in self.cfg.asset.wheel_name:
+ wheel_names.extend([s for s in self.dof_names if name in s])
+ arm_names = []
+ for name in self.cfg.asset.arm_name:
+ arm_names.extend([s for s in self.dof_names if name in s])
+ print("###self.rigid_body names:", body_names)
+ print("###self.dof names:", self.dof_names)
+ print("###penalized_contact_names:", penalized_contact_names)
+ print("###termination_contact_names:", termination_contact_names)
+ print("###feet_names:", feet_names)
+ print("###wheels name:", wheel_names)
+ print("###arm_names:", arm_names)
+
+ base_init_state_list = self.cfg.init_state.pos + self.cfg.init_state.rot + self.cfg.init_state.lin_vel + self.cfg.init_state.ang_vel
+ self.base_init_state = to_torch(base_init_state_list, device=self.device, requires_grad=False)
+ start_pose = gymapi.Transform()
+ start_pose.p = gymapi.Vec3(*self.base_init_state[:3])
+
+ self._get_env_origins()
+ env_lower = gymapi.Vec3(0., 0., 0.)
+ env_upper = gymapi.Vec3(0., 0., 0.)
+ self.actor_handles = []
+ self.envs = []
+ for i in range(self.num_envs):
+ # create env instance
+ env_handle = self.gym.create_env(self.sim, env_lower, env_upper, int(np.sqrt(self.num_envs)))
+ pos = self.env_origins[i].clone()
+ pos[:2] += torch_rand_float(-1., 1., (2, 1), device=self.device).squeeze(1)
+ start_pose.p = gymapi.Vec3(*pos)
+
+ rigid_shape_props = self._process_rigid_shape_props(rigid_shape_props_asset, i)
+ self.gym.set_asset_rigid_shape_properties(robot_asset, rigid_shape_props)
+ actor_handle = self.gym.create_actor(env_handle, robot_asset, start_pose, self.cfg.asset.name, i,
+ self.cfg.asset.self_collisions, 0)
+ dof_props = self._process_dof_props(dof_props_asset, i)
+ self.gym.set_actor_dof_properties(env_handle, actor_handle, dof_props)
+ body_props = self.gym.get_actor_rigid_body_properties(env_handle, actor_handle)
+ body_props = self._process_rigid_body_props(body_props, i)
+ self.gym.set_actor_rigid_body_properties(env_handle, actor_handle, body_props, recomputeInertia=True)
+ self.envs.append(env_handle)
+ self.actor_handles.append(actor_handle)
+
+ self.feet_indices = torch.zeros(len(feet_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(feet_names)):
+ self.feet_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0],
+ feet_names[i])
+
+ self.penalised_contact_indices = torch.zeros(len(penalized_contact_names), dtype=torch.long, device=self.device,
+ requires_grad=False)
+ for i in range(len(penalized_contact_names)):
+ self.penalised_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ penalized_contact_names[i])
+
+ self.termination_contact_indices = torch.zeros(len(termination_contact_names), dtype=torch.long,
+ device=self.device, requires_grad=False)
+ for i in range(len(termination_contact_names)):
+ print("termination_contact_names[i]", termination_contact_names[i])
+ self.termination_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ termination_contact_names[i])
+ print("termination_contact_names[i]", termination_contact_names[i], "indice[i]:",
+ self.termination_contact_indices[i])
+
+ self.wheel_indices = torch.zeros(len(wheel_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(wheel_names)):
+ self.wheel_indices[i] = self.gym.find_actor_dof_handle(self.envs[0], self.actor_handles[0], wheel_names[i])
+
+ self.arm_indices = torch.zeros(len(arm_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(arm_names)):
+ self.arm_indices[i] = self.gym.find_actor_dof_handle(self.envs[0], self.actor_handles[0], arm_names[i])
+
+ def _get_env_origins(self):
+ """ Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
+ Otherwise create a grid.
+ """
+ if self.cfg.terrain.mesh_type in ["heightfield", "trimesh"]:
+ self.custom_origins = True
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # put robots at the origins defined by the terrain
+ max_init_level = self.cfg.terrain.max_init_terrain_level
+ if not self.cfg.terrain.curriculum: max_init_level = self.cfg.terrain.num_rows - 1
+ self.terrain_levels = torch.randint(0, max_init_level + 1, (self.num_envs,), device=self.device)
+ self.terrain_types = torch.div(torch.arange(self.num_envs, device=self.device),
+ (self.num_envs / self.cfg.terrain.num_cols), rounding_mode='floor').to(
+ torch.long)
+ self.max_terrain_level = self.cfg.terrain.num_rows
+ self.terrain_origins = torch.from_numpy(self.terrain.env_origins).to(self.device).to(torch.float)
+ self.env_origins[:] = self.terrain_origins[self.terrain_levels, self.terrain_types]
+ else:
+ self.custom_origins = False
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # create a grid of robots
+ num_cols = np.floor(np.sqrt(self.num_envs))
+ num_rows = np.ceil(self.num_envs / num_cols)
+ xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
+ spacing = self.cfg.env.env_spacing
+ self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
+ self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
+ self.env_origins[:, 2] = 0.
+
+ def _parse_cfg(self, cfg):
+ self.dt = self.cfg.control.decimation * self.sim_params.dt
+ self.obs_scales = self.cfg.normalization.obs_scales
+ self.reward_scales = class_to_dict(self.cfg.rewards.scales)
+ self.command_ranges = class_to_dict(self.cfg.commands.ranges)
+ if self.cfg.terrain.mesh_type not in ['heightfield', 'trimesh']:
+ self.cfg.terrain.curriculum = False
+ self.max_episode_length_s = self.cfg.env.episode_length_s
+ self.max_episode_length = np.ceil(self.max_episode_length_s / self.dt)
+
+ self.cfg.domain_rand.push_interval = np.ceil(self.cfg.domain_rand.push_interval_s / self.dt)
+
+ def _draw_debug_vis(self):
+ """ Draws visualizations for dubugging (slows down simulation a lot).
+ Default behaviour: draws height measurement points
+ """
+ # draw height lines
+ if not self.terrain.cfg.measure_heights:
+ return
+ self.gym.clear_lines(self.viewer)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ sphere_geom = gymutil.WireframeSphereGeometry(0.02, 4, 4, None, color=(1, 1, 0))
+ for i in range(self.num_envs):
+ base_pos = (self.root_states[i, :3]).cpu().numpy()
+ heights = self.measured_heights[i].cpu().numpy()
+ height_points = quat_apply_yaw(self.base_quat[i].repeat(heights.shape[0]),
+ self.height_points[i]).cpu().numpy()
+ for j in range(heights.shape[0]):
+ x = height_points[j, 0] + base_pos[0]
+ y = height_points[j, 1] + base_pos[1]
+ z = heights[j]
+ sphere_pose = gymapi.Transform(gymapi.Vec3(x, y, z), r=None)
+ gymutil.draw_lines(sphere_geom, self.gym, self.viewer, self.envs[i], sphere_pose)
+
+ def _init_height_points(self):
+ """ Returns points at which the height measurments are sampled (in base frame)
+
+ Returns:
+ [torch.Tensor]: Tensor of shape (num_envs, self.num_height_points, 3)
+ """
+ y = torch.tensor(self.cfg.terrain.measured_points_y, device=self.device, requires_grad=False)
+ x = torch.tensor(self.cfg.terrain.measured_points_x, device=self.device, requires_grad=False)
+ grid_x, grid_y = torch.meshgrid(x, y)
+
+ self.num_height_points = grid_x.numel()
+ points = torch.zeros(self.num_envs, self.num_height_points, 3, device=self.device, requires_grad=False)
+ points[:, :, 0] = grid_x.flatten()
+ points[:, :, 1] = grid_y.flatten()
+ return points
+
+ def _get_heights(self, env_ids=None):
+ """ Samples heights of the terrain at required points around each robot.
+ The points are offset by the base's position and rotated by the base's yaw
+
+ Args:
+ env_ids (List[int], optional): Subset of environments for which to return the heights. Defaults to None.
+
+ Raises:
+ NameError: [description]
+
+ Returns:
+ [type]: [description]
+ """
+ if self.cfg.terrain.mesh_type == 'plane':
+ return torch.zeros(self.num_envs, self.num_height_points, device=self.device, requires_grad=False)
+ elif self.cfg.terrain.mesh_type == 'none':
+ raise NameError("Can't measure height with terrain mesh type 'none'")
+
+ if env_ids:
+ points = quat_apply_yaw(self.base_quat[env_ids].repeat(1, self.num_height_points),
+ self.height_points[env_ids]) + (self.root_states[env_ids, :3]).unsqueeze(1)
+ else:
+ points = quat_apply_yaw(self.base_quat.repeat(1, self.num_height_points), self.height_points) + (
+ self.root_states[:, :3]).unsqueeze(1)
+
+ points += self.terrain.cfg.border_size
+ points = (points / self.terrain.cfg.horizontal_scale).long()
+ px = points[:, :, 0].view(-1)
+ py = points[:, :, 1].view(-1)
+ px = torch.clip(px, 0, self.height_samples.shape[0] - 2)
+ py = torch.clip(py, 0, self.height_samples.shape[1] - 2)
+
+ heights1 = self.height_samples[px, py]
+ heights2 = self.height_samples[px + 1, py]
+ heights3 = self.height_samples[px, py + 1]
+ heights = torch.min(heights1, heights2)
+ heights = torch.min(heights, heights3)
+
+ return heights.view(self.num_envs, -1) * self.terrain.cfg.vertical_scale
+
+ # ------------ reward functions----------------
+ def _reward_lin_vel_z(self):
+ # Penalize z axis base linear velocity
+ return torch.square(self.base_lin_vel[:, 2])
+
+ def _reward_ang_vel_xy(self):
+ # Penalize xy axes base angular velocity
+ return torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1)
+
+ def _reward_orientation(self):
+ # Penalize non flat base orientation
+ quat_mismatch = torch.exp(-torch.sum(torch.abs(self.base_euler_xyz[:, :2]), dim=1) * 10)
+ orientation = torch.exp(-torch.norm(self.projected_gravity[:, :2], dim=1) * 20)
+ return (quat_mismatch + orientation) / 2.
+
+ def _reward_base_height(self):
+ # Penalize base height away from target
+ base_height = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ return torch.square(base_height - self.cfg.rewards.base_height_target)
+
+ def _reward_torques(self):
+ # Penalize torques
+ return torch.sum(torch.square(self.torques), dim=1)
+
+ def _reward_dof_vel(self):
+ # Penalize dof velocities
+ self.dof_vel[:, self.wheel_indices] = 0
+ return torch.sum(torch.square(self.dof_vel), dim=1)
+
+ def _reward_dof_acc(self):
+ # Penalize dof accelerations
+ return torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1)
+
+ def _reward_action_rate(self):
+ # Penalize changes in actions
+ return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
+
+ def _reward_collision(self):
+ # Penalize collisions on selected bodies
+ return torch.sum(1. * (torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1),
+ dim=1)
+
+ def _reward_termination(self):
+ # Terminal reward / penalty
+ return self.reset_buf * ~self.time_out_buf
+
+ def _reward_dof_pos_limits(self):
+ # Penalize dof positions too close to the limit
+ out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) # lower limit
+ out_of_limits += (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.)
+ return torch.sum(out_of_limits, dim=1)
+
+ def _reward_dof_vel_limits(self):
+ # Penalize dof velocities too close to the limit
+ # clip to max error = 1 rad/s per joint to avoid huge penalties
+ return torch.sum(
+ (torch.abs(self.dof_vel) - self.dof_vel_limits * self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.),
+ dim=1)
+
+ def _reward_torque_limits(self):
+ # penalize torques too close to the limit
+ return torch.sum(
+ (torch.abs(self.torques) - self.torque_limits * self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1)
+
+ def _reward_tracking_lin_vel(self):
+ # Tracking of linear velocity commands (xy axes)
+ lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
+ return torch.exp(-lin_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_tracking_ang_vel(self):
+ # Tracking of angular velocity commands (yaw)
+ ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
+ return torch.exp(-ang_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_feet_air_time(self):
+ # Reward long steps
+ # Need to filter the contacts because the contact reporting of PhysX is unreliable on meshes
+ contact = self.contact_forces[:, self.feet_indices, 2] > 1.
+ contact_filt = torch.logical_or(contact, self.last_contacts)
+ self.last_contacts = contact
+ first_contact = (self.feet_air_time > 0.) * contact_filt
+ self.feet_air_time += self.dt
+ rew_airTime = torch.sum((self.feet_air_time - 0.5) * first_contact,
+ dim=1) # reward only on first contact with the ground
+ rew_airTime *= torch.norm(self.commands[:, :2], dim=1) > 0.1 # no reward for zero command
+ self.feet_air_time *= ~contact_filt
+ return rew_airTime
+
+ def _reward_feet_stumble(self):
+ # Penalize feet hitting vertical surfaces
+ return torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) > \
+ 5 * torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1)
+
+ def _reward_stand_still(self):
+ # Penalize motion at zero commands
+ dof_err = self.dof_pos - self.default_dof_pos
+ dof_err[:, self.wheel_indices] = 0
+ dof_err[:, self.arm_indices] = 0
+ return torch.sum(torch.abs(dof_err), dim=1) * (torch.norm(self.commands[:, :2], dim=1) < 0.1)
+
+ def _reward_feet_contact_forces(self):
+ # penalize high contact forces
+ return torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :],
+ dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1)
+
+ def _reward_orientation_quat(self):
+ # Penalize non flat base orientation
+
+ orientation_error = torch.sum(torch.square(self.root_states[:, :7] - self.base_init_state[0:7]), dim=1)
+ return torch.exp(-orientation_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_hip_action_l2(self):
+ action_l2 = torch.sum(self.actions[:, [0, 4, 8, 12]] ** 2, dim=1)
+ # self.episode_metric_sums['leg_action_l2'] += action_l2
+ return action_l2
\ No newline at end of file
diff --git a/legged_gym/envs/proto/legged_robot_config_pro.py b/legged_gym/envs/proto/legged_robot_config_pro.py
new file mode 100644
index 0000000..8c10311
--- /dev/null
+++ b/legged_gym/envs/proto/legged_robot_config_pro.py
@@ -0,0 +1,244 @@
+from legged_gym.envs.base.base_config import BaseConfig
+
+class LeggedRobotCfg_PRO(BaseConfig):
+ class env:
+ num_envs = 4096
+ num_observations = 235
+ num_privileged_obs = None # if not None a priviledge_obs_buf will be returned by step() (critic obs for assymetric training). None is returned otherwise
+ num_actions = 12
+ env_spacing = 3. # not used with heightfields/trimeshes
+ send_timeouts = True # send time out information to the algorithm
+ episode_length_s = 20 # episode length in seconds
+
+ class terrain:
+ mesh_type = 'trimesh' # "heightfield" # none, plane, heightfield or trimesh
+ horizontal_scale = 0.1 # [m]
+ vertical_scale = 0.005 # [m]
+ border_size = 25 # [m]
+ curriculum = True
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # rough terrain only:
+ measure_heights = True
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
+ 0.8] # 1mx1.6m rectangle (without center line)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows = 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+ # terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
+ terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
+ # trimesh only:
+ slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces
+
+ '''mesh_type = 'trimesh' # 使用三角网格表示复杂地形
+ horizontal_scale = 0.1 # 水平缩放 (米/单位)
+ vertical_scale = 0.005 # 垂直缩放 (米/单位),控制地形起伏程度
+ border_size = 25. # 边界大小 (米)
+ curriculum = False # 关闭课程学习,从一开始就在复杂地形上训练
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # 地形类型比例 [平滑斜坡, 粗糙斜坡, 上楼梯, 下楼梯, 离散障碍]
+ # 这里我们主要使用粗糙斜坡来创建略有高低不平的地形
+ terrain_proportions = [0.0, 1.0, 0.0, 0.0, 0.0] # 100% 粗糙斜坡
+ # 地形测量参数
+ measure_heights = True
+ measured_points_x = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5] # 1m 线 (共11个点)
+ measured_points_y = [-0.25, -0.125, 0., 0.125, 0.25] # 5条线
+
+ # 地形生成参数 - 针对粗糙地形
+ difficulty_scale = 1.0 # 难度缩放因子
+ roughness = 0.3 # 粗糙度参数 (0-1),控制地形起伏程度
+ # 对于略有高低不平的地形,使用中等粗糙度'''
+
+ class commands:
+ curriculum = False
+ max_curriculum = 1.
+ num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
+ resampling_time = 10. # time before command are changed[s]
+ heading_command = True # if true: compute ang vel command from heading error
+
+ class ranges:
+ lin_vel_x = [-1.0, 1.0] # min max [m/s]
+ lin_vel_y = [-1.0, 1.0] # min max [m/s]
+ ang_vel_yaw = [-1, 1] # min max [rad/s]
+ heading = [-3.14, 3.14]
+
+ class init_state:
+ pos = [0.0, 0.0, 1.] # x,y,z [m]
+ rot = [0.0, 0.0, 0.0, 1.0] # x,y,z,w [quat]
+ lin_vel = [0.0, 0.0, 0.0] # x,y,z [m/s]
+ ang_vel = [0.0, 0.0, 0.0] # x,y,z [rad/s]
+ default_joint_angles = { # target angles when action = 0.0
+ "joint_a": 0.,
+ "joint_b": 0.}
+
+ class control:
+ control_type = 'P' # P: position, V: velocity, T: torques
+ # PD Drive parameters:
+ stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
+ damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
+ # action scale: target angle = actionScale * action + defaultAngle
+ action_scale = 0.5
+ # decimation: Number of control action updates @ sim DT per policy DT
+ decimation = 4
+ wheel_speed = 1
+ arm_pos = 0
+
+ class asset:
+ file = ""
+ name = "legged_robot" # actor name
+ arm_name = ""
+ foot_name = "None" # name of the feet bodies, used to index body state and contact force tensors
+ penalize_contacts_on = []
+ terminate_after_contacts_on = []
+ disable_gravity = False
+ collapse_fixed_joints = True # merge bodies connected by fixed joints. Specific fixed joints can be kept by adding " <... dont_collapse="true">
+ fix_base_link = False # fixe the base of the robot
+ default_dof_drive_mode = 3 # see GymDofDriveModeFlags (0 is none, 1 is pos tgt, 2 is vel tgt, 3 effort)
+ self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter
+ replace_cylinder_with_capsule = True # replace collision cylinders with capsules, leads to faster/more stable simulation
+ flip_visual_attachments = False # Some .obj meshes must be flipped from y-up to z-up
+
+ density = 0.001
+ angular_damping = 0.
+ linear_damping = 0.
+ max_angular_velocity = 1000.
+ max_linear_velocity = 1000.
+ armature = 0.
+ thickness = 0.01
+
+ class domain_rand:
+ randomize_friction = True
+ friction_range = [0.5, 1.25]
+ randomize_base_mass = False
+ added_mass_range = [-1., 1.]
+ push_robots = True
+ push_interval_s = 15
+ max_push_vel_xy = 1.
+
+ class rewards:
+ class scales:
+ termination = -0.0
+ tracking_lin_vel = 1.0
+ tracking_ang_vel = 0.5
+ lin_vel_z = -2.0
+ ang_vel_xy = -0.05
+ orientation = -0.
+ torques = -0.00001
+ dof_vel = -0.
+ dof_acc = -2.5e-7
+ base_height = -0.
+ feet_air_time = 1.0
+ collision = -1.
+ feet_stumble = -0.0
+ action_rate = -0.01
+ stand_still = -0.
+
+ only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
+ tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
+ soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
+ soft_dof_vel_limit = 1.
+ soft_torque_limit = 1.
+ base_height_target = 1.
+ max_contact_force = 100. # forces above this value are penalized
+
+ class normalization:
+ class obs_scales:
+ lin_vel = 2.0
+ ang_vel = 0.25
+ dof_pos = 1.0
+ dof_vel = 0.05
+ height_measurements = 5.0
+
+ clip_observations = 100.
+ clip_actions = 100.
+
+ class noise:
+ add_noise = True
+ noise_level = 1.0 # scales other values
+
+ class noise_scales:
+ dof_pos = 0.01
+ dof_vel = 1.5
+ lin_vel = 0.1
+ ang_vel = 0.2
+ gravity = 0.05
+ height_measurements = 0.1
+
+ # viewer camera:
+ class viewer:
+ ref_env = 0
+ pos = [10, 0, 6] # [m]
+ lookat = [11., 5, 3.] # [m]
+
+ class sim:
+ dt = 0.005
+ substeps = 1
+ gravity = [0., 0., -9.81] # [m/s^2]
+ up_axis = 1 # 0 is y, 1 is z
+
+ class physx:
+ num_threads = 10
+ solver_type = 1 # 0: pgs, 1: tgs
+ num_position_iterations = 4
+ num_velocity_iterations = 0
+ contact_offset = 0.01 # [m]
+ rest_offset = 0.0 # [m]
+ bounce_threshold_velocity = 0.5 # 0.5 [m/s]
+ max_depenetration_velocity = 1.0
+ max_gpu_contact_pairs = 2 ** 23 # 2**24 -> needed for 8000 envs and more
+ default_buffer_size_multiplier = 5
+ contact_collection = 2 # 0: never, 1: last sub-step, 2: all sub-steps (default=2)
+
+
+class LeggedRobotCfgPPO_PRO(BaseConfig):
+ seed = 1
+ runner_class_name = 'OnPolicyRunner'
+
+ class policy:
+ init_noise_std = 1.0
+ actor_hidden_dims = [512, 256, 128]
+ critic_hidden_dims = [512, 256, 128]
+ activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
+ # only for 'ActorCriticRecurrent':
+ # rnn_type = 'lstm'
+ # rnn_hidden_size = 512
+ # rnn_num_layers = 1
+
+ class algorithm:
+ # training params
+ value_loss_coef = 1.0
+ use_clipped_value_loss = True
+ clip_param = 0.2
+ entropy_coef = 0.01
+ num_learning_epochs = 5
+ num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
+ learning_rate = 1.e-3 # 5.e-4
+ schedule = 'adaptive' # could be adaptive, fixed
+ gamma = 0.99
+ lam = 0.95
+ desired_kl = 0.01
+ max_grad_norm = 1.
+
+ class runner:
+ policy_class_name = 'ActorCritic'
+ algorithm_class_name = 'PPO'
+ num_steps_per_env = 24 # per iteration
+ max_iterations = 1500 # number of policy updates
+
+ # logging
+ save_interval = 50 # check for potential saves every this many iterations
+ experiment_name = 'test'
+ run_name = ''
+ # load and resume
+ resume = False
+ load_run = -1 # -1 = last run
+ checkpoint = -1 # -1 = last saved model
+ resume_path = None # updated from load_run and chkpt
\ No newline at end of file
diff --git a/legged_gym/envs/proto/legged_robot_pro.py b/legged_gym/envs/proto/legged_robot_pro.py
new file mode 100644
index 0000000..b793ae6
--- /dev/null
+++ b/legged_gym/envs/proto/legged_robot_pro.py
@@ -0,0 +1,938 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, envs
+import time
+from warnings import WarningMessage
+import numpy as np
+import os
+
+from isaacgym.torch_utils import *
+from isaacgym import gymtorch, gymapi, gymutil
+
+import torch
+from torch import Tensor
+from typing import Tuple, Dict
+
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from legged_gym.envs.base.base_task import BaseTask
+from legged_gym.utils.terrain import Terrain
+from legged_gym.utils.math import quat_apply_yaw, wrap_to_pi, torch_rand_sqrt_float
+from legged_gym.utils.isaacgym_utils import get_euler_xyz as get_euler_xyz_in_tensor
+from legged_gym.utils.helpers import class_to_dict
+from legged_gym.envs.proto.legged_robot_config_pro import LeggedRobotCfg_PRO
+
+class LeggedRobot_PRO(BaseTask):
+ def __init__(self, cfg: LeggedRobotCfg_PRO, sim_params, physics_engine, sim_device, headless):
+ """ Parses the provided config file,
+ calls create_sim() (which creates, simulation, terrain and environments),
+ initilizes pytorch buffers used during training
+
+ Args:
+ cfg (Dict): Environment config file
+ sim_params (gymapi.SimParams): simulation parameters
+ physics_engine (gymapi.SimType): gymapi.SIM_PHYSX (must be PhysX)
+ device_type (string): 'cuda' or 'cpu'
+ device_id (int): 0, 1, ...
+ headless (bool): Run without rendering if True
+ """
+ self.cfg = cfg
+ self.sim_params = sim_params
+ self.height_samples = None
+ self.debug_viz = False
+ self.init_done = False
+ self._parse_cfg(self.cfg)
+ super().__init__(self.cfg, sim_params, physics_engine, sim_device, headless)
+
+ if not self.headless:
+ self.set_camera(self.cfg.viewer.pos, self.cfg.viewer.lookat)
+ self._init_buffers()
+ self._prepare_reward_function()
+ self.init_done = True
+
+
+ def step(self, actions):
+ """ Apply actions, simulate, call self.post_physics_step()
+
+ Args:
+ actions (torch.Tensor): Tensor of shape (num_envs, num_actions_per_env)
+ """
+ clip_actions = self.cfg.normalization.clip_actions
+ self.actions = torch.clip(actions, -clip_actions, clip_actions).to(self.device)
+ # step physics and render each frame
+ self.render()
+ for _ in range(self.cfg.control.decimation):
+ self.torques = self._compute_torques(self.actions).view(self.torques.shape)
+ self.gym.set_dof_actuation_force_tensor(self.sim, gymtorch.unwrap_tensor(self.torques))
+ self.gym.simulate(self.sim)
+ if self.device == 'cpu':
+ self.gym.fetch_results(self.sim, True)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.post_physics_step()
+
+ # return clipped obs, clipped states (None), rewards, dones and infos
+ clip_obs = self.cfg.normalization.clip_observations
+ self.obs_buf = torch.clip(self.obs_buf, -clip_obs, clip_obs)
+ if self.privileged_obs_buf is not None:
+ self.privileged_obs_buf = torch.clip(self.privileged_obs_buf, -clip_obs, clip_obs)
+ return self.obs_buf, self.privileged_obs_buf, self.rew_buf, self.reset_buf, self.extras
+
+ def post_physics_step(self):
+ """ check terminations, compute observations and rewards
+ calls self._post_physics_step_callback() for common computations
+ calls self._draw_debug_vis() if needed
+ """
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ self.episode_length_buf += 1
+ self.common_step_counter += 1
+
+ # prepare quantities
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.base_lin_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+
+ self._post_physics_step_callback()
+
+ # compute observations, rewards, resets, ...
+ self.check_termination()
+ self.compute_reward()
+ env_ids = self.reset_buf.nonzero(as_tuple=False).flatten()
+ self.reset_idx(env_ids)
+ self.compute_observations() # in some cases a simulation step might be required to refresh some obs (for example body positions)
+
+ self.last_actions[:] = self.actions[:]
+ self.last_dof_vel[:] = self.dof_vel[:]
+ self.last_root_vel[:] = self.root_states[:, 7:13]
+
+ if self.viewer and self.enable_viewer_sync and self.debug_viz:
+ self._draw_debug_vis()
+
+ def check_termination(self):
+ """ Check if environments need to be reset
+ """
+ self.reset_buf = torch.any(torch.norm(self.contact_forces[:, self.termination_contact_indices, :], dim=-1) > 1.,
+ dim=1)
+ self.time_out_buf = self.episode_length_buf > self.max_episode_length # no terminal reward for time-outs
+ self.reset_buf |= self.time_out_buf
+
+ def reset_idx(self, env_ids):
+ """ Reset some environments.
+ Calls self._reset_dofs(env_ids), self._reset_root_states(env_ids), and self._resample_commands(env_ids)
+ [Optional] calls self._update_terrain_curriculum(env_ids), self.update_command_curriculum(env_ids) and
+ Logs episode info
+ Resets some buffers
+
+ Args:
+ env_ids (list[int]): List of environment ids which must be reset
+ """
+ if len(env_ids) == 0:
+ return
+ # update curriculum
+ if self.cfg.terrain.curriculum:
+ self._update_terrain_curriculum(env_ids)
+ # avoid updating command curriculum at each step since the maximum command is common to all envs
+ if self.cfg.commands.curriculum and (self.common_step_counter % self.max_episode_length == 0):
+ self.update_command_curriculum(env_ids)
+
+ # reset robot states
+ self._reset_dofs(env_ids)
+ self._reset_root_states(env_ids)
+
+ self._resample_commands(env_ids)
+
+ # reset buffers
+ self.last_actions[env_ids] = 0.
+ self.last_dof_vel[env_ids] = 0.
+ self.feet_air_time[env_ids] = 0.
+ self.episode_length_buf[env_ids] = 0
+ self.reset_buf[env_ids] = 1
+ # fill extras
+ self.extras["episode"] = {}
+ for key in self.episode_sums.keys():
+ self.extras["episode"]['rew_' + key] = torch.mean(
+ self.episode_sums[key][env_ids]) / self.max_episode_length_s
+ self.episode_sums[key][env_ids] = 0.
+ # log additional curriculum info
+ if self.cfg.terrain.curriculum:
+ self.extras["episode"]["terrain_level"] = torch.mean(self.terrain_levels.float())
+ if self.cfg.commands.curriculum:
+ self.extras["episode"]["max_command_x"] = self.command_ranges["lin_vel_x"][1]
+ # send timeout info to the algorithm
+ if self.cfg.env.send_timeouts:
+ self.extras["time_outs"] = self.time_out_buf
+
+ def compute_reward(self):
+ """ Compute rewards
+ Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
+ adds each terms to the episode sums and to the total reward
+ """
+ self.rew_buf[:] = 0.
+ for i in range(len(self.reward_functions)):
+ name = self.reward_names[i]
+ rew = self.reward_functions[i]() * self.reward_scales[name]
+ self.rew_buf += rew
+ self.episode_sums[name] += rew
+ if self.cfg.rewards.only_positive_rewards:
+ self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
+ # add termination reward after clipping
+ if "termination" in self.reward_scales:
+ rew = self._reward_termination() * self.reward_scales["termination"]
+ self.rew_buf += rew
+ self.episode_sums["termination"] += rew
+
+ def compute_observations(self):
+ """ Computes observations
+ """
+ self.obs_buf = torch.cat((self.base_lin_vel * self.obs_scales.lin_vel,
+ self.base_ang_vel * self.obs_scales.ang_vel,
+ self.projected_gravity,
+ self.commands[:, :3] * self.commands_scale,
+ (self.dof_pos - self.default_dof_pos) * self.obs_scales.dof_pos,
+ self.dof_vel * self.obs_scales.dof_vel,
+ self.actions
+ ), dim=-1)
+ # add perceptive inputs if not blind
+ if self.cfg.terrain.measure_heights:
+ heights = torch.clip(self.root_states[:, 2].unsqueeze(1) - 0.5 - self.measured_heights, -1,
+ 1.) * self.obs_scales.height_measurements
+ self.obs_buf = torch.cat((self.obs_buf, heights), dim=-1)
+ # add noise if needed
+ if self.add_noise:
+ self.obs_buf += (2 * torch.rand_like(self.obs_buf) - 1) * self.noise_scale_vec
+
+ def create_sim(self):
+ """ Creates simulation, terrain and evironments
+ """
+ self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
+ self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine,
+ self.sim_params)
+ mesh_type = self.cfg.terrain.mesh_type
+ if mesh_type in ['heightfield', 'trimesh']:
+ self.terrain = Terrain(self.cfg.terrain, self.num_envs)
+ if mesh_type == 'plane':
+ self._create_ground_plane()
+ elif mesh_type == 'heightfield':
+ self._create_heightfield()
+ elif mesh_type == 'trimesh':
+ self._create_trimesh()
+ elif mesh_type is not None:
+ raise ValueError("Terrain mesh type not recognised. Allowed types are [None, plane, heightfield, trimesh]")
+ self._create_envs()
+
+ def set_camera(self, position, lookat):
+ """ Set camera position and direction
+ """
+ cam_pos = gymapi.Vec3(position[0], position[1], position[2])
+ cam_target = gymapi.Vec3(lookat[0], lookat[1], lookat[2])
+ self.gym.viewer_camera_look_at(self.viewer, None, cam_pos, cam_target)
+
+ # ------------- Callbacks --------------
+ def _process_rigid_shape_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the rigid shape properties of each environment.
+ Called During environment creation.
+ Base behavior: randomizes the friction of each environment
+
+ Args:
+ props (List[gymapi.RigidShapeProperties]): Properties of each shape of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [List[gymapi.RigidShapeProperties]]: Modified rigid shape properties
+ """
+ if self.cfg.domain_rand.randomize_friction:
+ if env_id == 0:
+ # prepare friction randomization
+ friction_range = self.cfg.domain_rand.friction_range
+ num_buckets = 64
+ bucket_ids = torch.randint(0, num_buckets, (self.num_envs, 1))
+ friction_buckets = torch_rand_float(friction_range[0], friction_range[1], (num_buckets, 1),
+ device='cpu')
+ self.friction_coeffs = friction_buckets[bucket_ids]
+
+ for s in range(len(props)):
+ props[s].friction = self.friction_coeffs[env_id]
+ return props
+
+ def _process_dof_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the DOF properties of each environment.
+ Called During environment creation.
+ Base behavior: stores position, velocity and torques limits defined in the URDF
+
+ Args:
+ props (numpy.array): Properties of each DOF of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [numpy.array]: Modified DOF properties
+ """
+ if env_id == 0:
+ self.dof_pos_limits = torch.zeros(self.num_dof, 2, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.dof_vel_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.torque_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(len(props)):
+ self.dof_pos_limits[i, 0] = props["lower"][i].item()
+ self.dof_pos_limits[i, 1] = props["upper"][i].item()
+ self.dof_vel_limits[i] = props["velocity"][i].item()
+ self.torque_limits[i] = props["effort"][i].item()
+ # soft limits
+ m = (self.dof_pos_limits[i, 0] + self.dof_pos_limits[i, 1]) / 2
+ r = self.dof_pos_limits[i, 1] - self.dof_pos_limits[i, 0]
+ self.dof_pos_limits[i, 0] = m - 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ self.dof_pos_limits[i, 1] = m + 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ return props
+
+ def _process_rigid_body_props(self, props, env_id):
+ # if env_id==0:
+ # sum = 0
+ # for i, p in enumerate(props):
+ # sum += p.mass
+ # print(f"Mass of body {i}: {p.mass} (before randomization)")
+ # print(f"Total mass {sum} (before randomization)")
+ # randomize base mass
+ if self.cfg.domain_rand.randomize_base_mass:
+ rng = self.cfg.domain_rand.added_mass_range
+ props[0].mass += np.random.uniform(rng[0], rng[1])
+ return props
+
+ def _post_physics_step_callback(self):
+ """ Callback called before computing terminations, rewards, and observations
+ Default behaviour: Compute ang vel command based on target and heading, compute measured terrain heights and randomly push robots
+ """
+ #
+ env_ids = (self.episode_length_buf % int(self.cfg.commands.resampling_time / self.dt) == 0).nonzero(
+ as_tuple=False).flatten()
+ self._resample_commands(env_ids)
+ if self.cfg.commands.heading_command:
+ forward = quat_apply(self.base_quat, self.forward_vec)
+ heading = torch.atan2(forward[:, 1], forward[:, 0])
+ self.commands[:, 2] = torch.clip(0.5 * wrap_to_pi(self.commands[:, 3] - heading), -1., 1.)
+
+ if self.cfg.terrain.measure_heights:
+ self.measured_heights = self._get_heights()
+ if self.cfg.domain_rand.push_robots and (self.common_step_counter % self.cfg.domain_rand.push_interval == 0):
+ self._push_robots()
+
+ def _resample_commands(self, env_ids):
+ """ Randommly select commands of some environments
+
+ Args:
+ env_ids (List[int]): Environments ids for which new commands are needed
+ """
+ self.commands[env_ids, 0] = torch_rand_float(self.command_ranges["lin_vel_x"][0],
+ self.command_ranges["lin_vel_x"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ self.commands[env_ids, 1] = torch_rand_float(self.command_ranges["lin_vel_y"][0],
+ self.command_ranges["lin_vel_y"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ if self.cfg.commands.heading_command:
+ self.commands[env_ids, 3] = torch_rand_float(self.command_ranges["heading"][0],
+ self.command_ranges["heading"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ else:
+ self.commands[env_ids, 2] = torch_rand_float(self.command_ranges["ang_vel_yaw"][0],
+ self.command_ranges["ang_vel_yaw"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+
+ # set small commands to zero
+ self.commands[env_ids, :2] *= (torch.norm(self.commands[env_ids, :2], dim=1) > 0.2).unsqueeze(1)
+
+ def _compute_torques(self, actions):
+ """ Compute torques from actions.
+ Actions can be interpreted as position or velocity targets given to a PD controller, or directly as scaled torques.
+ [NOTE]: torques must have the same dimension as the number of DOFs, even if some DOFs are not actuated.
+
+ Args:
+ actions (torch.Tensor): Actions
+
+ Returns:
+ [torch.Tensor]: Torques sent to the simulation
+ """
+ # pd controller
+ actions_scaled = actions * self.cfg.control.action_scale
+ control_type = self.cfg.control.control_type
+ if control_type == "P":
+ torques = self.p_gains * (
+ actions_scaled + self.default_dof_pos - self.dof_pos) - self.d_gains * self.dof_vel
+ elif control_type == "V":
+ torques = self.p_gains * (actions_scaled - self.dof_vel) - self.d_gains * (
+ self.dof_vel - self.last_dof_vel) / self.sim_params.dt
+ elif control_type == "T":
+ torques = actions_scaled
+ else:
+ raise NameError(f"Unknown controller type: {control_type}")
+ return torch.clip(torques, -self.torque_limits, self.torque_limits)
+
+ def _reset_dofs(self, env_ids):
+ """ Resets DOF position and velocities of selected environmments
+ Positions are randomly selected within 0.5:1.5 x default positions.
+ Velocities are set to zero.
+
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ self.dof_pos[env_ids] = self.default_dof_pos * torch_rand_float(0.5, 1.5, (len(env_ids), self.num_dof),
+ device=self.device)
+ self.dof_vel[env_ids] = 0.
+
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_dof_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.dof_state),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _reset_root_states(self, env_ids):
+ """ Resets ROOT states position and velocities of selected environmments
+ Sets base position based on the curriculum
+ Selects randomized base velocities within -0.5:0.5 [m/s, rad/s]
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ # base position
+ if self.custom_origins:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ self.root_states[env_ids, :2] += torch_rand_float(-1., 1., (len(env_ids), 2),
+ device=self.device) # xy position within 1m of the center
+ else:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ # base velocities
+ self.root_states[env_ids, 7:13] = torch_rand_float(-0.5, 0.5, (len(env_ids), 6),
+ device=self.device) # [7:10]: lin vel, [10:13]: ang vel
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _push_robots(self):
+ """ Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
+ """
+ max_vel = self.cfg.domain_rand.max_push_vel_xy
+ self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2),
+ device=self.device) # lin vel x/y
+ self.gym.set_actor_root_state_tensor(self.sim, gymtorch.unwrap_tensor(self.root_states))
+
+ def _update_terrain_curriculum(self, env_ids):
+ """ Implements the game-inspired curriculum.
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # Implement Terrain curriculum
+ if not self.init_done:
+ # don't change on initial reset
+ return
+ distance = torch.norm(self.root_states[env_ids, :2] - self.env_origins[env_ids, :2], dim=1)
+ # robots that walked far enough progress to harder terains
+ move_up = distance > self.terrain.env_length / 2
+ # robots that walked less than half of their required distance go to simpler terrains
+ move_down = (distance < torch.norm(self.commands[env_ids, :2],
+ dim=1) * self.max_episode_length_s * 0.5) * ~move_up
+ self.terrain_levels[env_ids] += 1 * move_up - 1 * move_down
+ # Robots that solve the last level are sent to a random one
+ self.terrain_levels[env_ids] = torch.where(self.terrain_levels[env_ids] >= self.max_terrain_level,
+ torch.randint_like(self.terrain_levels[env_ids],
+ self.max_terrain_level),
+ torch.clip(self.terrain_levels[env_ids],
+ 0)) # (the minumum level is zero)
+ self.env_origins[env_ids] = self.terrain_origins[self.terrain_levels[env_ids], self.terrain_types[env_ids]]
+
+ def update_command_curriculum(self, env_ids):
+ """ Implements a curriculum of increasing commands
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # If the tracking reward is above 80% of the maximum, increase the range of commands
+ if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * \
+ self.reward_scales["tracking_lin_vel"]:
+ self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5,
+ -self.cfg.commands.max_curriculum, 0.)
+ self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0.,
+ self.cfg.commands.max_curriculum)
+
+ def _get_noise_scale_vec(self, cfg):
+ """ Sets a vector used to scale the noise added to the observations.
+ [NOTE]: Must be adapted when changing the observations structure
+
+ Args:
+ cfg (Dict): Environment config file
+
+ Returns:
+ [torch.Tensor]: Vector of scales used to multiply a uniform distribution in [-1, 1]
+ """
+ noise_vec = torch.zeros_like(self.obs_buf[0])
+ self.add_noise = self.cfg.noise.add_noise
+ noise_scales = self.cfg.noise.noise_scales
+ noise_level = self.cfg.noise.noise_level
+ noise_vec[:3] = noise_scales.lin_vel * noise_level * self.obs_scales.lin_vel
+ noise_vec[3:6] = noise_scales.ang_vel * noise_level * self.obs_scales.ang_vel
+ noise_vec[6:9] = noise_scales.gravity * noise_level
+ noise_vec[9:12] = 0. # commands
+ noise_vec[12:24] = noise_scales.dof_pos * noise_level * self.obs_scales.dof_pos
+ noise_vec[24:36] = noise_scales.dof_vel * noise_level * self.obs_scales.dof_vel
+ noise_vec[36:48] = 0. # previous actions
+ if self.cfg.terrain.measure_heights:
+ noise_vec[48:235] = noise_scales.height_measurements * noise_level * self.obs_scales.height_measurements
+ return noise_vec
+
+ # ----------------------------------------
+ def _init_buffers(self):
+ """ Initialize torch tensors which will contain simulation states and processed quantities
+ """
+ # get gym GPU state tensors
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ # create some wrapper tensors for different slices
+ self.root_states = gymtorch.wrap_tensor(actor_root_state)
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1,
+ 3) # shape: num_envs, num_bodies, xyz axis
+
+ # initialize some data used later on
+ self.common_step_counter = 0
+ self.extras = {}
+ self.noise_scale_vec = self._get_noise_scale_vec(self.cfg)
+ self.gravity_vec = to_torch(get_axis_params(-1., self.up_axis_idx), device=self.device).repeat(
+ (self.num_envs, 1))
+ self.forward_vec = to_torch([1., 0., 0.], device=self.device).repeat((self.num_envs, 1))
+ self.torques = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_dof_vel = torch.zeros_like(self.dof_vel)
+ self.last_root_vel = torch.zeros_like(self.root_states[:, 7:13])
+ self.commands = torch.zeros(self.num_envs, self.cfg.commands.num_commands, dtype=torch.float,
+ device=self.device, requires_grad=False) # x vel, y vel, yaw vel, heading
+ self.commands_scale = torch.tensor([self.obs_scales.lin_vel, self.obs_scales.lin_vel, self.obs_scales.ang_vel],
+ device=self.device, requires_grad=False, ) # TODO change this
+ self.feet_air_time = torch.zeros(self.num_envs, self.feet_indices.shape[0], dtype=torch.float,
+ device=self.device, requires_grad=False)
+ self.last_contacts = torch.zeros(self.num_envs, len(self.feet_indices), dtype=torch.bool, device=self.device,
+ requires_grad=False)
+ self.base_lin_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ if self.cfg.terrain.measure_heights:
+ self.height_points = self._init_height_points()
+ self.measured_heights = 0
+
+ # joint positions offsets and PD gains
+ self.default_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(self.num_dofs):
+ name = self.dof_names[i]
+ angle = self.cfg.init_state.default_joint_angles[name]
+ self.default_dof_pos[i] = angle
+ found = False
+ for dof_name in self.cfg.control.stiffness.keys():
+ if dof_name in name:
+ self.p_gains[i] = self.cfg.control.stiffness[dof_name]
+ self.d_gains[i] = self.cfg.control.damping[dof_name]
+ found = True
+ if not found:
+ self.p_gains[i] = 0.
+ self.d_gains[i] = 0.
+ if self.cfg.control.control_type in ["P", "V"]:
+ print(f"PD gain of joint {name} were not defined, setting them to zero")
+ self.default_dof_pos = self.default_dof_pos.unsqueeze(0)
+
+ def _prepare_reward_function(self):
+ """ Prepares a list of reward functions, whcih will be called to compute the total reward.
+ Looks for self._reward_, where are names of all non zero reward scales in the cfg.
+ """
+ # remove zero scales + multiply non-zero ones by dt
+ for key in list(self.reward_scales.keys()):
+ scale = self.reward_scales[key]
+ if scale == 0:
+ self.reward_scales.pop(key)
+ else:
+ self.reward_scales[key] *= self.dt
+ # prepare list of functions
+ self.reward_functions = []
+ self.reward_names = []
+ for name, scale in self.reward_scales.items():
+ if name == "termination":
+ continue
+ self.reward_names.append(name)
+ name = '_reward_' + name
+ self.reward_functions.append(getattr(self, name))
+
+ # reward episode sums
+ self.episode_sums = {
+ name: torch.zeros(self.num_envs, dtype=torch.float, device=self.device, requires_grad=False)
+ for name in self.reward_scales.keys()}
+
+ def _create_ground_plane(self):
+ """ Adds a ground plane to the simulation, sets friction and restitution based on the cfg.
+ """
+ plane_params = gymapi.PlaneParams()
+ plane_params.normal = gymapi.Vec3(0.0, 0.0, 1.0)
+ plane_params.static_friction = self.cfg.terrain.static_friction
+ plane_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ plane_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_ground(self.sim, plane_params)
+
+ def _create_heightfield(self):
+ """ Adds a heightfield terrain to the simulation, sets parameters based on the cfg.
+ """
+ hf_params = gymapi.HeightFieldParams()
+ hf_params.column_scale = self.terrain.cfg.horizontal_scale
+ hf_params.row_scale = self.terrain.cfg.horizontal_scale
+ hf_params.vertical_scale = self.terrain.cfg.vertical_scale
+ hf_params.nbRows = self.terrain.tot_cols
+ hf_params.nbColumns = self.terrain.tot_rows
+ hf_params.transform.p.x = -self.terrain.cfg.border_size
+ hf_params.transform.p.y = -self.terrain.cfg.border_size
+ hf_params.transform.p.z = 0.0
+ hf_params.static_friction = self.cfg.terrain.static_friction
+ hf_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ hf_params.restitution = self.cfg.terrain.restitution
+
+ self.gym.add_heightfield(self.sim, self.terrain.heightsamples, hf_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_trimesh(self):
+ """ Adds a triangle mesh terrain to the simulation, sets parameters based on the cfg.
+ # """
+ tm_params = gymapi.TriangleMeshParams()
+ tm_params.nb_vertices = self.terrain.vertices.shape[0]
+ tm_params.nb_triangles = self.terrain.triangles.shape[0]
+
+ tm_params.transform.p.x = -self.terrain.cfg.border_size
+ tm_params.transform.p.y = -self.terrain.cfg.border_size
+ tm_params.transform.p.z = 0.0
+ tm_params.static_friction = self.cfg.terrain.static_friction
+ tm_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ tm_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_triangle_mesh(self.sim, self.terrain.vertices.flatten(order='C'),
+ self.terrain.triangles.flatten(order='C'), tm_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_envs(self):
+ """ Creates environments:
+ 1. loads the robot URDF/MJCF asset,
+ 2. For each environment
+ 2.1 creates the environment,
+ 2.2 calls DOF and Rigid shape properties callbacks,
+ 2.3 create actor with these properties and add them to the env
+ 3. Store indices of different bodies of the robot
+ """
+ asset_path = self.cfg.asset.file.format(LOCO_MANI_GYM_ROOT_DIR=LOCO_MANI_GYM_ROOT_DIR)
+ asset_root = os.path.dirname(asset_path)
+ asset_file = os.path.basename(asset_path)
+
+ asset_options = gymapi.AssetOptions()
+ asset_options.default_dof_drive_mode = self.cfg.asset.default_dof_drive_mode
+ asset_options.collapse_fixed_joints = self.cfg.asset.collapse_fixed_joints
+ asset_options.replace_cylinder_with_capsule = self.cfg.asset.replace_cylinder_with_capsule
+ asset_options.flip_visual_attachments = self.cfg.asset.flip_visual_attachments
+ asset_options.fix_base_link = self.cfg.asset.fix_base_link
+ asset_options.density = self.cfg.asset.density
+ asset_options.angular_damping = self.cfg.asset.angular_damping
+ asset_options.linear_damping = self.cfg.asset.linear_damping
+ asset_options.max_angular_velocity = self.cfg.asset.max_angular_velocity
+ asset_options.max_linear_velocity = self.cfg.asset.max_linear_velocity
+ asset_options.armature = self.cfg.asset.armature
+ asset_options.thickness = self.cfg.asset.thickness
+ asset_options.disable_gravity = self.cfg.asset.disable_gravity
+
+ robot_asset = self.gym.load_asset(self.sim, asset_root, asset_file, asset_options)
+ self.num_dof = self.gym.get_asset_dof_count(robot_asset)
+ self.num_bodies = self.gym.get_asset_rigid_body_count(robot_asset)
+ dof_props_asset = self.gym.get_asset_dof_properties(robot_asset)
+ rigid_shape_props_asset = self.gym.get_asset_rigid_shape_properties(robot_asset)
+
+ # save body names from the asset
+ body_names = self.gym.get_asset_rigid_body_names(robot_asset)
+ self.dof_names = self.gym.get_asset_dof_names(robot_asset)
+ self.num_bodies = len(body_names)
+ self.num_dofs = len(self.dof_names)
+ feet_names = [s for s in body_names if self.cfg.asset.foot_name in s]
+ penalized_contact_names = []
+ for name in self.cfg.asset.penalize_contacts_on:
+ penalized_contact_names.extend([s for s in body_names if name in s])
+ termination_contact_names = []
+ for name in self.cfg.asset.terminate_after_contacts_on:
+ termination_contact_names.extend([s for s in body_names if name in s])
+
+ base_init_state_list = self.cfg.init_state.pos + self.cfg.init_state.rot + self.cfg.init_state.lin_vel + self.cfg.init_state.ang_vel
+ self.base_init_state = to_torch(base_init_state_list, device=self.device, requires_grad=False)
+ start_pose = gymapi.Transform()
+ start_pose.p = gymapi.Vec3(*self.base_init_state[:3])
+
+ self._get_env_origins()
+ env_lower = gymapi.Vec3(0., 0., 0.)
+ env_upper = gymapi.Vec3(0., 0., 0.)
+ self.actor_handles = []
+ self.envs = []
+ for i in range(self.num_envs):
+ # create env instance
+ env_handle = self.gym.create_env(self.sim, env_lower, env_upper, int(np.sqrt(self.num_envs)))
+ pos = self.env_origins[i].clone()
+ pos[:2] += torch_rand_float(-1., 1., (2, 1), device=self.device).squeeze(1)
+ start_pose.p = gymapi.Vec3(*pos)
+
+ rigid_shape_props = self._process_rigid_shape_props(rigid_shape_props_asset, i)
+ self.gym.set_asset_rigid_shape_properties(robot_asset, rigid_shape_props)
+ actor_handle = self.gym.create_actor(env_handle, robot_asset, start_pose, self.cfg.asset.name, i,
+ self.cfg.asset.self_collisions, 0)
+ dof_props = self._process_dof_props(dof_props_asset, i)
+ self.gym.set_actor_dof_properties(env_handle, actor_handle, dof_props)
+ body_props = self.gym.get_actor_rigid_body_properties(env_handle, actor_handle)
+ body_props = self._process_rigid_body_props(body_props, i)
+ self.gym.set_actor_rigid_body_properties(env_handle, actor_handle, body_props, recomputeInertia=True)
+ self.envs.append(env_handle)
+ self.actor_handles.append(actor_handle)
+
+ self.feet_indices = torch.zeros(len(feet_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(feet_names)):
+ self.feet_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0],
+ feet_names[i])
+
+ self.penalised_contact_indices = torch.zeros(len(penalized_contact_names), dtype=torch.long, device=self.device,
+ requires_grad=False)
+ for i in range(len(penalized_contact_names)):
+ self.penalised_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ penalized_contact_names[i])
+
+ self.termination_contact_indices = torch.zeros(len(termination_contact_names), dtype=torch.long,
+ device=self.device, requires_grad=False)
+ for i in range(len(termination_contact_names)):
+ self.termination_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ termination_contact_names[i])
+
+ def _get_env_origins(self):
+ """ Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
+ Otherwise create a grid.
+ """
+ if self.cfg.terrain.mesh_type in ["heightfield", "trimesh"]:
+ self.custom_origins = True
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # put robots at the origins defined by the terrain
+ max_init_level = self.cfg.terrain.max_init_terrain_level
+ if not self.cfg.terrain.curriculum: max_init_level = self.cfg.terrain.num_rows - 1
+ self.terrain_levels = torch.randint(0, max_init_level + 1, (self.num_envs,), device=self.device)
+ self.terrain_types = torch.div(torch.arange(self.num_envs, device=self.device),
+ (self.num_envs / self.cfg.terrain.num_cols), rounding_mode='floor').to(
+ torch.long)
+ self.max_terrain_level = self.cfg.terrain.num_rows
+ self.terrain_origins = torch.from_numpy(self.terrain.env_origins).to(self.device).to(torch.float)
+ self.env_origins[:] = self.terrain_origins[self.terrain_levels, self.terrain_types]
+ else:
+ self.custom_origins = False
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # create a grid of robots
+ num_cols = np.floor(np.sqrt(self.num_envs))
+ num_rows = np.ceil(self.num_envs / num_cols)
+ xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
+ spacing = self.cfg.env.env_spacing
+ self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
+ self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
+ self.env_origins[:, 2] = 0.
+
+ def _parse_cfg(self, cfg):
+ self.dt = self.cfg.control.decimation * self.sim_params.dt
+ self.obs_scales = self.cfg.normalization.obs_scales
+ self.reward_scales = class_to_dict(self.cfg.rewards.scales)
+ self.command_ranges = class_to_dict(self.cfg.commands.ranges)
+ if self.cfg.terrain.mesh_type not in ['heightfield', 'trimesh']:
+ self.cfg.terrain.curriculum = False
+ self.max_episode_length_s = self.cfg.env.episode_length_s
+ self.max_episode_length = np.ceil(self.max_episode_length_s / self.dt)
+
+ self.cfg.domain_rand.push_interval = np.ceil(self.cfg.domain_rand.push_interval_s / self.dt)
+
+ def _draw_debug_vis(self):
+ """ Draws visualizations for dubugging (slows down simulation a lot).
+ Default behaviour: draws height measurement points
+ """
+ # draw height lines
+ if not self.terrain.cfg.measure_heights:
+ return
+ self.gym.clear_lines(self.viewer)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ sphere_geom = gymutil.WireframeSphereGeometry(0.02, 4, 4, None, color=(1, 1, 0))
+ for i in range(self.num_envs):
+ base_pos = (self.root_states[i, :3]).cpu().numpy()
+ heights = self.measured_heights[i].cpu().numpy()
+ height_points = quat_apply_yaw(self.base_quat[i].repeat(heights.shape[0]),
+ self.height_points[i]).cpu().numpy()
+ for j in range(heights.shape[0]):
+ x = height_points[j, 0] + base_pos[0]
+ y = height_points[j, 1] + base_pos[1]
+ z = heights[j]
+ sphere_pose = gymapi.Transform(gymapi.Vec3(x, y, z), r=None)
+ gymutil.draw_lines(sphere_geom, self.gym, self.viewer, self.envs[i], sphere_pose)
+
+ def _init_height_points(self):
+ """ Returns points at which the height measurments are sampled (in base frame)
+
+ Returns:
+ [torch.Tensor]: Tensor of shape (num_envs, self.num_height_points, 3)
+ """
+ y = torch.tensor(self.cfg.terrain.measured_points_y, device=self.device, requires_grad=False)
+ x = torch.tensor(self.cfg.terrain.measured_points_x, device=self.device, requires_grad=False)
+ grid_x, grid_y = torch.meshgrid(x, y)
+
+ self.num_height_points = grid_x.numel()
+ points = torch.zeros(self.num_envs, self.num_height_points, 3, device=self.device, requires_grad=False)
+ points[:, :, 0] = grid_x.flatten()
+ points[:, :, 1] = grid_y.flatten()
+ return points
+
+ def _get_heights(self, env_ids=None):
+ """ Samples heights of the terrain at required points around each robot.
+ The points are offset by the base's position and rotated by the base's yaw
+
+ Args:
+ env_ids (List[int], optional): Subset of environments for which to return the heights. Defaults to None.
+
+ Raises:
+ NameError: [description]
+
+ Returns:
+ [type]: [description]
+ """
+ if self.cfg.terrain.mesh_type == 'plane':
+ return torch.zeros(self.num_envs, self.num_height_points, device=self.device, requires_grad=False)
+ elif self.cfg.terrain.mesh_type == 'none':
+ raise NameError("Can't measure height with terrain mesh type 'none'")
+
+ if env_ids:
+ points = quat_apply_yaw(self.base_quat[env_ids].repeat(1, self.num_height_points),
+ self.height_points[env_ids]) + (self.root_states[env_ids, :3]).unsqueeze(1)
+ else:
+ points = quat_apply_yaw(self.base_quat.repeat(1, self.num_height_points), self.height_points) + (
+ self.root_states[:, :3]).unsqueeze(1)
+
+ points += self.terrain.cfg.border_size
+ points = (points / self.terrain.cfg.horizontal_scale).long()
+ px = points[:, :, 0].view(-1)
+ py = points[:, :, 1].view(-1)
+ px = torch.clip(px, 0, self.height_samples.shape[0] - 2)
+ py = torch.clip(py, 0, self.height_samples.shape[1] - 2)
+
+ heights1 = self.height_samples[px, py]
+ heights2 = self.height_samples[px + 1, py]
+ heights3 = self.height_samples[px, py + 1]
+ heights = torch.min(heights1, heights2)
+ heights = torch.min(heights, heights3)
+
+ return heights.view(self.num_envs, -1) * self.terrain.cfg.vertical_scale
+
+ # ------------ reward functions----------------
+ def _reward_lin_vel_z(self):
+ # Penalize z axis base linear velocity
+ return torch.square(self.base_lin_vel[:, 2])
+
+ def _reward_ang_vel_xy(self):
+ # Penalize xy axes base angular velocity
+ return torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1)
+
+ def _reward_orientation(self):
+ # Penalize non flat base orientation
+ return torch.sum(torch.square(self.projected_gravity[:, :2]), dim=1)
+
+ def _reward_base_height(self):
+ # Penalize base height away from target
+ base_height = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ return torch.square(base_height - self.cfg.rewards.base_height_target)
+
+ def _reward_torques(self):
+ # Penalize torques
+ return torch.sum(torch.square(self.torques), dim=1)
+
+ def _reward_dof_vel(self):
+ # Penalize dof velocities
+ return torch.sum(torch.square(self.dof_vel), dim=1)
+
+ def _reward_dof_acc(self):
+ # Penalize dof accelerations
+ return torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1)
+
+ def _reward_action_rate(self):
+ # Penalize changes in actions
+ return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
+
+ def _reward_collision(self):
+ # Penalize collisions on selected bodies
+ return torch.sum(1. * (torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1),
+ dim=1)
+
+ def _reward_termination(self):
+ # Terminal reward / penalty
+ return self.reset_buf * ~self.time_out_buf
+
+ def _reward_dof_pos_limits(self):
+ # Penalize dof positions too close to the limit
+ out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) # lower limit
+ out_of_limits += (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.)
+ return torch.sum(out_of_limits, dim=1)
+
+ def _reward_dof_vel_limits(self):
+ # Penalize dof velocities too close to the limit
+ # clip to max error = 1 rad/s per joint to avoid huge penalties
+ return torch.sum(
+ (torch.abs(self.dof_vel) - self.dof_vel_limits * self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.),
+ dim=1)
+
+ def _reward_torque_limits(self):
+ # penalize torques too close to the limit
+ return torch.sum(
+ (torch.abs(self.torques) - self.torque_limits * self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1)
+
+ def _reward_tracking_lin_vel(self):
+ # Tracking of linear velocity commands (xy axes)
+ lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
+ return torch.exp(-lin_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_tracking_ang_vel(self):
+ # Tracking of angular velocity commands (yaw)
+ ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
+ return torch.exp(-ang_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_feet_air_time(self):
+ # Reward long steps
+ # Need to filter the contacts because the contact reporting of PhysX is unreliable on meshes
+ contact = self.contact_forces[:, self.feet_indices, 2] > 1.
+ contact_filt = torch.logical_or(contact, self.last_contacts)
+ self.last_contacts = contact
+ first_contact = (self.feet_air_time > 0.) * contact_filt
+ self.feet_air_time += self.dt
+ rew_airTime = torch.sum((self.feet_air_time - 0.5) * first_contact,
+ dim=1) # reward only on first contact with the ground
+ rew_airTime *= torch.norm(self.commands[:, :2], dim=1) > 0.1 # no reward for zero command
+ self.feet_air_time *= ~contact_filt
+ return rew_airTime
+
+ def _reward_stumble(self):
+ # Penalize feet hitting vertical surfaces
+ return torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) > \
+ 5 * torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1)
+
+ def _reward_stand_still(self):
+ # Penalize motion at zero commands
+ return torch.sum(torch.abs(self.dof_pos - self.default_dof_pos), dim=1) * (
+ torch.norm(self.commands[:, :2], dim=1) < 0.1)
+
+ def _reward_feet_contact_forces(self):
+ # penalize high contact forces
+ return torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :],
+ dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1)
diff --git a/legged_gym/envs/proto/pro_config.py b/legged_gym/envs/proto/pro_config.py
new file mode 100644
index 0000000..d681616
--- /dev/null
+++ b/legged_gym/envs/proto/pro_config.py
@@ -0,0 +1,187 @@
+from legged_gym.envs.proto.legged_robot_config_pro import LeggedRobotCfg_PRO, LeggedRobotCfgPPO_PRO
+
+class PRORoughCfg(LeggedRobotCfg_PRO):
+ class env(LeggedRobotCfg_PRO.env):
+ num_envs = 4096
+ num_actions = 8
+ num_observations = 45 #+ 187
+
+ class commands(LeggedRobotCfg_PRO.commands):
+ curriculum = False
+ max_curriculum = 1.5
+ num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
+ resampling_time = 10. # time before command are changed[s]
+ heading_command = False # if true: compute ang vel command from heading error
+
+ class ranges:
+ lin_vel_x = [-1.5, 1.5] # min max [m/s]
+ lin_vel_y = [-1.5, 1.5] # min max [m/s]
+ ang_vel_yaw = [-1.0, 1.0] # min max [rad/s]
+ heading = [-3.14, 3.14]
+
+ class terrain(LeggedRobotCfg_PRO.terrain):
+ '''mesh_type = 'plane' # "heightfield" # none, plane, heightfield or trimesh
+ horizontal_scale = 0.1 # [m]
+ vertical_scale = 0.005 # [m]
+ border_size = 25 # [m]
+ curriculum = False
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+ # rough terrain only:
+ measure_heights = False
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
+ 0.8] # 1mx1.6m rectangle (without center line)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows = 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+ # terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
+ terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
+ # trimesh only:
+ slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces'''
+
+ mesh_type = 'trimesh' # 使用三角网格表示复杂地形
+ horizontal_scale = 0.1 # 水平缩放 (米/单位)
+ vertical_scale = 0.005 # 垂直缩放 (米/单位),控制地形起伏程度
+ border_size = 25. # 边界大小 (米)
+ curriculum = False # 关闭课程学习,从一开始就在复杂地形上训练
+ static_friction = 1.0
+ dynamic_friction = 1.0
+ restitution = 0.
+
+ # 地形类型比例 [平滑斜坡, 粗糙斜坡, 上楼梯, 下楼梯, 离散障碍]
+ # 这里我们主要使用粗糙斜坡来创建略有高低不平的地形
+ terrain_proportions = [0.0, 1.0, 0.0, 0.0, 0.0] # 100% 粗糙斜坡
+
+ # 地形测量参数
+ measure_heights = False
+ measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] # 1.6m 线 (共17个点)
+ measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5] # 11条线
+ selected = False # select a unique terrain type and pass all arguments
+ terrain_kwargs = None # Dict of arguments for selected terrain
+ max_init_terrain_level = 5 # starting curriculum state
+ terrain_length = 8.
+ terrain_width = 8.
+ num_rows = 10 # number of terrain rows (levels)
+ num_cols = 20 # number of terrain cols (types)
+
+ # 地形生成参数 - 针对粗糙地形
+ difficulty_scale = 1.0 # 难度缩放因子
+ roughness = 0.3 # 粗糙度参数 (0-1),控制地形起伏程度
+ # 对于略有高低不平的地形,使用中等粗糙度
+ class init_state(LeggedRobotCfg_PRO.init_state):
+ pos = [0.0, 0.0, 0.65] # x,y,z [m]
+ default_joint_angles = { # = target angles [rad] when action = 0.0
+ 'L1_Joint': 0.0, # [rad]
+ 'L_wheel_1_Joint': 0.0, # [rad]
+ 'L2_Joint': 0.0, # [rad]
+ 'L_wheel_2_Joint': 0.0, # [rad]
+
+ 'R1_Joint': 0.0, # [rad]
+ 'R_wheel_1_Joint': 0.0, # [rad]
+ 'R2_Joint': 0.0,
+ 'R_wheel_2_Joint': 0.0,
+ }
+ init_joint_angles = { # = target angles [rad] when action = 0.0
+ 'L1_Joint': 0.0, # [rad]
+ 'L_wheel_1_Joint': 0.0, # [rad]
+ 'L2_Joint': 0.0, # [rad]
+ 'L_wheel_2_Joint': 0.0, # [rad]
+
+ 'R1_Joint': 0.0, # [rad]
+ 'R_wheel_1_Joint': 0.0, # [rad]
+ 'R2_Joint': 0.0,
+ 'R_wheel_2_Joint': 0.0,
+ }
+
+ class rewards:
+ class scales:
+ termination = -0.8
+ tracking_lin_vel = 3.0
+ tracking_ang_vel = 1.5
+ lin_vel_z = -0.1
+ ang_vel_xy = -0.05
+ orientation = 4
+ torques = -0.0001
+ dof_vel = -1e-7
+ dof_acc = -1e-7
+ base_height = -0.5
+ feet_air_time = 0
+ collision = -0.1
+ feet_stumble = -0.1
+ action_rate = -0.0002
+ stand_still = -0.01
+ dof_pos_limits = -0.9
+ arm_pos = -0.
+ hip_action_l2 = -0.1
+
+ only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
+ tracking_sigma = 0.4 # tracking reward = exp(-error^2/sigma)
+ soft_dof_pos_limit = 0.9 # percentage of urdf limits, values above this limit are penalized
+ soft_dof_vel_limit = 0.9
+ soft_torque_limit = 1.
+ base_height_target = 0.4
+ max_contact_force = 200. # forces above this value are penalized
+
+ class control(LeggedRobotCfg_PRO.control):
+ # PD Drive parameters:
+ control_type = 'P'
+
+ stiffness = {'L1_Joint': 150.0, # [rad]
+ 'L_wheel_1_Joint':50.0, # [rad]
+ 'L2_Joint': 150.0, # [rad]
+ 'L_wheel_2_Joint':50.0, # [rad]
+
+ 'R1_Joint': 150.0, # [rad]
+ 'R_wheel_1_Joint': 50.0, # [rad]
+ 'R2_Joint': 150.0,
+ 'R_wheel_2_Joint': 50.0,
+ } # [N*m/rad]
+
+ damping = { 'L1_Joint': 5.0, # [rad]
+ 'L_wheel_1_Joint': 5.0, # [rad]
+ 'L2_Joint': 5.0, # [rad]
+ 'L_wheel_2_Joint': 5.0, # [rad]
+
+ 'R1_Joint': 5.0, # [rad]
+ 'R_wheel_1_Joint': 5.0, # [rad]
+ 'R2_Joint': 5.0,
+ 'R_wheel_2_Joint': 5.0,
+ } # [N*m*s/rad]
+ # action scale: target angle = actionScale * action + defaultAngle
+ action_scale = 0.25
+ # decimation: Number of control action updates @ sim DT per policy DT
+ decimation = 4
+
+ class asset(LeggedRobotCfg_PRO.asset):
+ file = '/home/hivecore/HiveCode_rl_gym/resources/robots/Proto/urdf/proto.urdf' ######
+ name = "proto"
+ arm_name = ""
+ foot_name = "wheel"
+ wheel_name = ['L_wheel_1_Joint', 'L_wheel_2_Joint', 'R_wheel_1_Joint', 'R_wheel_2_Joint']
+ penalize_contacts_on = ["base_link"]
+ terminate_after_contacts_on = []
+ self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter "base","calf","hip","thigh"
+ replace_cylinder_with_capsule = False
+ flip_visual_attachments = False
+
+
+class PRORoughCfgPPO(LeggedRobotCfgPPO_PRO):
+ class algorithm(LeggedRobotCfgPPO_PRO.algorithm):
+ entropy_coef = 0.003
+
+ class runner(LeggedRobotCfgPPO_PRO.runner):
+ run_name = ''
+ experiment_name = 'proto'
+ resume = False
+ num_steps_per_env = 48 # per iteration
+ max_iterations = 5000
+ load_run = ''
+ checkpoint = 0
+
+
diff --git a/legged_gym/envs/proto/pro_env.py b/legged_gym/envs/proto/pro_env.py
new file mode 100644
index 0000000..2def753
--- /dev/null
+++ b/legged_gym/envs/proto/pro_env.py
@@ -0,0 +1,1036 @@
+from legged_gym import LEGGED_GYM_ROOT_DIR, envs
+import time
+from warnings import WarningMessage
+import numpy as np
+import os
+
+from isaacgym.torch_utils import *
+from isaacgym import gymtorch, gymapi, gymutil
+
+import torch
+from torch import Tensor
+from typing import Tuple, Dict
+
+from legged_gym import LEGGED_GYM_ROOT_DIR
+from legged_gym.envs.base.base_task import BaseTask
+from legged_gym.envs.proto.legged_robot_pro import LeggedRobot_PRO
+from legged_gym.utils.terrain import Terrain
+from legged_gym.utils.math import quat_apply_yaw, wrap_to_pi, torch_rand_sqrt_float
+from legged_gym.utils.isaacgym_utils import get_euler_xyz as get_euler_xyz_in_tensor
+from legged_gym.utils.helpers import class_to_dict
+from legged_gym.envs.proto.pro_config import PRORoughCfg
+
+def get_euler_xyz_tensor(quat):
+ r, p, w = get_euler_xyz(quat)
+ # stack r, p, w in dim1
+ euler_xyz = torch.stack((r, p, w), dim=1)
+ euler_xyz[euler_xyz > np.pi] -= 2 * np.pi
+ return euler_xyz
+
+class PRO_Env(LeggedRobot_PRO):
+ cfg: PRORoughCfg
+ def step(self, actions):
+ """ Apply actions, simulate, call self.post_physics_step()
+
+ Args:
+ actions (torch.Tensor): Tensor of shape (num_envs, num_actions_per_env)
+ """
+ # dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ # actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ # rigid_body_tensor = self.gym.acquire_rigid_body_state_tensor(self.sim)
+ # self.gym.refresh_dof_state_tensor(self.sim)
+ # self.gym.refresh_rigid_body_state_tensor(self.sim)
+ # self.gym.refresh_actor_root_state_tensor(self.sim)
+ # self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ # self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ # self.rigid_body_states = gymtorch.wrap_tensor(rigid_body_tensor).view(self.num_envs, -1, 13)
+ clip_actions = self.cfg.normalization.clip_actions
+ self.actions = torch.clip(actions, -clip_actions, clip_actions).to(self.device)
+ # step physics and render each frame
+ self.render()
+ for _ in range(self.cfg.control.decimation):
+ self.torques = self._compute_torques(self.actions).view(self.torques.shape)
+ self.gym.set_dof_actuation_force_tensor(self.sim, gymtorch.unwrap_tensor(self.torques))
+ self.gym.simulate(self.sim)
+ if self.device == 'cpu':
+ self.gym.fetch_results(self.sim, True)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.post_physics_step()
+
+ # return clipped obs, clipped states (None), rewards, dones and infos
+ clip_obs = self.cfg.normalization.clip_observations
+ self.obs_buf = torch.clip(self.obs_buf, -clip_obs, clip_obs)
+ if self.privileged_obs_buf is not None:
+ self.privileged_obs_buf = torch.clip(self.privileged_obs_buf, -clip_obs, clip_obs)
+ return self.obs_buf, self.privileged_obs_buf, self.rew_buf, self.reset_buf, self.extras
+
+ def post_physics_step(self):
+ """ check terminations, compute observations and rewards
+ calls self._post_physics_step_callback() for common computations
+ calls self._draw_debug_vis() if needed
+ """
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ rigid_body_tensor = self.gym.acquire_rigid_body_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ self.root_states = gymtorch.wrap_tensor(actor_root_state).view(-1, 13)
+
+ self.rigid_body_states = gymtorch.wrap_tensor(rigid_body_tensor).view(self.num_envs, -1, 13)
+ self.gripperMover_handles = self.gym.find_asset_rigid_body_index(self.robot_asset, "gripper_link")
+ self.base_handles = self.gym.find_asset_rigid_body_index(self.robot_asset, "base_link")
+ self._gripper_state = self.rigid_body_states[:, self.gripperMover_handles][:, 0:13]
+ self._gripper_pos = self.rigid_body_states[:, self.gripperMover_handles][:, 0:3]
+
+ self._gripper_rot = self.rigid_body_states[:, self.gripperMover_handles][:, 3:7]
+ self.base_pos = self.rigid_body_states[:, self.base_handles][:, 0:3]
+
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+ self._local_gripper_pos = quat_rotate_inverse(self.base_quat, self.base_pos - self._gripper_pos)
+ # get local frame quat
+ # self.local_frame_quat =
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1, 3)
+
+ self.episode_length_buf += 1
+ self.common_step_counter += 1
+
+ # prepare quantities
+ self.base_quat[:] = self.root_states[:, 3:7]
+ self.base_lin_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel[:] = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity[:] = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ self._post_physics_step_callback()
+
+ # compute observations, rewards, resets, ...
+ self.check_termination()
+ self.compute_reward()
+ # print("**self.reset_buf_buf:",self.reset_buf)
+ env_ids = self.reset_buf.nonzero(as_tuple=False).flatten()
+ self.reset_idx(env_ids)
+
+ # update_command
+
+ self.compute_observations() # in some cases a simulation step might be required to refresh some obs (for example body positions)
+
+ self.last_actions[:] = self.actions[:]
+ self.last_dof_vel[:] = self.dof_vel[:]
+ self.last_root_vel[:] = self.root_states[:, 7:13]
+
+ if self.viewer and self.enable_viewer_sync and self.debug_viz:
+ self._draw_debug_vis()
+
+ def check_termination(self):
+ """ Check if environments need to be reset
+ """
+ # print("self.contact_forces:",self.contact_forces[:, self.termination_contact_indices, :])
+ # print("self.feet_indices:",self.contact_forces[:, self.feet_indices , :])
+ self.reset_buf = torch.any(torch.norm(self.contact_forces[:, self.termination_contact_indices, :], dim=-1) > 1.,
+ dim=1)
+ self.time_out_buf = self.episode_length_buf > self.max_episode_length # no terminal reward for time-outs
+ # print("self.reset_buf_buf:",self.reset_buf)
+ self.reset_buf |= self.time_out_buf
+ contact_flag = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ self.base_contact_buf = torch.any(contact_flag.unsqueeze(1) < 0.20, dim=1)
+ self.reset_buf |= self.base_contact_buf
+
+ def reset_idx(self, env_ids):
+ """ Reset some environments.
+ Calls self._reset_dofs(env_ids), self._reset_root_states(env_ids), and self._resample_commands(env_ids)
+ [Optional] calls self._update_terrain_curriculum(env_ids), self.update_command_curriculum(env_ids) and
+ Logs episode info
+ Resets some buffers
+
+ Args:
+ env_ids (list[int]): List of environment ids which must be reset
+ """
+ if len(env_ids) == 0:
+ return
+ # update curriculum
+ if self.cfg.terrain.curriculum:
+ self._update_terrain_curriculum(env_ids)
+ # avoid updating command curriculum at each step since the maximum command is common to all envs
+ if self.cfg.commands.curriculum and (self.common_step_counter % self.max_episode_length == 0):
+ self.update_command_curriculum(env_ids)
+
+ # reset robot states
+ self._reset_dofs(env_ids)
+ self._reset_root_states(env_ids)
+
+ self._resample_commands(env_ids)
+
+ # reset buffers
+ self.last_actions[env_ids] = 0.
+ self.last_dof_vel[env_ids] = 0.
+ self.feet_air_time[env_ids] = 0.
+ self.episode_length_buf[env_ids] = 0
+ self.reset_buf[env_ids] = 1
+ # fill extras
+ self.extras["episode"] = {}
+ for key in self.episode_sums.keys():
+ self.extras["episode"]['rew_' + key] = torch.mean(
+ self.episode_sums[key][env_ids]) / self.max_episode_length_s
+ self.episode_sums[key][env_ids] = 0.
+ # log additional curriculum info
+ if self.cfg.terrain.curriculum:
+ self.extras["episode"]["terrain_level"] = torch.mean(self.terrain_levels.float())
+ if self.cfg.commands.curriculum:
+ self.extras["episode"]["max_command_x"] = self.command_ranges["lin_vel_x"][1]
+ # send timeout info to the algorithm
+ if self.cfg.env.send_timeouts:
+ self.extras["time_outs"] = self.time_out_buf
+
+ # fix reset gravity bug
+ self.base_quat[env_ids] = self.root_states[env_ids, 3:7]
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ def compute_reward(self):
+ """ Compute rewards
+ Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
+ adds each terms to the episode sums and to the total reward
+ """
+ self.rew_buf[:] = 0.
+ for i in range(len(self.reward_functions)):
+ name = self.reward_names[i]
+ rew = self.reward_functions[i]() * self.reward_scales[name]
+ self.rew_buf += rew
+ self.episode_sums[name] += rew
+ if self.cfg.rewards.only_positive_rewards:
+ self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
+ # add termination reward after clipping
+ if "termination" in self.reward_scales:
+ rew = self._reward_termination() * self.reward_scales["termination"]
+ self.rew_buf += rew
+ self.episode_sums["termination"] += rew
+
+ def compute_observations(self):
+ """ Computes observations
+ """
+
+ # self._local_gripper_pos = torch.zeros((self.num_envs,3),dtype=torch.float,device=self.device)
+
+ self.base_height_command = torch.tensor(self.cfg.rewards.base_height_target, dtype=torch.float,
+ device=self.device)
+ self.base_height_command = self.base_height_command.unsqueeze(0).repeat(self.num_envs, 1)
+ self.dof_err = self.dof_pos - self.default_dof_pos
+ self.dof_err[:, self.wheel_indices] = 0
+ self.dof_pos[:, self.wheel_indices] = 0
+ self.obs_buf = torch.cat((self.base_lin_vel * self.obs_scales.lin_vel,
+ self.base_ang_vel * self.obs_scales.ang_vel,
+ self.projected_gravity,
+ self.commands[:, :3] * self.commands_scale,
+ self.base_height_command,
+ self.dof_err * self.obs_scales.dof_pos,
+ self.dof_vel * self.obs_scales.dof_vel,
+ self.dof_pos,
+ self.actions,
+ ), dim=-1)
+ # add perceptive inputs if not blind
+ if self.cfg.terrain.measure_heights:
+ heights = torch.clip(self.root_states[:, 2].unsqueeze(1) - 0.5 - self.measured_heights, -1,
+ 1.) * self.obs_scales.height_measurements
+ self.obs_buf = torch.cat((self.obs_buf, heights), dim=-1)
+ # add noise if needed
+ if self.add_noise:
+ self.obs_buf += (2 * torch.rand_like(self.obs_buf) - 1) * self.noise_scale_vec
+
+ def create_sim(self):
+ """ Creates simulation, terrain and evironments
+ """
+ self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
+ self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine,
+ self.sim_params)
+ mesh_type = self.cfg.terrain.mesh_type
+ if mesh_type in ['heightfield', 'trimesh']:
+ self.terrain = Terrain(self.cfg.terrain, self.num_envs)
+ if mesh_type == 'plane':
+ self._create_ground_plane()
+ elif mesh_type == 'heightfield':
+ self._create_heightfield()
+ elif mesh_type == 'trimesh':
+ self._create_trimesh()
+ elif mesh_type is not None:
+ raise ValueError("Terrain mesh type not recognised. Allowed types are [None, plane, heightfield, trimesh]")
+ self._create_envs()
+
+ def set_camera(self, position, lookat):
+ """ Set camera position and direction
+ """
+ cam_pos = gymapi.Vec3(position[0], position[1], position[2])
+ cam_target = gymapi.Vec3(lookat[0], lookat[1], lookat[2])
+ self.gym.viewer_camera_look_at(self.viewer, None, cam_pos, cam_target)
+
+ # ------------- Callbacks --------------
+ def _process_rigid_shape_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the rigid shape properties of each environment.
+ Called During environment creation.
+ Base behavior: randomizes the friction of each environment
+
+ Args:
+ props (List[gymapi.RigidShapeProperties]): Properties of each shape of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [List[gymapi.RigidShapeProperties]]: Modified rigid shape properties
+ """
+ if self.cfg.domain_rand.randomize_friction:
+ if env_id == 0:
+ # prepare friction randomization
+ friction_range = self.cfg.domain_rand.friction_range
+ num_buckets = 64
+ bucket_ids = torch.randint(0, num_buckets, (self.num_envs, 1))
+ friction_buckets = torch_rand_float(friction_range[0], friction_range[1], (num_buckets, 1),
+ device='cpu')
+ self.friction_coeffs = friction_buckets[bucket_ids]
+
+ for s in range(len(props)):
+ props[s].friction = self.friction_coeffs[env_id]
+ return props
+
+ def _process_dof_props(self, props, env_id):
+ """ Callback allowing to store/change/randomize the DOF properties of each environment.
+ Called During environment creation.
+ Base behavior: stores position, velocity and torques limits defined in the URDF
+
+ Args:
+ props (numpy.array): Properties of each DOF of the asset
+ env_id (int): Environment id
+
+ Returns:
+ [numpy.array]: Modified DOF properties
+ """
+ if env_id == 0:
+ self.dof_pos_limits = torch.zeros(self.num_dof, 2, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.dof_vel_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.torque_limits = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(len(props)):
+ self.dof_pos_limits[i, 0] = props["lower"][i].item()
+ self.dof_pos_limits[i, 1] = props["upper"][i].item()
+ self.dof_vel_limits[i] = props["velocity"][i].item()
+ self.torque_limits[i] = props["effort"][i].item()
+ # soft limits
+ m = (self.dof_pos_limits[i, 0] + self.dof_pos_limits[i, 1]) / 2
+ r = self.dof_pos_limits[i, 1] - self.dof_pos_limits[i, 0]
+ self.dof_pos_limits[i, 0] = m - 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ self.dof_pos_limits[i, 1] = m + 0.5 * r * self.cfg.rewards.soft_dof_pos_limit
+ return props
+
+ def _process_rigid_body_props(self, props, env_id):
+ # if env_id==0:
+ # sum = 0
+ # for i, p in enumerate(props):
+ # sum += p.mass
+ # print(f"Mass of body {i}: {p.mass} (before randomization)")
+ # print(f"Total mass {sum} (before randomization)")
+ # randomize base mass
+ if self.cfg.domain_rand.randomize_base_mass:
+ rng = self.cfg.domain_rand.added_mass_range
+ props[0].mass += np.random.uniform(rng[0], rng[1])
+ return props
+
+ def _post_physics_step_callback(self):
+ """ Callback called before computing terminations, rewards, and observations
+ Default behaviour: Compute ang vel command based on target and heading, compute measured terrain heights and randomly push robots
+ """
+ #
+ env_ids = (self.episode_length_buf % int(self.cfg.commands.resampling_time / self.dt) == 0).nonzero(
+ as_tuple=False).flatten()
+ self._resample_commands(env_ids)
+ if self.cfg.commands.heading_command:
+ forward = quat_apply(self.base_quat, self.forward_vec)
+ heading = torch.atan2(forward[:, 1], forward[:, 0])
+ self.commands[:, 2] = torch.clip(0.5 * wrap_to_pi(self.commands[:, 3] - heading), -1., 1.)
+
+ if self.cfg.terrain.measure_heights:
+ self.measured_heights = self._get_heights()
+ if self.cfg.domain_rand.push_robots and (self.common_step_counter % self.cfg.domain_rand.push_interval == 0):
+ self._push_robots()
+
+ def _resample_commands(self, env_ids):
+ """ Randommly select commands of some environments
+
+ Args:
+ env_ids (List[int]): Environments ids for which new commands are needed
+ """
+ self.commands[env_ids, 0] = torch_rand_float(self.command_ranges["lin_vel_x"][0],
+ self.command_ranges["lin_vel_x"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ self.commands[env_ids, 1] = torch_rand_float(self.command_ranges["lin_vel_y"][0],
+ self.command_ranges["lin_vel_y"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ if self.cfg.commands.heading_command:
+ self.commands[env_ids, 3] = torch_rand_float(self.command_ranges["heading"][0],
+ self.command_ranges["heading"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+ else:
+ self.commands[env_ids, 2] = torch_rand_float(self.command_ranges["ang_vel_yaw"][0],
+ self.command_ranges["ang_vel_yaw"][1], (len(env_ids), 1),
+ device=self.device).squeeze(1)
+
+ # set small commands to zero
+ self.commands[env_ids, :2] *= (torch.norm(self.commands[env_ids, :2], dim=1) > 0.2).unsqueeze(1)
+
+ def _compute_torques(self, actions):
+ """ Compute torques from actions.
+ Actions can be interpreted as position or velocity targets given to a PD controller, or directly as scaled torques.
+ [NOTE]: torques must have the same dimension as the number of DOFs, even if some DOFs are not actuated.
+
+ Args:
+ actions (torch.Tensor): Actions
+
+ Returns:
+ [torch.Tensor]: Torques sent to the simulation
+ """
+ # pd controller
+ dof_err = self.default_dof_pos - self.dof_pos
+ dof_err[:, self.wheel_indices] = 0
+ self.dof_vel[:, self.wheel_indices] = -self.cfg.control.wheel_speed
+ dof_err[:, self.arm_indices] = self.cfg.control.arm_pos
+ actions_scaled = actions * self.cfg.control.action_scale
+ control_type = self.cfg.control.control_type
+ if control_type == "P":
+ torques = self.p_gains * (actions_scaled + dof_err) - self.d_gains * self.dof_vel
+ elif control_type == "V":
+ torques = self.p_gains * (actions_scaled - self.dof_vel) - self.d_gains * (
+ self.dof_vel - self.last_dof_vel) / self.sim_params.dt
+ elif control_type == "T":
+ torques = actions_scaled
+ else:
+ raise NameError(f"Unknown controller type: {control_type}")
+ return torch.clip(torques, -self.torque_limits, self.torque_limits)
+
+ def _reset_dofs(self, env_ids):
+ """ Resets DOF position and velocities of selected environmments
+ Positions are randomly selected within 0.5:1.5 x default positions.
+ Velocities are set to zero.
+
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ self.dof_pos[
+ env_ids] = self.init_dof_pos # * torch_rand_float(1, 1, (len(env_ids), self.num_dof), device=self.device)
+
+ self.dof_vel[env_ids] = 0.
+ # print("_reset_dofs:",env_ids)
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_dof_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.dof_state),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _reset_root_states(self, env_ids):
+ """ Resets ROOT states position and velocities of selected environmments
+ Sets base position based on the curriculum
+ Selects randomized base velocities within -0.5:0.5 [m/s, rad/s]
+ Args:
+ env_ids (List[int]): Environemnt ids
+ """
+ # base position
+ # print("_reset_root_states:",env_ids)
+ if self.custom_origins:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ self.root_states[env_ids, :2] += torch_rand_float(-1., 1., (len(env_ids), 2),
+ device=self.device) # xy position within 1m of the center
+ else:
+ self.root_states[env_ids] = self.base_init_state
+ self.root_states[env_ids, :3] += self.env_origins[env_ids]
+ # base velocities
+ self.root_states[env_ids, 7:13] = torch_rand_float(-0.5, 0.5, (len(env_ids), 6), device=self.device)
+ # torch_rand_float(-0.5, 0.5, (len(env_ids), 6), device=self.device) # [7:10]: lin vel, [10:13]: ang vel
+ env_ids_int32 = env_ids.to(dtype=torch.int32)
+ self.gym.set_actor_root_state_tensor_indexed(self.sim,
+ gymtorch.unwrap_tensor(self.root_states),
+ gymtorch.unwrap_tensor(env_ids_int32), len(env_ids_int32))
+
+ def _push_robots(self):
+ """ Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
+ """
+ max_vel = self.cfg.domain_rand.max_push_vel_xy
+ self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2),
+ device=self.device) # lin vel x/y
+ self.gym.set_actor_root_state_tensor(self.sim, gymtorch.unwrap_tensor(self.root_states))
+
+ def _update_terrain_curriculum(self, env_ids):
+ """ Implements the game-inspired curriculum.
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # Implement Terrain curriculum
+ if not self.init_done:
+ # don't change on initial reset
+ return
+ distance = torch.norm(self.root_states[env_ids, :2] - self.env_origins[env_ids, :2], dim=1)
+ # robots that walked far enough progress to harder terains
+ move_up = distance > self.terrain.env_length / 2
+ # robots that walked less than half of their required distance go to simpler terrains
+ move_down = (distance < torch.norm(self.commands[env_ids, :2],
+ dim=1) * self.max_episode_length_s * 0.5) * ~move_up
+ self.terrain_levels[env_ids] += 1 * move_up - 1 * move_down
+ # Robots that solve the last level are sent to a random one
+ self.terrain_levels[env_ids] = torch.where(self.terrain_levels[env_ids] >= self.max_terrain_level,
+ torch.randint_like(self.terrain_levels[env_ids],
+ self.max_terrain_level),
+ torch.clip(self.terrain_levels[env_ids],
+ 0)) # (the minumum level is zero)
+ self.env_origins[env_ids] = self.terrain_origins[self.terrain_levels[env_ids], self.terrain_types[env_ids]]
+
+ def update_command_curriculum(self, env_ids):
+ """ Implements a curriculum of increasing commands
+
+ Args:
+ env_ids (List[int]): ids of environments being reset
+ """
+ # If the tracking reward is above 80% of the maximum, increase the range of commands
+ if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * \
+ self.reward_scales["tracking_lin_vel"]:
+ self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5,
+ -self.cfg.commands.max_curriculum, 0.)
+ self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0.,
+ self.cfg.commands.max_curriculum)
+
+ def _get_noise_scale_vec(self, cfg):
+ """ Sets a vector used to scale the noise added to the observations.
+ [NOTE]: Must be adapted when changing the observations structure
+
+ Args:
+ cfg (Dict): Environment config file
+
+ Returns:
+ [torch.Tensor]: Vector of scales used to multiply a uniform distribution in [-1, 1]
+ """
+ noise_vec = torch.zeros_like(self.obs_buf[0])
+ self.add_noise = self.cfg.noise.add_noise
+ noise_scales = self.cfg.noise.noise_scales
+ noise_level = self.cfg.noise.noise_level
+ noise_vec[:3] = noise_scales.lin_vel * noise_level * self.obs_scales.lin_vel
+ noise_vec[3:6] = noise_scales.ang_vel * noise_level * self.obs_scales.ang_vel
+ noise_vec[6:9] = noise_scales.gravity * noise_level
+ noise_vec[9:12] = 0. # commands
+ noise_vec[12:20] = noise_scales.dof_pos * noise_level * self.obs_scales.dof_pos
+ noise_vec[20:28] = noise_scales.dof_vel * noise_level * self.obs_scales.dof_vel
+ noise_vec[28:36] = 0. # previous actions
+ if self.cfg.terrain.measure_heights:
+ noise_vec[36:235] = noise_scales.height_measurements * noise_level * self.obs_scales.height_measurements
+ return noise_vec
+
+ # ----------------------------------------
+ def _init_buffers(self):
+ """ Initialize torch tensors which will contain simulation states and processed quantities
+ """
+ # get gym GPU state tensors
+ actor_root_state = self.gym.acquire_actor_root_state_tensor(self.sim)
+ dof_state_tensor = self.gym.acquire_dof_state_tensor(self.sim)
+ net_contact_forces = self.gym.acquire_net_contact_force_tensor(self.sim)
+ self.gym.refresh_dof_state_tensor(self.sim)
+ self.gym.refresh_actor_root_state_tensor(self.sim)
+ self.gym.refresh_net_contact_force_tensor(self.sim)
+
+ # create some wrapper tensors for different slices
+ self.root_states = gymtorch.wrap_tensor(actor_root_state)
+ self.dof_state = gymtorch.wrap_tensor(dof_state_tensor)
+ self.dof_pos = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 0]
+ self.dof_vel = self.dof_state.view(self.num_envs, self.num_dof, 2)[..., 1]
+ self.base_quat = self.root_states[:, 3:7]
+ self.base_euler_xyz = get_euler_xyz_tensor(self.base_quat)
+
+ self.contact_forces = gymtorch.wrap_tensor(net_contact_forces).view(self.num_envs, -1,
+ 3) # shape: num_envs, num_bodies, xyz axis
+
+ # initialize some data used later on
+ self.common_step_counter = 0
+ self.extras = {}
+ self.noise_scale_vec = self._get_noise_scale_vec(self.cfg)
+ self.gravity_vec = to_torch(get_axis_params(-1., self.up_axis_idx), device=self.device).repeat(
+ (self.num_envs, 1))
+ self.forward_vec = to_torch([1., 0., 0.], device=self.device).repeat((self.num_envs, 1))
+ self.torques = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.p_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.d_gains = torch.zeros(self.num_actions, dtype=torch.float, device=self.device, requires_grad=False)
+ self.actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_actions = torch.zeros(self.num_envs, self.num_actions, dtype=torch.float, device=self.device,
+ requires_grad=False)
+ self.last_dof_vel = torch.zeros_like(self.dof_vel)
+ self.last_root_vel = torch.zeros_like(self.root_states[:, 7:13])
+ self.commands = torch.zeros(self.num_envs, self.cfg.commands.num_commands, dtype=torch.float,
+ device=self.device, requires_grad=False) # x vel, y vel, yaw vel, heading
+ self.commands_scale = torch.tensor([self.obs_scales.lin_vel, self.obs_scales.lin_vel, self.obs_scales.ang_vel],
+ device=self.device, requires_grad=False, ) # TODO change this
+ self.feet_air_time = torch.zeros(self.num_envs, self.feet_indices.shape[0], dtype=torch.float,
+ device=self.device, requires_grad=False)
+ self.last_contacts = torch.zeros(self.num_envs, len(self.feet_indices), dtype=torch.bool, device=self.device,
+ requires_grad=False)
+ self.base_lin_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 7:10])
+ self.base_ang_vel = quat_rotate_inverse(self.base_quat, self.root_states[:, 10:13])
+ self.projected_gravity = quat_rotate_inverse(self.base_quat, self.gravity_vec)
+ self._local_cube_object_pos = torch.zeros((self.num_envs, 3), dtype=torch.float, device=self.device)
+ self._local_cube_object_pos = torch.tensor([0.25, 0.004, 0.3], dtype=torch.float, device=self.device).repeat(
+ self.num_envs, 1)
+ if self.cfg.terrain.measure_heights:
+ self.height_points = self._init_height_points()
+ self.measured_heights = 0
+
+ # joint positions offsets and PD gains
+ self.default_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ self.init_dof_pos = torch.zeros(self.num_dof, dtype=torch.float, device=self.device, requires_grad=False)
+ for i in range(self.num_dofs):
+ name = self.dof_names[i]
+ angle = self.cfg.init_state.default_joint_angles[name]
+ self.default_dof_pos[i] = angle
+ self.init_dof_pos[i] = self.cfg.init_state.init_joint_angles[name]
+ found = False
+ for dof_name in self.cfg.control.stiffness.keys():
+ if dof_name in name:
+ self.p_gains[i] = self.cfg.control.stiffness[dof_name]
+ self.d_gains[i] = self.cfg.control.damping[dof_name]
+ found = True
+ if not found:
+ self.p_gains[i] = 0.
+ self.d_gains[i] = 0.
+ if self.cfg.control.control_type in ["P", "V"]:
+ print(f"PD gain of joint {name} were not defined, setting them to zero")
+ self.default_dof_pos = self.default_dof_pos.unsqueeze(0)
+ self.init_dof_pos = self.init_dof_pos.unsqueeze(0)
+
+ def _prepare_reward_function(self):
+ """ Prepares a list of reward functions, whcih will be called to compute the total reward.
+ Looks for self._reward_, where are names of all non zero reward scales in the cfg.
+ """
+ # remove zero scales + multiply non-zero ones by dt
+ for key in list(self.reward_scales.keys()):
+ scale = self.reward_scales[key]
+ if scale == 0:
+ self.reward_scales.pop(key)
+ else:
+ self.reward_scales[key] *= self.dt
+ # prepare list of functions
+ self.reward_functions = []
+ self.reward_names = []
+ for name, scale in self.reward_scales.items():
+ if name == "termination":
+ continue
+ self.reward_names.append(name)
+ name = '_reward_' + name
+ self.reward_functions.append(getattr(self, name))
+
+ # reward episode sums
+ self.episode_sums = {
+ name: torch.zeros(self.num_envs, dtype=torch.float, device=self.device, requires_grad=False)
+ for name in self.reward_scales.keys()}
+
+ def _create_ground_plane(self):
+ """ Adds a ground plane to the simulation, sets friction and restitution based on the cfg.
+ """
+ plane_params = gymapi.PlaneParams()
+ plane_params.normal = gymapi.Vec3(0.0, 0.0, 1.0)
+ plane_params.static_friction = self.cfg.terrain.static_friction
+ plane_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ plane_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_ground(self.sim, plane_params)
+
+ def _create_heightfield(self):
+ """ Adds a heightfield terrain to the simulation, sets parameters based on the cfg.
+ """
+ hf_params = gymapi.HeightFieldParams()
+ hf_params.column_scale = self.terrain.cfg.horizontal_scale
+ hf_params.row_scale = self.terrain.cfg.horizontal_scale
+ hf_params.vertical_scale = self.terrain.cfg.vertical_scale
+ hf_params.nbRows = self.terrain.tot_cols
+ hf_params.nbColumns = self.terrain.tot_rows
+ hf_params.transform.p.x = -self.terrain.cfg.border_size
+ hf_params.transform.p.y = -self.terrain.cfg.border_size
+ hf_params.transform.p.z = 0.0
+ hf_params.static_friction = self.cfg.terrain.static_friction
+ hf_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ hf_params.restitution = self.cfg.terrain.restitution
+
+ self.gym.add_heightfield(self.sim, self.terrain.heightsamples, hf_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_trimesh(self):
+ """ Adds a triangle mesh terrain to the simulation, sets parameters based on the cfg.
+ # """
+ tm_params = gymapi.TriangleMeshParams()
+ tm_params.nb_vertices = self.terrain.vertices.shape[0]
+ tm_params.nb_triangles = self.terrain.triangles.shape[0]
+
+ tm_params.transform.p.x = -self.terrain.cfg.border_size
+ tm_params.transform.p.y = -self.terrain.cfg.border_size
+ tm_params.transform.p.z = 0.0
+ tm_params.static_friction = self.cfg.terrain.static_friction
+ tm_params.dynamic_friction = self.cfg.terrain.dynamic_friction
+ tm_params.restitution = self.cfg.terrain.restitution
+ self.gym.add_triangle_mesh(self.sim, self.terrain.vertices.flatten(order='C'),
+ self.terrain.triangles.flatten(order='C'), tm_params)
+ self.height_samples = torch.tensor(self.terrain.heightsamples).view(self.terrain.tot_rows,
+ self.terrain.tot_cols).to(self.device)
+
+ def _create_envs(self):
+ """ Creates environments:
+ 1. loads the robot URDF/MJCF asset,
+ 2. For each environment
+ 2.1 creates the environment,
+ 2.2 calls DOF and Rigid shape properties callbacks,
+ 2.3 create actor with these properties and add them to the env
+ 3. Store indices of different bodies of the robot
+ """
+ asset_path = self.cfg.asset.file.format(LEGGED_GYM_ROOT_DIR=LEGGED_GYM_ROOT_DIR)
+ asset_root = os.path.dirname(asset_path)
+ asset_file = os.path.basename(asset_path)
+
+ asset_options = gymapi.AssetOptions()
+ asset_options.default_dof_drive_mode = self.cfg.asset.default_dof_drive_mode
+ asset_options.collapse_fixed_joints = self.cfg.asset.collapse_fixed_joints
+ asset_options.replace_cylinder_with_capsule = self.cfg.asset.replace_cylinder_with_capsule
+ asset_options.flip_visual_attachments = self.cfg.asset.flip_visual_attachments
+ asset_options.fix_base_link = self.cfg.asset.fix_base_link
+ asset_options.density = self.cfg.asset.density
+ asset_options.angular_damping = self.cfg.asset.angular_damping
+ asset_options.linear_damping = self.cfg.asset.linear_damping
+ asset_options.max_angular_velocity = self.cfg.asset.max_angular_velocity
+ asset_options.max_linear_velocity = self.cfg.asset.max_linear_velocity
+ asset_options.armature = self.cfg.asset.armature
+ asset_options.thickness = self.cfg.asset.thickness
+ asset_options.disable_gravity = self.cfg.asset.disable_gravity
+
+ robot_asset = self.gym.load_asset(self.sim, asset_root, asset_file, asset_options)
+ self.robot_asset = robot_asset
+ self.num_dof = self.gym.get_asset_dof_count(robot_asset)
+ self.num_bodies = self.gym.get_asset_rigid_body_count(robot_asset)
+ dof_props_asset = self.gym.get_asset_dof_properties(robot_asset)
+ rigid_shape_props_asset = self.gym.get_asset_rigid_shape_properties(robot_asset)
+
+ # save body names from the asset
+ body_names = self.gym.get_asset_rigid_body_names(robot_asset)
+ self.dof_names = self.gym.get_asset_dof_names(robot_asset)
+ self.num_bodies = len(body_names)
+ self.num_dofs = len(self.dof_names)
+ feet_names = [s for s in body_names if self.cfg.asset.foot_name in s]
+ penalized_contact_names = []
+ for name in self.cfg.asset.penalize_contacts_on:
+ penalized_contact_names.extend([s for s in body_names if name in s])
+ termination_contact_names = []
+ for name in self.cfg.asset.terminate_after_contacts_on:
+ termination_contact_names.extend([s for s in body_names if name in s])
+ wheel_names = []
+ for name in self.cfg.asset.wheel_name:
+ wheel_names.extend([s for s in self.dof_names if name in s])
+ arm_names = []
+ for name in self.cfg.asset.arm_name:
+ arm_names.extend([s for s in self.dof_names if name in s])
+ print("###self.rigid_body names:", body_names)
+ print("###self.dof names:", self.dof_names)
+ print("###penalized_contact_names:", penalized_contact_names)
+ print("###termination_contact_names:", termination_contact_names)
+ print("###feet_names:", feet_names)
+ print("###wheels name:", wheel_names)
+ print("###arm_names:", arm_names)
+
+ base_init_state_list = self.cfg.init_state.pos + self.cfg.init_state.rot + self.cfg.init_state.lin_vel + self.cfg.init_state.ang_vel
+ self.base_init_state = to_torch(base_init_state_list, device=self.device, requires_grad=False)
+ start_pose = gymapi.Transform()
+ start_pose.p = gymapi.Vec3(*self.base_init_state[:3])
+
+ self._get_env_origins()
+ env_lower = gymapi.Vec3(0., 0., 0.)
+ env_upper = gymapi.Vec3(0., 0., 0.)
+ self.actor_handles = []
+ self.envs = []
+ for i in range(self.num_envs):
+ # create env instance
+ env_handle = self.gym.create_env(self.sim, env_lower, env_upper, int(np.sqrt(self.num_envs)))
+ pos = self.env_origins[i].clone()
+ pos[:2] += torch_rand_float(-1., 1., (2, 1), device=self.device).squeeze(1)
+ start_pose.p = gymapi.Vec3(*pos)
+
+ rigid_shape_props = self._process_rigid_shape_props(rigid_shape_props_asset, i)
+ self.gym.set_asset_rigid_shape_properties(robot_asset, rigid_shape_props)
+ actor_handle = self.gym.create_actor(env_handle, robot_asset, start_pose, self.cfg.asset.name, i,
+ self.cfg.asset.self_collisions, 0)
+ dof_props = self._process_dof_props(dof_props_asset, i)
+ self.gym.set_actor_dof_properties(env_handle, actor_handle, dof_props)
+ body_props = self.gym.get_actor_rigid_body_properties(env_handle, actor_handle)
+ body_props = self._process_rigid_body_props(body_props, i)
+ self.gym.set_actor_rigid_body_properties(env_handle, actor_handle, body_props, recomputeInertia=True)
+ self.envs.append(env_handle)
+ self.actor_handles.append(actor_handle)
+
+ self.feet_indices = torch.zeros(len(feet_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(feet_names)):
+ self.feet_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0], self.actor_handles[0],
+ feet_names[i])
+
+ self.penalised_contact_indices = torch.zeros(len(penalized_contact_names), dtype=torch.long, device=self.device,
+ requires_grad=False)
+ for i in range(len(penalized_contact_names)):
+ self.penalised_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ penalized_contact_names[i])
+
+ self.termination_contact_indices = torch.zeros(len(termination_contact_names), dtype=torch.long,
+ device=self.device, requires_grad=False)
+ for i in range(len(termination_contact_names)):
+ print("termination_contact_names[i]", termination_contact_names[i])
+ self.termination_contact_indices[i] = self.gym.find_actor_rigid_body_handle(self.envs[0],
+ self.actor_handles[0],
+ termination_contact_names[i])
+ print("termination_contact_names[i]", termination_contact_names[i], "indice[i]:",
+ self.termination_contact_indices[i])
+
+ self.wheel_indices = torch.zeros(len(wheel_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(wheel_names)):
+ self.wheel_indices[i] = self.gym.find_actor_dof_handle(self.envs[0], self.actor_handles[0], wheel_names[i])
+
+ self.arm_indices = torch.zeros(len(arm_names), dtype=torch.long, device=self.device, requires_grad=False)
+ for i in range(len(arm_names)):
+ self.arm_indices[i] = self.gym.find_actor_dof_handle(self.envs[0], self.actor_handles[0], arm_names[i])
+
+ def _get_env_origins(self):
+ """ Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
+ Otherwise create a grid.
+ """
+ if self.cfg.terrain.mesh_type in ["heightfield", "trimesh"]:
+ self.custom_origins = True
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # put robots at the origins defined by the terrain
+ max_init_level = self.cfg.terrain.max_init_terrain_level
+ if not self.cfg.terrain.curriculum: max_init_level = self.cfg.terrain.num_rows - 1
+ self.terrain_levels = torch.randint(0, max_init_level + 1, (self.num_envs,), device=self.device)
+ self.terrain_types = torch.div(torch.arange(self.num_envs, device=self.device),
+ (self.num_envs / self.cfg.terrain.num_cols), rounding_mode='floor').to(
+ torch.long)
+ self.max_terrain_level = self.cfg.terrain.num_rows
+ self.terrain_origins = torch.from_numpy(self.terrain.env_origins).to(self.device).to(torch.float)
+ self.env_origins[:] = self.terrain_origins[self.terrain_levels, self.terrain_types]
+ else:
+ self.custom_origins = False
+ self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
+ # create a grid of robots
+ num_cols = np.floor(np.sqrt(self.num_envs))
+ num_rows = np.ceil(self.num_envs / num_cols)
+ xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
+ spacing = self.cfg.env.env_spacing
+ self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
+ self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
+ self.env_origins[:, 2] = 0.
+
+ def _parse_cfg(self, cfg):
+ self.dt = self.cfg.control.decimation * self.sim_params.dt
+ self.obs_scales = self.cfg.normalization.obs_scales
+ self.reward_scales = class_to_dict(self.cfg.rewards.scales)
+ self.command_ranges = class_to_dict(self.cfg.commands.ranges)
+ if self.cfg.terrain.mesh_type not in ['heightfield', 'trimesh']:
+ self.cfg.terrain.curriculum = False
+ self.max_episode_length_s = self.cfg.env.episode_length_s
+ self.max_episode_length = np.ceil(self.max_episode_length_s / self.dt)
+
+ self.cfg.domain_rand.push_interval = np.ceil(self.cfg.domain_rand.push_interval_s / self.dt)
+
+ def _draw_debug_vis(self):
+ """ Draws visualizations for dubugging (slows down simulation a lot).
+ Default behaviour: draws height measurement points
+ """
+ # draw height lines
+ if not self.terrain.cfg.measure_heights:
+ return
+ self.gym.clear_lines(self.viewer)
+ self.gym.refresh_rigid_body_state_tensor(self.sim)
+ sphere_geom = gymutil.WireframeSphereGeometry(0.02, 4, 4, None, color=(1, 1, 0))
+ for i in range(self.num_envs):
+ base_pos = (self.root_states[i, :3]).cpu().numpy()
+ heights = self.measured_heights[i].cpu().numpy()
+ height_points = quat_apply_yaw(self.base_quat[i].repeat(heights.shape[0]),
+ self.height_points[i]).cpu().numpy()
+ for j in range(heights.shape[0]):
+ x = height_points[j, 0] + base_pos[0]
+ y = height_points[j, 1] + base_pos[1]
+ z = heights[j]
+ sphere_pose = gymapi.Transform(gymapi.Vec3(x, y, z), r=None)
+ gymutil.draw_lines(sphere_geom, self.gym, self.viewer, self.envs[i], sphere_pose)
+
+ def _init_height_points(self):
+ """ Returns points at which the height measurments are sampled (in base frame)
+
+ Returns:
+ [torch.Tensor]: Tensor of shape (num_envs, self.num_height_points, 3)
+ """
+ y = torch.tensor(self.cfg.terrain.measured_points_y, device=self.device, requires_grad=False)
+ x = torch.tensor(self.cfg.terrain.measured_points_x, device=self.device, requires_grad=False)
+ grid_x, grid_y = torch.meshgrid(x, y)
+
+ self.num_height_points = grid_x.numel()
+ points = torch.zeros(self.num_envs, self.num_height_points, 3, device=self.device, requires_grad=False)
+ points[:, :, 0] = grid_x.flatten()
+ points[:, :, 1] = grid_y.flatten()
+ return points
+
+ def _get_heights(self, env_ids=None):
+ """ Samples heights of the terrain at required points around each robot.
+ The points are offset by the base's position and rotated by the base's yaw
+
+ Args:
+ env_ids (List[int], optional): Subset of environments for which to return the heights. Defaults to None.
+
+ Raises:
+ NameError: [description]
+
+ Returns:
+ [type]: [description]
+ """
+ if self.cfg.terrain.mesh_type == 'plane':
+ return torch.zeros(self.num_envs, self.num_height_points, device=self.device, requires_grad=False)
+ elif self.cfg.terrain.mesh_type == 'none':
+ raise NameError("Can't measure height with terrain mesh type 'none'")
+
+ if env_ids:
+ points = quat_apply_yaw(self.base_quat[env_ids].repeat(1, self.num_height_points),
+ self.height_points[env_ids]) + (self.root_states[env_ids, :3]).unsqueeze(1)
+ else:
+ points = quat_apply_yaw(self.base_quat.repeat(1, self.num_height_points), self.height_points) + (
+ self.root_states[:, :3]).unsqueeze(1)
+
+ points += self.terrain.cfg.border_size
+ points = (points / self.terrain.cfg.horizontal_scale).long()
+ px = points[:, :, 0].view(-1)
+ py = points[:, :, 1].view(-1)
+ px = torch.clip(px, 0, self.height_samples.shape[0] - 2)
+ py = torch.clip(py, 0, self.height_samples.shape[1] - 2)
+
+ heights1 = self.height_samples[px, py]
+ heights2 = self.height_samples[px + 1, py]
+ heights3 = self.height_samples[px, py + 1]
+ heights = torch.min(heights1, heights2)
+ heights = torch.min(heights, heights3)
+
+ return heights.view(self.num_envs, -1) * self.terrain.cfg.vertical_scale
+
+ # ------------ reward functions----------------
+ def _reward_lin_vel_z(self):
+ # Penalize z axis base linear velocity
+ return torch.square(self.base_lin_vel[:, 2])
+
+ def _reward_ang_vel_xy(self):
+ # Penalize xy axes base angular velocity
+ return torch.sum(torch.square(self.base_ang_vel[:, :2]), dim=1)
+
+ def _reward_orientation(self):
+ # Penalize non flat base orientation
+ quat_mismatch = torch.exp(-torch.sum(torch.abs(self.base_euler_xyz[:, :2]), dim=1) * 10)
+ orientation = torch.exp(-torch.norm(self.projected_gravity[:, :2], dim=1) * 20)
+ return (quat_mismatch + orientation) / 2.
+
+ def _reward_base_height(self):
+ # Penalize base height away from target
+ base_height = torch.mean(self.root_states[:, 2].unsqueeze(1) - self.measured_heights, dim=1)
+ return torch.square(base_height - self.cfg.rewards.base_height_target)
+
+ def _reward_torques(self):
+ # Penalize torques
+ return torch.sum(torch.square(self.torques), dim=1)
+
+ def _reward_dof_vel(self):
+ # Penalize dof velocities
+ self.dof_vel[:, self.wheel_indices] = 0
+ return torch.sum(torch.square(self.dof_vel), dim=1)
+
+ def _reward_dof_acc(self):
+ # Penalize dof accelerations
+ return torch.sum(torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1)
+
+ def _reward_action_rate(self):
+ # Penalize changes in actions
+ return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
+
+ def _reward_collision(self):
+ # Penalize collisions on selected bodies
+ return torch.sum(1. * (torch.norm(self.contact_forces[:, self.penalised_contact_indices, :], dim=-1) > 0.1),
+ dim=1)
+
+ def _reward_termination(self):
+ # Terminal reward / penalty
+ return self.reset_buf * ~self.time_out_buf
+
+ def _reward_dof_pos_limits(self):
+ # Penalize dof positions too close to the limit
+ out_of_limits = -(self.dof_pos - self.dof_pos_limits[:, 0]).clip(max=0.) # lower limit
+ out_of_limits += (self.dof_pos - self.dof_pos_limits[:, 1]).clip(min=0.)
+ return torch.sum(out_of_limits, dim=1)
+
+ def _reward_dof_vel_limits(self):
+ # Penalize dof velocities too close to the limit
+ # clip to max error = 1 rad/s per joint to avoid huge penalties
+ return torch.sum(
+ (torch.abs(self.dof_vel) - self.dof_vel_limits * self.cfg.rewards.soft_dof_vel_limit).clip(min=0., max=1.),
+ dim=1)
+
+ def _reward_torque_limits(self):
+ # penalize torques too close to the limit
+ return torch.sum(
+ (torch.abs(self.torques) - self.torque_limits * self.cfg.rewards.soft_torque_limit).clip(min=0.), dim=1)
+
+ def _reward_tracking_lin_vel(self):
+ # Tracking of linear velocity commands (xy axes)
+ lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
+ return torch.exp(-lin_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_tracking_ang_vel(self):
+ # Tracking of angular velocity commands (yaw)
+ ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
+ return torch.exp(-ang_vel_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_feet_air_time(self):
+ # Reward long steps
+ # Need to filter the contacts because the contact reporting of PhysX is unreliable on meshes
+ contact = self.contact_forces[:, self.feet_indices, 2] > 1.
+ contact_filt = torch.logical_or(contact, self.last_contacts)
+ self.last_contacts = contact
+ first_contact = (self.feet_air_time > 0.) * contact_filt
+ self.feet_air_time += self.dt
+ rew_airTime = torch.sum((self.feet_air_time - 0.5) * first_contact,
+ dim=1) # reward only on first contact with the ground
+ rew_airTime *= torch.norm(self.commands[:, :2], dim=1) > 0.1 # no reward for zero command
+ self.feet_air_time *= ~contact_filt
+ return rew_airTime
+
+ def _reward_feet_stumble(self):
+ # Penalize feet hitting vertical surfaces
+ return torch.any(torch.norm(self.contact_forces[:, self.feet_indices, :2], dim=2) > \
+ 5 * torch.abs(self.contact_forces[:, self.feet_indices, 2]), dim=1)
+
+ def _reward_stand_still(self):
+ # Penalize motion at zero commands
+ dof_err = self.dof_pos - self.default_dof_pos
+ dof_err[:, self.wheel_indices] = 0
+ dof_err[:, self.arm_indices] = 0
+ return torch.sum(torch.abs(dof_err), dim=1) * (torch.norm(self.commands[:, :2], dim=1) < 0.1)
+
+ def _reward_feet_contact_forces(self):
+ # penalize high contact forces
+ return torch.sum((torch.norm(self.contact_forces[:, self.feet_indices, :],
+ dim=-1) - self.cfg.rewards.max_contact_force).clip(min=0.), dim=1)
+
+ def _reward_orientation_quat(self):
+ # Penalize non flat base orientation
+
+ orientation_error = torch.sum(torch.square(self.root_states[:, :7] - self.base_init_state[0:7]), dim=1)
+ return torch.exp(-orientation_error / self.cfg.rewards.tracking_sigma)
+
+ def _reward_hip_action_l2(self):
+ action_l2 = torch.sum(self.actions[:, [0, 4]] ** 2, dim=1)
+ # self.episode_metric_sums['leg_action_l2'] += action_l2
+ return action_l2
+
diff --git a/legged_gym/scripts/play.py b/legged_gym/scripts/play.py
new file mode 100644
index 0000000..a0b26ea
--- /dev/null
+++ b/legged_gym/scripts/play.py
@@ -0,0 +1,52 @@
+import sys
+from legged_gym import LEGGED_GYM_ROOT_DIR
+import os
+import sys
+from legged_gym import LEGGED_GYM_ROOT_DIR
+
+import isaacgym
+from legged_gym.envs import *
+from legged_gym.utils import get_args, export_policy_as_jit, task_registry, Logger
+
+import numpy as np
+import torch
+
+
+def play(args):
+ env_cfg, train_cfg = task_registry.get_cfgs(name=args.task)
+ # override some parameters for testing
+ env_cfg.terrain.mesh_type = 'trimesh' ###rencent change
+ env_cfg.env.num_envs = min(env_cfg.env.num_envs, 48)
+ env_cfg.terrain.num_rows = 5
+ env_cfg.terrain.num_cols = 5
+ env_cfg.terrain.curriculum = False
+ env_cfg.noise.add_noise = False
+ env_cfg.domain_rand.randomize_friction = False
+ env_cfg.domain_rand.push_robots = False
+
+ env_cfg.env.test = True
+
+ # prepare environment
+ env, _ = task_registry.make_env(name=args.task, args=args, env_cfg=env_cfg)
+ obs = env.get_observations()
+ # load policy
+ train_cfg.runner.resume = True
+ ppo_runner, train_cfg = task_registry.make_alg_runner(env=env, name=args.task, args=args, train_cfg=train_cfg)
+ policy = ppo_runner.get_inference_policy(device=env.device)
+
+ # export policy as a jit module (used to run it from C++)
+ if EXPORT_POLICY:
+ path = os.path.join(LEGGED_GYM_ROOT_DIR, 'logs', train_cfg.runner.experiment_name, 'exported', 'policies')
+ export_policy_as_jit(ppo_runner.alg.actor_critic, path)
+ print('Exported policy as jit script to: ', path)
+
+ for i in range(10*int(env.max_episode_length)):
+ actions = policy(obs.detach())
+ obs, _, rews, dones, infos = env.step(actions.detach())
+
+if __name__ == '__main__':
+ EXPORT_POLICY = True
+ RECORD_FRAMES = False
+ MOVE_CAMERA = False
+ args = get_args()
+ play(args)
diff --git a/legged_gym/scripts/train.py b/legged_gym/scripts/train.py
new file mode 100644
index 0000000..3c6d400
--- /dev/null
+++ b/legged_gym/scripts/train.py
@@ -0,0 +1,23 @@
+import os
+import numpy as np
+from datetime import datetime
+import sys
+
+import isaacgym
+from legged_gym.envs import *
+from legged_gym.utils import get_args, task_registry
+import torch
+
+def train(args):
+ env, env_cfg = task_registry.make_env(name=args.task, args=args)
+ ppo_runner, train_cfg = task_registry.make_alg_runner(env=env, name=args.task, args=args)
+ ppo_runner.learn(num_learning_iterations=train_cfg.runner.max_iterations, init_at_random_ep_len=True)
+""" # 覆盖地形配置
+ env_cfg.terrain.terrain_proportions = [0.0, 1.0, 0.0, 0.0, 0.0] # 100% 粗糙斜坡
+ env_cfg.terrain.curriculum = False # 关闭课程学习
+ env_cfg.terrain.roughness = 0.3 # 设置中等粗糙度
+ env_cfg.terrain.vertical_scale = 0.005 # 设置垂直缩放 """
+
+if __name__ == '__main__':
+ args = get_args()
+ train(args)
diff --git a/legged_gym/utils/__init__.py b/legged_gym/utils/__init__.py
new file mode 100644
index 0000000..4f793a9
--- /dev/null
+++ b/legged_gym/utils/__init__.py
@@ -0,0 +1,5 @@
+from .helpers import class_to_dict, get_load_path, get_args, export_policy_as_jit, set_seed, update_class_from_dict
+from .task_registry import task_registry
+from .logger import Logger
+from .math import *
+from .terrain import Terrain
\ No newline at end of file
diff --git a/legged_gym/utils/helpers.py b/legged_gym/utils/helpers.py
new file mode 100644
index 0000000..dc231af
--- /dev/null
+++ b/legged_gym/utils/helpers.py
@@ -0,0 +1,191 @@
+import os
+import copy
+import torch
+import numpy as np
+import random
+from isaacgym import gymapi
+from isaacgym import gymutil
+
+from legged_gym import LEGGED_GYM_ROOT_DIR, LEGGED_GYM_ENVS_DIR
+
+def class_to_dict(obj) -> dict:
+ if not hasattr(obj,"__dict__"):
+ return obj
+ result = {}
+ for key in dir(obj):
+ if key.startswith("_"):
+ continue
+ element = []
+ val = getattr(obj, key)
+ if isinstance(val, list):
+ for item in val:
+ element.append(class_to_dict(item))
+ else:
+ element = class_to_dict(val)
+ result[key] = element
+ return result
+
+def update_class_from_dict(obj, dict):
+ for key, val in dict.items():
+ attr = getattr(obj, key, None)
+ if isinstance(attr, type):
+ update_class_from_dict(attr, val)
+ else:
+ setattr(obj, key, val)
+ return
+
+def set_seed(seed):
+ if seed == -1:
+ seed = np.random.randint(0, 10000)
+ print("Setting seed: {}".format(seed))
+
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ os.environ['PYTHONHASHSEED'] = str(seed)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+def parse_sim_params(args, cfg):
+ # code from Isaac Gym Preview 2
+ # initialize sim params
+ sim_params = gymapi.SimParams()
+
+ # set some values from args
+ if args.physics_engine == gymapi.SIM_FLEX:
+ if args.device != "cpu":
+ print("WARNING: Using Flex with GPU instead of PHYSX!")
+ elif args.physics_engine == gymapi.SIM_PHYSX:
+ sim_params.physx.use_gpu = args.use_gpu
+ sim_params.physx.num_subscenes = args.subscenes
+ sim_params.use_gpu_pipeline = args.use_gpu_pipeline
+
+ # if sim options are provided in cfg, parse them and update/override above:
+ if "sim" in cfg:
+ gymutil.parse_sim_config(cfg["sim"], sim_params)
+
+ # Override num_threads if passed on the command line
+ if args.physics_engine == gymapi.SIM_PHYSX and args.num_threads > 0:
+ sim_params.physx.num_threads = args.num_threads
+
+ return sim_params
+
+def get_load_path(root, load_run=-1, checkpoint=-1):
+ try:
+ runs = os.listdir(root)
+ #TODO sort by date to handle change of month
+ runs.sort()
+ if 'exported' in runs: runs.remove('exported')
+ last_run = os.path.join(root, runs[-1])
+ except:
+ raise ValueError("No runs in this directory: " + root)
+ if load_run==-1:
+ load_run = last_run
+ else:
+ load_run = os.path.join(root, load_run)
+
+ if checkpoint==-1:
+ models = [file for file in os.listdir(load_run) if 'model' in file]
+ models.sort(key=lambda m: '{0:0>15}'.format(m))
+ model = models[-1]
+ else:
+ model = "model_{}.pt".format(checkpoint)
+
+ load_path = os.path.join(load_run, model)
+ return load_path
+
+def update_cfg_from_args(env_cfg, cfg_train, args):
+ # seed
+ if env_cfg is not None:
+ # num envs
+ if args.num_envs is not None:
+ env_cfg.env.num_envs = args.num_envs
+ if cfg_train is not None:
+ if args.seed is not None:
+ cfg_train.seed = args.seed
+ # alg runner parameters
+ if args.max_iterations is not None:
+ cfg_train.runner.max_iterations = args.max_iterations
+ if args.resume:
+ cfg_train.runner.resume = args.resume
+ if args.experiment_name is not None:
+ cfg_train.runner.experiment_name = args.experiment_name
+ if args.run_name is not None:
+ cfg_train.runner.run_name = args.run_name
+ if args.load_run is not None:
+ cfg_train.runner.load_run = args.load_run
+ if args.checkpoint is not None:
+ cfg_train.runner.checkpoint = args.checkpoint
+
+ return env_cfg, cfg_train
+
+def get_args():
+ custom_parameters = [
+ {"name": "--task", "type": str, "default": "go2", "help": "Resume training or start testing from a checkpoint. Overrides config file if provided."},
+ {"name": "--resume", "action": "store_true", "default": False, "help": "Resume training from a checkpoint"},
+ {"name": "--experiment_name", "type": str, "help": "Name of the experiment to run or load. Overrides config file if provided."},
+ {"name": "--run_name", "type": str, "help": "Name of the run. Overrides config file if provided."},
+ {"name": "--load_run", "type": str, "help": "Name of the run to load when resume=True. If -1: will load the last run. Overrides config file if provided."},
+ {"name": "--checkpoint", "type": int, "help": "Saved model checkpoint number. If -1: will load the last checkpoint. Overrides config file if provided."},
+
+ {"name": "--headless", "action": "store_true", "default": False, "help": "Force display off at all times"},
+ {"name": "--horovod", "action": "store_true", "default": False, "help": "Use horovod for multi-gpu training"},
+ {"name": "--rl_device", "type": str, "default": "cuda:0", "help": 'Device used by the RL algorithm, (cpu, gpu, cuda:0, cuda:1 etc..)'},
+ {"name": "--num_envs", "type": int, "help": "Number of environments to create. Overrides config file if provided."},
+ {"name": "--seed", "type": int, "help": "Random seed. Overrides config file if provided."},
+ {"name": "--max_iterations", "type": int, "help": "Maximum number of training iterations. Overrides config file if provided."},
+ ]
+ # parse arguments
+ args = gymutil.parse_arguments(
+ description="RL Policy",
+ custom_parameters=custom_parameters)
+
+ # name allignment
+ args.sim_device_id = args.compute_device_id
+ args.sim_device = args.sim_device_type
+ if args.sim_device=='cuda':
+ args.sim_device += f":{args.sim_device_id}"
+ return args
+
+def export_policy_as_jit(actor_critic, path):
+ if hasattr(actor_critic, 'memory_a'):
+ # assumes LSTM: TODO add GRU
+ exporter = PolicyExporterLSTM(actor_critic)
+ exporter.export(path)
+ else:
+ os.makedirs(path, exist_ok=True)
+ path = os.path.join(path, 'policy_1.pt')
+ model = copy.deepcopy(actor_critic.actor).to('cpu')
+ traced_script_module = torch.jit.script(model)
+ traced_script_module.save(path)
+
+
+class PolicyExporterLSTM(torch.nn.Module):
+ def __init__(self, actor_critic):
+ super().__init__()
+ self.actor = copy.deepcopy(actor_critic.actor)
+ self.is_recurrent = actor_critic.is_recurrent
+ self.memory = copy.deepcopy(actor_critic.memory_a.rnn)
+ self.memory.cpu()
+ self.register_buffer(f'hidden_state', torch.zeros(self.memory.num_layers, 1, self.memory.hidden_size))
+ self.register_buffer(f'cell_state', torch.zeros(self.memory.num_layers, 1, self.memory.hidden_size))
+
+ def forward(self, x):
+ out, (h, c) = self.memory(x.unsqueeze(0), (self.hidden_state, self.cell_state))
+ self.hidden_state[:] = h
+ self.cell_state[:] = c
+ return self.actor(out.squeeze(0))
+
+ @torch.jit.export
+ def reset_memory(self):
+ self.hidden_state[:] = 0.
+ self.cell_state[:] = 0.
+
+ def export(self, path):
+ os.makedirs(path, exist_ok=True)
+ path = os.path.join(path, 'policy_lstm_1.pt')
+ self.to('cpu')
+ traced_script_module = torch.jit.script(self)
+ traced_script_module.save(path)
+
+
diff --git a/legged_gym/utils/isaacgym_utils.py b/legged_gym/utils/isaacgym_utils.py
new file mode 100644
index 0000000..a92c0df
--- /dev/null
+++ b/legged_gym/utils/isaacgym_utils.py
@@ -0,0 +1,30 @@
+import os
+import numpy as np
+import random
+import torch
+
+@torch.jit.script
+def copysign(a, b):
+ # type: (float, Tensor) -> Tensor
+ a = torch.tensor(a, device=b.device, dtype=torch.float).repeat(b.shape[0])
+ return torch.abs(a) * torch.sign(b)
+def get_euler_xyz(q):
+ qx, qy, qz, qw = 0, 1, 2, 3
+ # roll (x-axis rotation)
+ sinr_cosp = 2.0 * (q[:, qw] * q[:, qx] + q[:, qy] * q[:, qz])
+ cosr_cosp = q[:, qw] * q[:, qw] - q[:, qx] * \
+ q[:, qx] - q[:, qy] * q[:, qy] + q[:, qz] * q[:, qz]
+ roll = torch.atan2(sinr_cosp, cosr_cosp)
+
+ # pitch (y-axis rotation)
+ sinp = 2.0 * (q[:, qw] * q[:, qy] - q[:, qz] * q[:, qx])
+ pitch = torch.where(
+ torch.abs(sinp) >= 1, copysign(np.pi / 2.0, sinp), torch.asin(sinp))
+
+ # yaw (z-axis rotation)
+ siny_cosp = 2.0 * (q[:, qw] * q[:, qz] + q[:, qx] * q[:, qy])
+ cosy_cosp = q[:, qw] * q[:, qw] + q[:, qx] * \
+ q[:, qx] - q[:, qy] * q[:, qy] - q[:, qz] * q[:, qz]
+ yaw = torch.atan2(siny_cosp, cosy_cosp)
+
+ return torch.stack((roll, pitch, yaw), dim=-1)
diff --git a/legged_gym/utils/logger.py b/legged_gym/utils/logger.py
new file mode 100644
index 0000000..2052d18
--- /dev/null
+++ b/legged_gym/utils/logger.py
@@ -0,0 +1,39 @@
+import numpy as np
+from collections import defaultdict
+from multiprocessing import Process, Value
+
+class Logger:
+ def __init__(self, dt):
+ self.state_log = defaultdict(list)
+ self.rew_log = defaultdict(list)
+ self.dt = dt
+ self.num_episodes = 0
+ self.plot_process = None
+
+ def log_state(self, key, value):
+ self.state_log[key].append(value)
+
+ def log_states(self, dict):
+ for key, value in dict.items():
+ self.log_state(key, value)
+
+ def log_rewards(self, dict, num_episodes):
+ for key, value in dict.items():
+ if 'rew' in key:
+ self.rew_log[key].append(value.item() * num_episodes)
+ self.num_episodes += num_episodes
+
+ def reset(self):
+ self.state_log.clear()
+ self.rew_log.clear()
+
+ def print_rewards(self):
+ print("Average rewards per second:")
+ for key, values in self.rew_log.items():
+ mean = np.sum(np.array(values)) / self.num_episodes
+ print(f" - {key}: {mean}")
+ print(f"Total number of episodes: {self.num_episodes}")
+
+ def __del__(self):
+ if self.plot_process is not None:
+ self.plot_process.kill()
\ No newline at end of file
diff --git a/legged_gym/utils/math.py b/legged_gym/utils/math.py
new file mode 100644
index 0000000..887007f
--- /dev/null
+++ b/legged_gym/utils/math.py
@@ -0,0 +1,26 @@
+import torch
+from torch import Tensor
+import numpy as np
+from isaacgym.torch_utils import quat_apply, normalize
+from typing import Tuple
+
+# @ torch.jit.script
+def quat_apply_yaw(quat, vec):
+ quat_yaw = quat.clone().view(-1, 4)
+ quat_yaw[:, :2] = 0.
+ quat_yaw = normalize(quat_yaw)
+ return quat_apply(quat_yaw, vec)
+
+# @ torch.jit.script
+def wrap_to_pi(angles):
+ angles %= 2*np.pi
+ angles -= 2*np.pi * (angles > np.pi)
+ return angles
+
+# @ torch.jit.script
+def torch_rand_sqrt_float(lower, upper, shape, device):
+ # type: (float, float, Tuple[int, int], str) -> Tensor
+ r = 2*torch.rand(*shape, device=device) - 1
+ r = torch.where(r<0., -torch.sqrt(-r), torch.sqrt(r))
+ r = (r + 1.) / 2.
+ return (upper - lower) * r + lower
\ No newline at end of file
diff --git a/legged_gym/utils/task_registry.py b/legged_gym/utils/task_registry.py
new file mode 100644
index 0000000..5d9324f
--- /dev/null
+++ b/legged_gym/utils/task_registry.py
@@ -0,0 +1,129 @@
+import os
+from datetime import datetime
+from typing import Tuple
+import torch
+import numpy as np
+import sys
+
+from rsl_rl.env import VecEnv
+from rsl_rl.runners import OnPolicyRunner
+
+from legged_gym import LEGGED_GYM_ROOT_DIR, LEGGED_GYM_ENVS_DIR
+from .helpers import get_args, update_cfg_from_args, class_to_dict, get_load_path, set_seed, parse_sim_params
+from legged_gym.envs.base.legged_robot_config import LeggedRobotCfg, LeggedRobotCfgPPO
+
+class TaskRegistry():
+ def __init__(self):
+ self.task_classes = {}
+ self.env_cfgs = {}
+ self.train_cfgs = {}
+
+ def register(self, name: str, task_class: VecEnv, env_cfg: LeggedRobotCfg, train_cfg: LeggedRobotCfgPPO):
+ self.task_classes[name] = task_class
+ self.env_cfgs[name] = env_cfg
+ self.train_cfgs[name] = train_cfg
+
+ def get_task_class(self, name: str) -> VecEnv:
+ return self.task_classes[name]
+
+ def get_cfgs(self, name) -> Tuple[LeggedRobotCfg, LeggedRobotCfgPPO]:
+ train_cfg = self.train_cfgs[name]
+ env_cfg = self.env_cfgs[name]
+ # copy seed
+ env_cfg.seed = train_cfg.seed
+ return env_cfg, train_cfg
+
+ def make_env(self, name, args=None, env_cfg=None) -> Tuple[VecEnv, LeggedRobotCfg]:
+ """ Creates an environment either from a registered namme or from the provided config file.
+
+ Args:
+ name (string): Name of a registered env.
+ args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
+ env_cfg (Dict, optional): Environment config file used to override the registered config. Defaults to None.
+
+ Raises:
+ ValueError: Error if no registered env corresponds to 'name'
+
+ Returns:
+ isaacgym.VecTaskPython: The created environment
+ Dict: the corresponding config file
+ """
+ # if no args passed get command line arguments
+ if args is None:
+ args = get_args()
+ # check if there is a registered env with that name
+ if name in self.task_classes:
+ task_class = self.get_task_class(name)
+ else:
+ raise ValueError(f"Task with name: {name} was not registered")
+ if env_cfg is None:
+ # load config files
+ env_cfg, _ = self.get_cfgs(name)
+ # override cfg from args (if specified)
+ env_cfg, _ = update_cfg_from_args(env_cfg, None, args)
+ set_seed(env_cfg.seed)
+ # parse sim params (convert to dict first)
+ sim_params = {"sim": class_to_dict(env_cfg.sim)}
+ sim_params = parse_sim_params(args, sim_params)
+ env = task_class( cfg=env_cfg,
+ sim_params=sim_params,
+ physics_engine=args.physics_engine,
+ sim_device=args.sim_device,
+ headless=args.headless)
+ return env, env_cfg
+
+ def make_alg_runner(self, env, name=None, args=None, train_cfg=None, log_root="default") -> Tuple[OnPolicyRunner, LeggedRobotCfgPPO]:
+ """ Creates the training algorithm either from a registered namme or from the provided config file.
+
+ Args:
+ env (isaacgym.VecTaskPython): The environment to train (TODO: remove from within the algorithm)
+ name (string, optional): Name of a registered env. If None, the config file will be used instead. Defaults to None.
+ args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
+ train_cfg (Dict, optional): Training config file. If None 'name' will be used to get the config file. Defaults to None.
+ log_root (str, optional): Logging directory for Tensorboard. Set to 'None' to avoid logging (at test time for example).
+ Logs will be saved in /_. Defaults to "default"=/logs/.
+
+ Raises:
+ ValueError: Error if neither 'name' or 'train_cfg' are provided
+ Warning: If both 'name' or 'train_cfg' are provided 'name' is ignored
+
+ Returns:
+ PPO: The created algorithm
+ Dict: the corresponding config file
+ """
+ # if no args passed get command line arguments
+ if args is None:
+ args = get_args()
+ # if config files are passed use them, otherwise load from the name
+ if train_cfg is None:
+ if name is None:
+ raise ValueError("Either 'name' or 'train_cfg' must be not None")
+ # load config files
+ _, train_cfg = self.get_cfgs(name)
+ else:
+ if name is not None:
+ print(f"'train_cfg' provided -> Ignoring 'name={name}'")
+ # override cfg from args (if specified)
+ _, train_cfg = update_cfg_from_args(None, train_cfg, args)
+
+ if log_root=="default":
+ log_root = os.path.join(LEGGED_GYM_ROOT_DIR, 'logs', train_cfg.runner.experiment_name)
+ log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
+ elif log_root is None:
+ log_dir = None
+ else:
+ log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
+
+ train_cfg_dict = class_to_dict(train_cfg)
+ runner = OnPolicyRunner(env, train_cfg_dict, log_dir, device=args.rl_device)
+ #save resume path before creating a new log_dir
+ resume = train_cfg.runner.resume
+ if resume:
+ # load previously trained model
+ resume_path = get_load_path(log_root, load_run=train_cfg.runner.load_run, checkpoint=train_cfg.runner.checkpoint)
+ print(f"Loading model from: {resume_path}")
+ runner.load(resume_path)
+ return runner, train_cfg
+
+# make global task registry
+task_registry = TaskRegistry()
\ No newline at end of file
diff --git a/legged_gym/utils/terrain.py b/legged_gym/utils/terrain.py
new file mode 100644
index 0000000..b984586
--- /dev/null
+++ b/legged_gym/utils/terrain.py
@@ -0,0 +1,157 @@
+import numpy as np
+from numpy.random import choice
+from scipy import interpolate
+
+from isaacgym import terrain_utils
+from legged_gym.envs.base.legged_robot_config import LeggedRobotCfg
+
+class Terrain:
+ def __init__(self, cfg: LeggedRobotCfg.terrain, num_robots) -> None:
+
+ self.cfg = cfg
+ self.num_robots = num_robots
+ self.type = cfg.mesh_type
+ if self.type in ["none", 'plane']:
+ return
+ self.env_length = cfg.terrain_length
+ self.env_width = cfg.terrain_width
+ self.proportions = [np.sum(cfg.terrain_proportions[:i+1]) for i in range(len(cfg.terrain_proportions))]
+
+ self.cfg.num_sub_terrains = cfg.num_rows * cfg.num_cols
+ self.env_origins = np.zeros((cfg.num_rows, cfg.num_cols, 3))
+
+ self.width_per_env_pixels = int(self.env_width / cfg.horizontal_scale)
+ self.length_per_env_pixels = int(self.env_length / cfg.horizontal_scale)
+
+ self.border = int(cfg.border_size/self.cfg.horizontal_scale)
+ self.tot_cols = int(cfg.num_cols * self.width_per_env_pixels) + 2 * self.border
+ self.tot_rows = int(cfg.num_rows * self.length_per_env_pixels) + 2 * self.border
+
+ self.height_field_raw = np.zeros((self.tot_rows , self.tot_cols), dtype=np.int16)
+ if cfg.curriculum:
+ self.curiculum()
+ elif cfg.selected:
+ self.selected_terrain()
+ else:
+ self.randomized_terrain()
+
+ self.heightsamples = self.height_field_raw
+ if self.type=="trimesh":
+ self.vertices, self.triangles = terrain_utils.convert_heightfield_to_trimesh( self.height_field_raw,
+ self.cfg.horizontal_scale,
+ self.cfg.vertical_scale,
+ self.cfg.slope_treshold)
+
+ def randomized_terrain(self):
+ for k in range(self.cfg.num_sub_terrains):
+ # Env coordinates in the world
+ (i, j) = np.unravel_index(k, (self.cfg.num_rows, self.cfg.num_cols))
+
+ choice = np.random.uniform(0, 1)
+ difficulty = np.random.choice([0.5, 0.75, 0.9])
+ terrain = self.make_terrain(choice, difficulty)
+ self.add_terrain_to_map(terrain, i, j)
+
+ def curiculum(self):
+ for j in range(self.cfg.num_cols):
+ for i in range(self.cfg.num_rows):
+ difficulty = i / self.cfg.num_rows
+ choice = j / self.cfg.num_cols + 0.001
+
+ terrain = self.make_terrain(choice, difficulty)
+ self.add_terrain_to_map(terrain, i, j)
+
+ def selected_terrain(self):
+ terrain_type = self.cfg.terrain_kwargs.pop('type')
+ for k in range(self.cfg.num_sub_terrains):
+ # Env coordinates in the world
+ (i, j) = np.unravel_index(k, (self.cfg.num_rows, self.cfg.num_cols))
+
+ terrain = terrain_utils.SubTerrain("terrain",
+ width=self.width_per_env_pixels,
+ length=self.width_per_env_pixels,
+ vertical_scale=self.vertical_scale,
+ horizontal_scale=self.horizontal_scale)
+
+ eval(terrain_type)(terrain, **self.cfg.terrain_kwargs.terrain_kwargs)
+ self.add_terrain_to_map(terrain, i, j)
+
+ def make_terrain(self, choice, difficulty):
+ terrain = terrain_utils.SubTerrain( "terrain",
+ width=self.width_per_env_pixels,
+ length=self.width_per_env_pixels,
+ vertical_scale=self.cfg.vertical_scale,
+ horizontal_scale=self.cfg.horizontal_scale)
+ slope = difficulty * 0.4
+ step_height = 0.05 + 0.18 * difficulty
+ discrete_obstacles_height = 0.05 + difficulty * 0.2
+ stepping_stones_size = 1.5 * (1.05 - difficulty)
+ stone_distance = 0.05 if difficulty==0 else 0.1
+ gap_size = 1. * difficulty
+ pit_depth = 1. * difficulty
+ if choice < self.proportions[0]:
+ if choice < self.proportions[0]/ 2:
+ slope *= -1
+ terrain_utils.pyramid_sloped_terrain(terrain, slope=slope, platform_size=3.)
+ elif choice < self.proportions[1]:
+ terrain_utils.pyramid_sloped_terrain(terrain, slope=slope, platform_size=3.)
+ terrain_utils.random_uniform_terrain(terrain, min_height=-0.05, max_height=0.05, step=0.005, downsampled_scale=0.2)
+ elif choice < self.proportions[3]:
+ if choice
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/resources/robots/FHrobot/urdf/FHrobot.xml b/resources/robots/FHrobot/urdf/FHrobot.xml
new file mode 100644
index 0000000..5d862aa
--- /dev/null
+++ b/resources/robots/FHrobot/urdf/FHrobot.xml
@@ -0,0 +1,350 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/resources/robots/Proto/meshes/L1_Link.STL b/resources/robots/Proto/meshes/L1_Link.STL
new file mode 100755
index 0000000..c014c28
Binary files /dev/null and b/resources/robots/Proto/meshes/L1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/L2_Link.STL b/resources/robots/Proto/meshes/L2_Link.STL
new file mode 100644
index 0000000..cac82b8
Binary files /dev/null and b/resources/robots/Proto/meshes/L2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/LW1_Link.STL b/resources/robots/Proto/meshes/LW1_Link.STL
new file mode 100755
index 0000000..8e50f75
Binary files /dev/null and b/resources/robots/Proto/meshes/LW1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/LW2_Link.STL b/resources/robots/Proto/meshes/LW2_Link.STL
new file mode 100755
index 0000000..f086587
Binary files /dev/null and b/resources/robots/Proto/meshes/LW2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/R1_Link.STL b/resources/robots/Proto/meshes/R1_Link.STL
new file mode 100755
index 0000000..ecdaee0
Binary files /dev/null and b/resources/robots/Proto/meshes/R1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/R2_Link.STL b/resources/robots/Proto/meshes/R2_Link.STL
new file mode 100755
index 0000000..6a287a9
Binary files /dev/null and b/resources/robots/Proto/meshes/R2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/RW1_Link.STL b/resources/robots/Proto/meshes/RW1_Link.STL
new file mode 100755
index 0000000..ee1870c
Binary files /dev/null and b/resources/robots/Proto/meshes/RW1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/RW2_Link.STL b/resources/robots/Proto/meshes/RW2_Link.STL
new file mode 100755
index 0000000..0fd90cd
Binary files /dev/null and b/resources/robots/Proto/meshes/RW2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SL1_Link.STL b/resources/robots/Proto/meshes/SL1_Link.STL
new file mode 100755
index 0000000..ce062d3
Binary files /dev/null and b/resources/robots/Proto/meshes/SL1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SL2_Link.STL b/resources/robots/Proto/meshes/SL2_Link.STL
new file mode 100755
index 0000000..71d3626
Binary files /dev/null and b/resources/robots/Proto/meshes/SL2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SL3_Link.STL b/resources/robots/Proto/meshes/SL3_Link.STL
new file mode 100755
index 0000000..0a84fca
Binary files /dev/null and b/resources/robots/Proto/meshes/SL3_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SL4_Link.STL b/resources/robots/Proto/meshes/SL4_Link.STL
new file mode 100755
index 0000000..fb33045
Binary files /dev/null and b/resources/robots/Proto/meshes/SL4_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SR1_Link.STL b/resources/robots/Proto/meshes/SR1_Link.STL
new file mode 100755
index 0000000..953addf
Binary files /dev/null and b/resources/robots/Proto/meshes/SR1_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SR2_Link.STL b/resources/robots/Proto/meshes/SR2_Link.STL
new file mode 100755
index 0000000..aabf1c7
Binary files /dev/null and b/resources/robots/Proto/meshes/SR2_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SR3_Link.STL b/resources/robots/Proto/meshes/SR3_Link.STL
new file mode 100755
index 0000000..9e2329d
Binary files /dev/null and b/resources/robots/Proto/meshes/SR3_Link.STL differ
diff --git a/resources/robots/Proto/meshes/SR4_Link.STL b/resources/robots/Proto/meshes/SR4_Link.STL
new file mode 100755
index 0000000..2db716d
Binary files /dev/null and b/resources/robots/Proto/meshes/SR4_Link.STL differ
diff --git a/resources/robots/Proto/meshes/base_link.STL b/resources/robots/Proto/meshes/base_link.STL
new file mode 100755
index 0000000..5ec066c
Binary files /dev/null and b/resources/robots/Proto/meshes/base_link.STL differ
diff --git a/resources/robots/Proto/meshes/hip_Link.STL b/resources/robots/Proto/meshes/hip_Link.STL
new file mode 100755
index 0000000..e37baf2
Binary files /dev/null and b/resources/robots/Proto/meshes/hip_Link.STL differ
diff --git a/resources/robots/Proto/urdf/proto.urdf b/resources/robots/Proto/urdf/proto.urdf
new file mode 100755
index 0000000..f2d79dc
--- /dev/null
+++ b/resources/robots/Proto/urdf/proto.urdf
@@ -0,0 +1,1034 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/resources/robots/Proto/urdf/proto.xml b/resources/robots/Proto/urdf/proto.xml
new file mode 100644
index 0000000..5e998c5
--- /dev/null
+++ b/resources/robots/Proto/urdf/proto.xml
@@ -0,0 +1,187 @@
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/resources/robots/Proto/urdf/proto_ori.urdf b/resources/robots/Proto/urdf/proto_ori.urdf
new file mode 100755
index 0000000..505bedb
--- /dev/null
+++ b/resources/robots/Proto/urdf/proto_ori.urdf
@@ -0,0 +1,1026 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/resources/robots/Proto/urdf/proto_ori.xml b/resources/robots/Proto/urdf/proto_ori.xml
new file mode 100644
index 0000000..1752611
--- /dev/null
+++ b/resources/robots/Proto/urdf/proto_ori.xml
@@ -0,0 +1,143 @@
+
+
+
+
+
+
diff --git a/rsl_rl/.gitignore b/rsl_rl/.gitignore
new file mode 100644
index 0000000..34f42f1
--- /dev/null
+++ b/rsl_rl/.gitignore
@@ -0,0 +1,12 @@
+# IDEs
+.idea
+
+# builds
+*.egg-info
+
+# cache
+__pycache__
+.pytest_cache
+
+# vs code
+.vscode
\ No newline at end of file
diff --git a/rsl_rl/LICENSE b/rsl_rl/LICENSE
new file mode 100644
index 0000000..01d9567
--- /dev/null
+++ b/rsl_rl/LICENSE
@@ -0,0 +1,30 @@
+Copyright (c) 2021, ETH Zurich, Nikita Rudin
+Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without modification,
+are permitted provided that the following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice,
+ this list of conditions and the following disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+3. Neither the name of the copyright holder nor the names of its contributors
+ may be used to endorse or promote products derived from this software without
+ specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
+ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
+WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
+ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
+(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
+LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
+ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
+(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
+SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+
+See licenses/dependencies for license information of dependencies of this package.
\ No newline at end of file
diff --git a/rsl_rl/README.md b/rsl_rl/README.md
new file mode 100644
index 0000000..2dbf3bd
--- /dev/null
+++ b/rsl_rl/README.md
@@ -0,0 +1,26 @@
+# RSL RL
+Fast and simple implementation of RL algorithms, designed to run fully on GPU.
+This code is an evolution of `rl-pytorch` provided with NVIDIA's Isaac GYM.
+
+Only PPO is implemented for now. More algorithms will be added later.
+Contributions are welcome.
+
+## Setup
+
+```
+git clone https://github.com/leggedrobotics/rsl_rl
+cd rsl_rl
+pip install -e .
+```
+
+### Useful Links ###
+Example use case: https://github.com/leggedrobotics/legged_gym
+Project website: https://leggedrobotics.github.io/legged_gym/
+Paper: https://arxiv.org/abs/2109.11978
+
+**Maintainer**: Nikita Rudin
+**Affiliation**: Robotic Systems Lab, ETH Zurich & NVIDIA
+**Contact**: rudinn@ethz.ch
+
+
+
diff --git a/rsl_rl/licenses/dependencies/numpy_license.txt b/rsl_rl/licenses/dependencies/numpy_license.txt
new file mode 100644
index 0000000..84e9bfe
--- /dev/null
+++ b/rsl_rl/licenses/dependencies/numpy_license.txt
@@ -0,0 +1,30 @@
+Copyright (c) 2005-2021, NumPy Developers.
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are
+met:
+
+ * Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+ * Redistributions in binary form must reproduce the above
+ copyright notice, this list of conditions and the following
+ disclaimer in the documentation and/or other materials provided
+ with the distribution.
+
+ * Neither the name of the NumPy Developers nor the names of any
+ contributors may be used to endorse or promote products derived
+ from this software without specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
+LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
+A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
+OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
+SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
+LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
+DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
+THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
+(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/rsl_rl/licenses/dependencies/torch_license.txt b/rsl_rl/licenses/dependencies/torch_license.txt
new file mode 100644
index 0000000..244b249
--- /dev/null
+++ b/rsl_rl/licenses/dependencies/torch_license.txt
@@ -0,0 +1,73 @@
+From PyTorch:
+
+Copyright (c) 2016- Facebook, Inc (Adam Paszke)
+Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
+Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
+Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
+Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
+Copyright (c) 2011-2013 NYU (Clement Farabet)
+Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
+Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
+Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
+
+From Caffe2:
+
+Copyright (c) 2016-present, Facebook Inc. All rights reserved.
+
+All contributions by Facebook:
+Copyright (c) 2016 Facebook Inc.
+
+All contributions by Google:
+Copyright (c) 2015 Google Inc.
+All rights reserved.
+
+All contributions by Yangqing Jia:
+Copyright (c) 2015 Yangqing Jia
+All rights reserved.
+
+All contributions by Kakao Brain:
+Copyright 2019-2020 Kakao Brain
+
+All contributions from Caffe:
+Copyright(c) 2013, 2014, 2015, the respective contributors
+All rights reserved.
+
+All other contributions:
+Copyright(c) 2015, 2016 the respective contributors
+All rights reserved.
+
+Caffe2 uses a copyright model similar to Caffe: each contributor holds
+copyright over their contributions to Caffe2. The project versioning records
+all such contribution and copyright details. If a contributor wants to further
+mark their specific copyright on a particular contribution, they should
+indicate their copyright solely in the commit message of the change when it is
+committed.
+
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+1. Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+3. Neither the names of Facebook, Deepmind Technologies, NYU, NEC Laboratories America
+ and IDIAP Research Institute nor the names of its contributors may be
+ used to endorse or promote products derived from this software without
+ specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
+ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
+LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
+CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
+SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
+INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
+CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
+ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
+POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/__init__.py b/rsl_rl/rsl_rl/__init__.py
new file mode 100644
index 0000000..466dfca
--- /dev/null
+++ b/rsl_rl/rsl_rl/__init__.py
@@ -0,0 +1,29 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/algorithms/__init__.py b/rsl_rl/rsl_rl/algorithms/__init__.py
new file mode 100644
index 0000000..6f94329
--- /dev/null
+++ b/rsl_rl/rsl_rl/algorithms/__init__.py
@@ -0,0 +1,31 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+from .ppo import PPO
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/algorithms/ppo.py b/rsl_rl/rsl_rl/algorithms/ppo.py
new file mode 100644
index 0000000..2017042
--- /dev/null
+++ b/rsl_rl/rsl_rl/algorithms/ppo.py
@@ -0,0 +1,187 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import torch
+import torch.nn as nn
+import torch.optim as optim
+
+from rsl_rl.modules import ActorCritic
+from rsl_rl.storage import RolloutStorage
+
+class PPO:
+ actor_critic: ActorCritic
+ def __init__(self,
+ actor_critic,
+ num_learning_epochs=1,
+ num_mini_batches=1,
+ clip_param=0.2,
+ gamma=0.998,
+ lam=0.95,
+ value_loss_coef=1.0,
+ entropy_coef=0.0,
+ learning_rate=1e-3,
+ max_grad_norm=1.0,
+ use_clipped_value_loss=True,
+ schedule="fixed",
+ desired_kl=0.01,
+ device='cpu',
+ ):
+
+ self.device = device
+
+ self.desired_kl = desired_kl
+ self.schedule = schedule
+ self.learning_rate = learning_rate
+
+ # PPO components
+ self.actor_critic = actor_critic
+ self.actor_critic.to(self.device)
+ self.storage = None # initialized later
+ self.optimizer = optim.Adam(self.actor_critic.parameters(), lr=learning_rate)
+ self.transition = RolloutStorage.Transition()
+
+ # PPO parameters
+ self.clip_param = clip_param
+ self.num_learning_epochs = num_learning_epochs
+ self.num_mini_batches = num_mini_batches
+ self.value_loss_coef = value_loss_coef
+ self.entropy_coef = entropy_coef
+ self.gamma = gamma
+ self.lam = lam
+ self.max_grad_norm = max_grad_norm
+ self.use_clipped_value_loss = use_clipped_value_loss
+
+ def init_storage(self, num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape):
+ self.storage = RolloutStorage(num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape, self.device)
+
+ def test_mode(self):
+ self.actor_critic.test()
+
+ def train_mode(self):
+ self.actor_critic.train()
+
+ def act(self, obs, critic_obs):
+ if self.actor_critic.is_recurrent:
+ self.transition.hidden_states = self.actor_critic.get_hidden_states()
+ # Compute the actions and values
+ self.transition.actions = self.actor_critic.act(obs).detach()
+ self.transition.values = self.actor_critic.evaluate(critic_obs).detach()
+ self.transition.actions_log_prob = self.actor_critic.get_actions_log_prob(self.transition.actions).detach()
+ self.transition.action_mean = self.actor_critic.action_mean.detach()
+ self.transition.action_sigma = self.actor_critic.action_std.detach()
+ # need to record obs and critic_obs before env.step()
+ self.transition.observations = obs
+ self.transition.critic_observations = critic_obs
+ return self.transition.actions
+
+ def process_env_step(self, rewards, dones, infos):
+ self.transition.rewards = rewards.clone()
+ self.transition.dones = dones
+ # Bootstrapping on time outs
+ if 'time_outs' in infos:
+ self.transition.rewards += self.gamma * torch.squeeze(self.transition.values * infos['time_outs'].unsqueeze(1).to(self.device), 1)
+
+ # Record the transition
+ self.storage.add_transitions(self.transition)
+ self.transition.clear()
+ self.actor_critic.reset(dones)
+
+ def compute_returns(self, last_critic_obs):
+ last_values= self.actor_critic.evaluate(last_critic_obs).detach()
+ self.storage.compute_returns(last_values, self.gamma, self.lam)
+
+ def update(self):
+ mean_value_loss = 0
+ mean_surrogate_loss = 0
+ if self.actor_critic.is_recurrent:
+ generator = self.storage.reccurent_mini_batch_generator(self.num_mini_batches, self.num_learning_epochs)
+ else:
+ generator = self.storage.mini_batch_generator(self.num_mini_batches, self.num_learning_epochs)
+ for obs_batch, critic_obs_batch, actions_batch, target_values_batch, advantages_batch, returns_batch, old_actions_log_prob_batch, \
+ old_mu_batch, old_sigma_batch, hid_states_batch, masks_batch in generator:
+
+
+ self.actor_critic.act(obs_batch, masks=masks_batch, hidden_states=hid_states_batch[0])
+ actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch)
+ value_batch = self.actor_critic.evaluate(critic_obs_batch, masks=masks_batch, hidden_states=hid_states_batch[1])
+ mu_batch = self.actor_critic.action_mean
+ sigma_batch = self.actor_critic.action_std
+ entropy_batch = self.actor_critic.entropy
+
+ # KL
+ if self.desired_kl != None and self.schedule == 'adaptive':
+ with torch.inference_mode():
+ kl = torch.sum(
+ torch.log(sigma_batch / old_sigma_batch + 1.e-5) + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch)) / (2.0 * torch.square(sigma_batch)) - 0.5, axis=-1)
+ kl_mean = torch.mean(kl)
+
+ if kl_mean > self.desired_kl * 2.0:
+ self.learning_rate = max(1e-5, self.learning_rate / 1.5)
+ elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0:
+ self.learning_rate = min(1e-2, self.learning_rate * 1.5)
+
+ for param_group in self.optimizer.param_groups:
+ param_group['lr'] = self.learning_rate
+
+
+ # Surrogate loss
+ ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch))
+ surrogate = -torch.squeeze(advantages_batch) * ratio
+ surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(ratio, 1.0 - self.clip_param,
+ 1.0 + self.clip_param)
+ surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
+
+ # Value function loss
+ if self.use_clipped_value_loss:
+ value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(-self.clip_param,
+ self.clip_param)
+ value_losses = (value_batch - returns_batch).pow(2)
+ value_losses_clipped = (value_clipped - returns_batch).pow(2)
+ value_loss = torch.max(value_losses, value_losses_clipped).mean()
+ else:
+ value_loss = (returns_batch - value_batch).pow(2).mean()
+
+ loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()
+
+ # Gradient step
+ self.optimizer.zero_grad()
+ loss.backward()
+ nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm)
+ self.optimizer.step()
+
+ mean_value_loss += value_loss.item()
+ mean_surrogate_loss += surrogate_loss.item()
+
+ num_updates = self.num_learning_epochs * self.num_mini_batches
+ mean_value_loss /= num_updates
+ mean_surrogate_loss /= num_updates
+ self.storage.clear()
+
+ return mean_value_loss, mean_surrogate_loss
diff --git a/rsl_rl/rsl_rl/modules/__init__.py b/rsl_rl/rsl_rl/modules/__init__.py
new file mode 100644
index 0000000..3b9d30f
--- /dev/null
+++ b/rsl_rl/rsl_rl/modules/__init__.py
@@ -0,0 +1,32 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+from .actor_critic import ActorCritic
+from .actor_critic_recurrent import ActorCriticRecurrent
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/modules/actor_critic.py b/rsl_rl/rsl_rl/modules/actor_critic.py
new file mode 100644
index 0000000..1864ff4
--- /dev/null
+++ b/rsl_rl/rsl_rl/modules/actor_critic.py
@@ -0,0 +1,155 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import numpy as np
+
+import torch
+import torch.nn as nn
+from torch.distributions import Normal
+from torch.nn.modules import rnn
+
+class ActorCritic(nn.Module):
+ is_recurrent = False
+ def __init__(self, num_actor_obs,
+ num_critic_obs,
+ num_actions,
+ actor_hidden_dims=[256, 256, 256],
+ critic_hidden_dims=[256, 256, 256],
+ activation='elu',
+ init_noise_std=1.0,
+ **kwargs):
+ if kwargs:
+ print("ActorCritic.__init__ got unexpected arguments, which will be ignored: " + str([key for key in kwargs.keys()]))
+ super(ActorCritic, self).__init__()
+
+ activation = get_activation(activation)
+
+ mlp_input_dim_a = num_actor_obs
+ mlp_input_dim_c = num_critic_obs
+
+ # Policy
+ actor_layers = []
+ actor_layers.append(nn.Linear(mlp_input_dim_a, actor_hidden_dims[0]))
+ actor_layers.append(activation)
+ for l in range(len(actor_hidden_dims)):
+ if l == len(actor_hidden_dims) - 1:
+ actor_layers.append(nn.Linear(actor_hidden_dims[l], num_actions))
+ else:
+ actor_layers.append(nn.Linear(actor_hidden_dims[l], actor_hidden_dims[l + 1]))
+ actor_layers.append(activation)
+ self.actor = nn.Sequential(*actor_layers)
+
+ # Value function
+ critic_layers = []
+ critic_layers.append(nn.Linear(mlp_input_dim_c, critic_hidden_dims[0]))
+ critic_layers.append(activation)
+ for l in range(len(critic_hidden_dims)):
+ if l == len(critic_hidden_dims) - 1:
+ critic_layers.append(nn.Linear(critic_hidden_dims[l], 1))
+ else:
+ critic_layers.append(nn.Linear(critic_hidden_dims[l], critic_hidden_dims[l + 1]))
+ critic_layers.append(activation)
+ self.critic = nn.Sequential(*critic_layers)
+
+ print(f"Actor MLP: {self.actor}")
+ print(f"Critic MLP: {self.critic}")
+
+ # Action noise
+ self.std = nn.Parameter(init_noise_std * torch.ones(num_actions))
+ self.distribution = None
+ # disable args validation for speedup
+ Normal.set_default_validate_args = False
+
+ # seems that we get better performance without init
+ # self.init_memory_weights(self.memory_a, 0.001, 0.)
+ # self.init_memory_weights(self.memory_c, 0.001, 0.)
+
+ @staticmethod
+ # not used at the moment
+ def init_weights(sequential, scales):
+ [torch.nn.init.orthogonal_(module.weight, gain=scales[idx]) for idx, module in
+ enumerate(mod for mod in sequential if isinstance(mod, nn.Linear))]
+
+
+ def reset(self, dones=None):
+ pass
+
+ def forward(self):
+ raise NotImplementedError
+
+ @property
+ def action_mean(self):
+ return self.distribution.mean
+
+ @property
+ def action_std(self):
+ return self.distribution.stddev
+
+ @property
+ def entropy(self):
+ return self.distribution.entropy().sum(dim=-1)
+
+ def update_distribution(self, observations):
+ mean = self.actor(observations)
+ self.distribution = Normal(mean, mean*0. + self.std)
+
+ def act(self, observations, **kwargs):
+ self.update_distribution(observations)
+ return self.distribution.sample()
+
+ def get_actions_log_prob(self, actions):
+ return self.distribution.log_prob(actions).sum(dim=-1)
+
+ def act_inference(self, observations):
+ actions_mean = self.actor(observations)
+ return actions_mean
+
+ def evaluate(self, critic_observations, **kwargs):
+ value = self.critic(critic_observations)
+ return value
+
+def get_activation(act_name):
+ if act_name == "elu":
+ return nn.ELU()
+ elif act_name == "selu":
+ return nn.SELU()
+ elif act_name == "relu":
+ return nn.ReLU()
+ elif act_name == "crelu":
+ return nn.ReLU()
+ elif act_name == "lrelu":
+ return nn.LeakyReLU()
+ elif act_name == "tanh":
+ return nn.Tanh()
+ elif act_name == "sigmoid":
+ return nn.Sigmoid()
+ else:
+ print("invalid activation function!")
+ return None
diff --git a/rsl_rl/rsl_rl/modules/actor_critic_recurrent.py b/rsl_rl/rsl_rl/modules/actor_critic_recurrent.py
new file mode 100644
index 0000000..07d9580
--- /dev/null
+++ b/rsl_rl/rsl_rl/modules/actor_critic_recurrent.py
@@ -0,0 +1,116 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import numpy as np
+
+import torch
+import torch.nn as nn
+from torch.distributions import Normal
+from torch.nn.modules import rnn
+from .actor_critic import ActorCritic, get_activation
+from rsl_rl.utils import unpad_trajectories
+
+class ActorCriticRecurrent(ActorCritic):
+ is_recurrent = True
+ def __init__(self, num_actor_obs,
+ num_critic_obs,
+ num_actions,
+ actor_hidden_dims=[256, 256, 256],
+ critic_hidden_dims=[256, 256, 256],
+ activation='elu',
+ rnn_type='lstm',
+ rnn_hidden_size=256,
+ rnn_num_layers=1,
+ init_noise_std=1.0,
+ **kwargs):
+ if kwargs:
+ print("ActorCriticRecurrent.__init__ got unexpected arguments, which will be ignored: " + str(kwargs.keys()),)
+
+ super().__init__(num_actor_obs=rnn_hidden_size,
+ num_critic_obs=rnn_hidden_size,
+ num_actions=num_actions,
+ actor_hidden_dims=actor_hidden_dims,
+ critic_hidden_dims=critic_hidden_dims,
+ activation=activation,
+ init_noise_std=init_noise_std)
+
+ activation = get_activation(activation)
+
+ self.memory_a = Memory(num_actor_obs, type=rnn_type, num_layers=rnn_num_layers, hidden_size=rnn_hidden_size)
+ self.memory_c = Memory(num_critic_obs, type=rnn_type, num_layers=rnn_num_layers, hidden_size=rnn_hidden_size)
+
+ print(f"Actor RNN: {self.memory_a}")
+ print(f"Critic RNN: {self.memory_c}")
+
+ def reset(self, dones=None):
+ self.memory_a.reset(dones)
+ self.memory_c.reset(dones)
+
+ def act(self, observations, masks=None, hidden_states=None):
+ input_a = self.memory_a(observations, masks, hidden_states)
+ return super().act(input_a.squeeze(0))
+
+ def act_inference(self, observations):
+ input_a = self.memory_a(observations)
+ return super().act_inference(input_a.squeeze(0))
+
+ def evaluate(self, critic_observations, masks=None, hidden_states=None):
+ input_c = self.memory_c(critic_observations, masks, hidden_states)
+ return super().evaluate(input_c.squeeze(0))
+
+ def get_hidden_states(self):
+ return self.memory_a.hidden_states, self.memory_c.hidden_states
+
+
+class Memory(torch.nn.Module):
+ def __init__(self, input_size, type='lstm', num_layers=1, hidden_size=256):
+ super().__init__()
+ # RNN
+ rnn_cls = nn.GRU if type.lower() == 'gru' else nn.LSTM
+ self.rnn = rnn_cls(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
+ self.hidden_states = None
+
+ def forward(self, input, masks=None, hidden_states=None):
+ batch_mode = masks is not None
+ if batch_mode:
+ # batch mode (policy update): need saved hidden states
+ if hidden_states is None:
+ raise ValueError("Hidden states not passed to memory module during policy update")
+ out, _ = self.rnn(input, hidden_states)
+ out = unpad_trajectories(out, masks)
+ else:
+ # inference mode (collection): use hidden states of last step
+ out, self.hidden_states = self.rnn(input.unsqueeze(0), self.hidden_states)
+ return out
+
+ def reset(self, dones=None):
+ # When the RNN is an LSTM, self.hidden_states_a is a list with hidden_state and cell_state
+ for hidden_state in self.hidden_states:
+ hidden_state[..., dones, :] = 0.0
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/runners/__init__.py b/rsl_rl/rsl_rl/runners/__init__.py
new file mode 100644
index 0000000..4753f9f
--- /dev/null
+++ b/rsl_rl/rsl_rl/runners/__init__.py
@@ -0,0 +1,31 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+from .on_policy_runner import OnPolicyRunner
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/runners/on_policy_runner.py b/rsl_rl/rsl_rl/runners/on_policy_runner.py
new file mode 100644
index 0000000..e11ae4d
--- /dev/null
+++ b/rsl_rl/rsl_rl/runners/on_policy_runner.py
@@ -0,0 +1,233 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import time
+import os
+from collections import deque
+import statistics
+
+from torch.utils.tensorboard import SummaryWriter
+import torch
+
+from rsl_rl.algorithms import PPO
+from rsl_rl.modules import ActorCritic, ActorCriticRecurrent
+from rsl_rl.env import VecEnv
+
+
+class OnPolicyRunner:
+
+ def __init__(self,
+ env: VecEnv,
+ train_cfg,
+ log_dir=None,
+ device='cpu'):
+
+ self.cfg=train_cfg["runner"]
+ self.alg_cfg = train_cfg["algorithm"]
+ self.policy_cfg = train_cfg["policy"]
+ self.device = device
+ self.env = env
+ if self.env.num_privileged_obs is not None:
+ num_critic_obs = self.env.num_privileged_obs
+ else:
+ num_critic_obs = self.env.num_obs
+ actor_critic_class = eval(self.cfg["policy_class_name"]) # ActorCritic
+ actor_critic: ActorCritic = actor_critic_class( self.env.num_obs,
+ num_critic_obs,
+ self.env.num_actions,
+ **self.policy_cfg).to(self.device)
+ alg_class = eval(self.cfg["algorithm_class_name"]) # PPO
+ self.alg: PPO = alg_class(actor_critic, device=self.device, **self.alg_cfg)
+ self.num_steps_per_env = self.cfg["num_steps_per_env"]
+ self.save_interval = self.cfg["save_interval"]
+
+ # init storage and model
+ self.alg.init_storage(self.env.num_envs, self.num_steps_per_env, [self.env.num_obs], [self.env.num_privileged_obs], [self.env.num_actions])
+
+ # Log
+ self.log_dir = log_dir
+ self.writer = None
+ self.tot_timesteps = 0
+ self.tot_time = 0
+ self.current_learning_iteration = 0
+
+ _, _ = self.env.reset()
+
+ def learn(self, num_learning_iterations, init_at_random_ep_len=False):
+ # initialize writer
+ if self.log_dir is not None and self.writer is None:
+ self.writer = SummaryWriter(log_dir=self.log_dir, flush_secs=10)
+ if init_at_random_ep_len:
+ self.env.episode_length_buf = torch.randint_like(self.env.episode_length_buf, high=int(self.env.max_episode_length))
+ obs = self.env.get_observations()
+ privileged_obs = self.env.get_privileged_observations()
+ critic_obs = privileged_obs if privileged_obs is not None else obs
+ obs, critic_obs = obs.to(self.device), critic_obs.to(self.device)
+ self.alg.actor_critic.train() # switch to train mode (for dropout for example)
+
+ ep_infos = []
+ rewbuffer = deque(maxlen=100)
+ lenbuffer = deque(maxlen=100)
+ cur_reward_sum = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)
+ cur_episode_length = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)
+
+ tot_iter = self.current_learning_iteration + num_learning_iterations
+ for it in range(self.current_learning_iteration, tot_iter):
+ start = time.time()
+ # Rollout
+ with torch.inference_mode():
+ for i in range(self.num_steps_per_env):
+ actions = self.alg.act(obs, critic_obs)
+ obs, privileged_obs, rewards, dones, infos = self.env.step(actions)
+ critic_obs = privileged_obs if privileged_obs is not None else obs
+ obs, critic_obs, rewards, dones = obs.to(self.device), critic_obs.to(self.device), rewards.to(self.device), dones.to(self.device)
+ self.alg.process_env_step(rewards, dones, infos)
+
+ if self.log_dir is not None:
+ # Book keeping
+ if 'episode' in infos:
+ ep_infos.append(infos['episode'])
+ cur_reward_sum += rewards
+ cur_episode_length += 1
+ new_ids = (dones > 0).nonzero(as_tuple=False)
+ rewbuffer.extend(cur_reward_sum[new_ids][:, 0].cpu().numpy().tolist())
+ lenbuffer.extend(cur_episode_length[new_ids][:, 0].cpu().numpy().tolist())
+ cur_reward_sum[new_ids] = 0
+ cur_episode_length[new_ids] = 0
+
+ stop = time.time()
+ collection_time = stop - start
+
+ # Learning step
+ start = stop
+ self.alg.compute_returns(critic_obs)
+
+ mean_value_loss, mean_surrogate_loss = self.alg.update()
+ stop = time.time()
+ learn_time = stop - start
+ if self.log_dir is not None:
+ self.log(locals())
+ if it % self.save_interval == 0:
+ self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))
+ ep_infos.clear()
+
+ self.current_learning_iteration += num_learning_iterations
+ self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(self.current_learning_iteration)))
+
+ def log(self, locs, width=80, pad=35):
+ self.tot_timesteps += self.num_steps_per_env * self.env.num_envs
+ self.tot_time += locs['collection_time'] + locs['learn_time']
+ iteration_time = locs['collection_time'] + locs['learn_time']
+
+ ep_string = f''
+ if locs['ep_infos']:
+ for key in locs['ep_infos'][0]:
+ infotensor = torch.tensor([], device=self.device)
+ for ep_info in locs['ep_infos']:
+ # handle scalar and zero dimensional tensor infos
+ if not isinstance(ep_info[key], torch.Tensor):
+ ep_info[key] = torch.Tensor([ep_info[key]])
+ if len(ep_info[key].shape) == 0:
+ ep_info[key] = ep_info[key].unsqueeze(0)
+ infotensor = torch.cat((infotensor, ep_info[key].to(self.device)))
+ value = torch.mean(infotensor)
+ self.writer.add_scalar('Episode/' + key, value, locs['it'])
+ ep_string += f"""{f'Mean episode {key}:':>{pad}} {value:.4f}\n"""
+ mean_std = self.alg.actor_critic.std.mean()
+ fps = int(self.num_steps_per_env * self.env.num_envs / (locs['collection_time'] + locs['learn_time']))
+
+ self.writer.add_scalar('Loss/value_function', locs['mean_value_loss'], locs['it'])
+ self.writer.add_scalar('Loss/surrogate', locs['mean_surrogate_loss'], locs['it'])
+ self.writer.add_scalar('Loss/learning_rate', self.alg.learning_rate, locs['it'])
+ self.writer.add_scalar('Policy/mean_noise_std', mean_std.item(), locs['it'])
+ self.writer.add_scalar('Perf/total_fps', fps, locs['it'])
+ self.writer.add_scalar('Perf/collection time', locs['collection_time'], locs['it'])
+ self.writer.add_scalar('Perf/learning_time', locs['learn_time'], locs['it'])
+ if len(locs['rewbuffer']) > 0:
+ self.writer.add_scalar('Train/mean_reward', statistics.mean(locs['rewbuffer']), locs['it'])
+ self.writer.add_scalar('Train/mean_episode_length', statistics.mean(locs['lenbuffer']), locs['it'])
+ self.writer.add_scalar('Train/mean_reward/time', statistics.mean(locs['rewbuffer']), self.tot_time)
+ self.writer.add_scalar('Train/mean_episode_length/time', statistics.mean(locs['lenbuffer']), self.tot_time)
+
+ str = f" \033[1m Learning iteration {locs['it']}/{self.current_learning_iteration + locs['num_learning_iterations']} \033[0m "
+
+ if len(locs['rewbuffer']) > 0:
+ log_string = (f"""{'#' * width}\n"""
+ f"""{str.center(width, ' ')}\n\n"""
+ f"""{'Computation:':>{pad}} {fps:.0f} steps/s (collection: {locs[
+ 'collection_time']:.3f}s, learning {locs['learn_time']:.3f}s)\n"""
+ f"""{'Value function loss:':>{pad}} {locs['mean_value_loss']:.4f}\n"""
+ f"""{'Surrogate loss:':>{pad}} {locs['mean_surrogate_loss']:.4f}\n"""
+ f"""{'Mean action noise std:':>{pad}} {mean_std.item():.2f}\n"""
+ f"""{'Mean reward:':>{pad}} {statistics.mean(locs['rewbuffer']):.2f}\n"""
+ f"""{'Mean episode length:':>{pad}} {statistics.mean(locs['lenbuffer']):.2f}\n""")
+ # f"""{'Mean reward/step:':>{pad}} {locs['mean_reward']:.2f}\n"""
+ # f"""{'Mean episode length/episode:':>{pad}} {locs['mean_trajectory_length']:.2f}\n""")
+ else:
+ log_string = (f"""{'#' * width}\n"""
+ f"""{str.center(width, ' ')}\n\n"""
+ f"""{'Computation:':>{pad}} {fps:.0f} steps/s (collection: {locs[
+ 'collection_time']:.3f}s, learning {locs['learn_time']:.3f}s)\n"""
+ f"""{'Value function loss:':>{pad}} {locs['mean_value_loss']:.4f}\n"""
+ f"""{'Surrogate loss:':>{pad}} {locs['mean_surrogate_loss']:.4f}\n"""
+ f"""{'Mean action noise std:':>{pad}} {mean_std.item():.2f}\n""")
+ # f"""{'Mean reward/step:':>{pad}} {locs['mean_reward']:.2f}\n"""
+ # f"""{'Mean episode length/episode:':>{pad}} {locs['mean_trajectory_length']:.2f}\n""")
+
+ log_string += ep_string
+ log_string += (f"""{'-' * width}\n"""
+ f"""{'Total timesteps:':>{pad}} {self.tot_timesteps}\n"""
+ f"""{'Iteration time:':>{pad}} {iteration_time:.2f}s\n"""
+ f"""{'Total time:':>{pad}} {self.tot_time:.2f}s\n"""
+ f"""{'ETA:':>{pad}} {self.tot_time / (locs['it'] + 1) * (
+ locs['num_learning_iterations'] - locs['it']):.1f}s\n""")
+ print(log_string)
+
+ def save(self, path, infos=None):
+ torch.save({
+ 'model_state_dict': self.alg.actor_critic.state_dict(),
+ 'optimizer_state_dict': self.alg.optimizer.state_dict(),
+ 'iter': self.current_learning_iteration,
+ 'infos': infos,
+ }, path)
+
+ def load(self, path, load_optimizer=True):
+ loaded_dict = torch.load(path)
+ self.alg.actor_critic.load_state_dict(loaded_dict['model_state_dict'])
+ if load_optimizer:
+ self.alg.optimizer.load_state_dict(loaded_dict['optimizer_state_dict'])
+ self.current_learning_iteration = loaded_dict['iter']
+ return loaded_dict['infos']
+
+ def get_inference_policy(self, device=None):
+ self.alg.actor_critic.eval() # switch to evaluation mode (dropout for example)
+ if device is not None:
+ self.alg.actor_critic.to(device)
+ return self.alg.actor_critic.act_inference
diff --git a/rsl_rl/rsl_rl/storage/__init__.py b/rsl_rl/rsl_rl/storage/__init__.py
new file mode 100644
index 0000000..e8f67f5
--- /dev/null
+++ b/rsl_rl/rsl_rl/storage/__init__.py
@@ -0,0 +1,4 @@
+# Copyright 2021 ETH Zurich, NVIDIA CORPORATION
+# SPDX-License-Identifier: BSD-3-Clause
+
+from .rollout_storage import RolloutStorage
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/storage/rollout_storage.py b/rsl_rl/rsl_rl/storage/rollout_storage.py
new file mode 100644
index 0000000..66ee55f
--- /dev/null
+++ b/rsl_rl/rsl_rl/storage/rollout_storage.py
@@ -0,0 +1,235 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import torch
+import numpy as np
+
+from rsl_rl.utils import split_and_pad_trajectories
+
+class RolloutStorage:
+ class Transition:
+ def __init__(self):
+ self.observations = None
+ self.critic_observations = None
+ self.actions = None
+ self.rewards = None
+ self.dones = None
+ self.values = None
+ self.actions_log_prob = None
+ self.action_mean = None
+ self.action_sigma = None
+ self.hidden_states = None
+
+ def clear(self):
+ self.__init__()
+
+ def __init__(self, num_envs, num_transitions_per_env, obs_shape, privileged_obs_shape, actions_shape, device='cpu'):
+
+ self.device = device
+
+ self.obs_shape = obs_shape
+ self.privileged_obs_shape = privileged_obs_shape
+ self.actions_shape = actions_shape
+
+ # Core
+ self.observations = torch.zeros(num_transitions_per_env, num_envs, *obs_shape, device=self.device)
+ if privileged_obs_shape[0] is not None:
+ self.privileged_observations = torch.zeros(num_transitions_per_env, num_envs, *privileged_obs_shape, device=self.device)
+ else:
+ self.privileged_observations = None
+ self.rewards = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device)
+ self.actions = torch.zeros(num_transitions_per_env, num_envs, *actions_shape, device=self.device)
+ self.dones = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device).byte()
+
+ # For PPO
+ self.actions_log_prob = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device)
+ self.values = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device)
+ self.returns = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device)
+ self.advantages = torch.zeros(num_transitions_per_env, num_envs, 1, device=self.device)
+ self.mu = torch.zeros(num_transitions_per_env, num_envs, *actions_shape, device=self.device)
+ self.sigma = torch.zeros(num_transitions_per_env, num_envs, *actions_shape, device=self.device)
+
+ self.num_transitions_per_env = num_transitions_per_env
+ self.num_envs = num_envs
+
+ # rnn
+ self.saved_hidden_states_a = None
+ self.saved_hidden_states_c = None
+
+ self.step = 0
+
+ def add_transitions(self, transition: Transition):
+ if self.step >= self.num_transitions_per_env:
+ raise AssertionError("Rollout buffer overflow")
+ self.observations[self.step].copy_(transition.observations)
+ if self.privileged_observations is not None: self.privileged_observations[self.step].copy_(transition.critic_observations)
+ self.actions[self.step].copy_(transition.actions)
+ self.rewards[self.step].copy_(transition.rewards.view(-1, 1))
+ self.dones[self.step].copy_(transition.dones.view(-1, 1))
+ self.values[self.step].copy_(transition.values)
+ self.actions_log_prob[self.step].copy_(transition.actions_log_prob.view(-1, 1))
+ self.mu[self.step].copy_(transition.action_mean)
+ self.sigma[self.step].copy_(transition.action_sigma)
+ self._save_hidden_states(transition.hidden_states)
+ self.step += 1
+
+ def _save_hidden_states(self, hidden_states):
+ if hidden_states is None or hidden_states==(None, None):
+ return
+ # make a tuple out of GRU hidden state sto match the LSTM format
+ hid_a = hidden_states[0] if isinstance(hidden_states[0], tuple) else (hidden_states[0],)
+ hid_c = hidden_states[1] if isinstance(hidden_states[1], tuple) else (hidden_states[1],)
+
+ # initialize if needed
+ if self.saved_hidden_states_a is None:
+ self.saved_hidden_states_a = [torch.zeros(self.observations.shape[0], *hid_a[i].shape, device=self.device) for i in range(len(hid_a))]
+ self.saved_hidden_states_c = [torch.zeros(self.observations.shape[0], *hid_c[i].shape, device=self.device) for i in range(len(hid_c))]
+ # copy the states
+ for i in range(len(hid_a)):
+ self.saved_hidden_states_a[i][self.step].copy_(hid_a[i])
+ self.saved_hidden_states_c[i][self.step].copy_(hid_c[i])
+
+
+ def clear(self):
+ self.step = 0
+
+ def compute_returns(self, last_values, gamma, lam):
+ advantage = 0
+ for step in reversed(range(self.num_transitions_per_env)):
+ if step == self.num_transitions_per_env - 1:
+ next_values = last_values
+ else:
+ next_values = self.values[step + 1]
+ next_is_not_terminal = 1.0 - self.dones[step].float()
+ delta = self.rewards[step] + next_is_not_terminal * gamma * next_values - self.values[step]
+ advantage = delta + next_is_not_terminal * gamma * lam * advantage
+ self.returns[step] = advantage + self.values[step]
+
+ # Compute and normalize the advantages
+ self.advantages = self.returns - self.values
+ self.advantages = (self.advantages - self.advantages.mean()) / (self.advantages.std() + 1e-8)
+
+ def get_statistics(self):
+ done = self.dones
+ done[-1] = 1
+ flat_dones = done.permute(1, 0, 2).reshape(-1, 1)
+ done_indices = torch.cat((flat_dones.new_tensor([-1], dtype=torch.int64), flat_dones.nonzero(as_tuple=False)[:, 0]))
+ trajectory_lengths = (done_indices[1:] - done_indices[:-1])
+ return trajectory_lengths.float().mean(), self.rewards.mean()
+
+ def mini_batch_generator(self, num_mini_batches, num_epochs=8):
+ batch_size = self.num_envs * self.num_transitions_per_env
+ mini_batch_size = batch_size // num_mini_batches
+ indices = torch.randperm(num_mini_batches*mini_batch_size, requires_grad=False, device=self.device)
+
+ observations = self.observations.flatten(0, 1)
+ if self.privileged_observations is not None:
+ critic_observations = self.privileged_observations.flatten(0, 1)
+ else:
+ critic_observations = observations
+
+ actions = self.actions.flatten(0, 1)
+ values = self.values.flatten(0, 1)
+ returns = self.returns.flatten(0, 1)
+ old_actions_log_prob = self.actions_log_prob.flatten(0, 1)
+ advantages = self.advantages.flatten(0, 1)
+ old_mu = self.mu.flatten(0, 1)
+ old_sigma = self.sigma.flatten(0, 1)
+
+ for epoch in range(num_epochs):
+ for i in range(num_mini_batches):
+
+ start = i*mini_batch_size
+ end = (i+1)*mini_batch_size
+ batch_idx = indices[start:end]
+
+ obs_batch = observations[batch_idx]
+ critic_observations_batch = critic_observations[batch_idx]
+ actions_batch = actions[batch_idx]
+ target_values_batch = values[batch_idx]
+ returns_batch = returns[batch_idx]
+ old_actions_log_prob_batch = old_actions_log_prob[batch_idx]
+ advantages_batch = advantages[batch_idx]
+ old_mu_batch = old_mu[batch_idx]
+ old_sigma_batch = old_sigma[batch_idx]
+ yield obs_batch, critic_observations_batch, actions_batch, target_values_batch, advantages_batch, returns_batch, \
+ old_actions_log_prob_batch, old_mu_batch, old_sigma_batch, (None, None), None
+
+ # for RNNs only
+ def reccurent_mini_batch_generator(self, num_mini_batches, num_epochs=8):
+
+ padded_obs_trajectories, trajectory_masks = split_and_pad_trajectories(self.observations, self.dones)
+ if self.privileged_observations is not None:
+ padded_critic_obs_trajectories, _ = split_and_pad_trajectories(self.privileged_observations, self.dones)
+ else:
+ padded_critic_obs_trajectories = padded_obs_trajectories
+
+ mini_batch_size = self.num_envs // num_mini_batches
+ for ep in range(num_epochs):
+ first_traj = 0
+ for i in range(num_mini_batches):
+ start = i*mini_batch_size
+ stop = (i+1)*mini_batch_size
+
+ dones = self.dones.squeeze(-1)
+ last_was_done = torch.zeros_like(dones, dtype=torch.bool)
+ last_was_done[1:] = dones[:-1]
+ last_was_done[0] = True
+ trajectories_batch_size = torch.sum(last_was_done[:, start:stop])
+ last_traj = first_traj + trajectories_batch_size
+
+ masks_batch = trajectory_masks[:, first_traj:last_traj]
+ obs_batch = padded_obs_trajectories[:, first_traj:last_traj]
+ critic_obs_batch = padded_critic_obs_trajectories[:, first_traj:last_traj]
+
+ actions_batch = self.actions[:, start:stop]
+ old_mu_batch = self.mu[:, start:stop]
+ old_sigma_batch = self.sigma[:, start:stop]
+ returns_batch = self.returns[:, start:stop]
+ advantages_batch = self.advantages[:, start:stop]
+ values_batch = self.values[:, start:stop]
+ old_actions_log_prob_batch = self.actions_log_prob[:, start:stop]
+
+ # reshape to [num_envs, time, num layers, hidden dim] (original shape: [time, num_layers, num_envs, hidden_dim])
+ # then take only time steps after dones (flattens num envs and time dimensions),
+ # take a batch of trajectories and finally reshape back to [num_layers, batch, hidden_dim]
+ last_was_done = last_was_done.permute(1, 0)
+ hid_a_batch = [ saved_hidden_states.permute(2, 0, 1, 3)[last_was_done][first_traj:last_traj].transpose(1, 0).contiguous()
+ for saved_hidden_states in self.saved_hidden_states_a ]
+ hid_c_batch = [ saved_hidden_states.permute(2, 0, 1, 3)[last_was_done][first_traj:last_traj].transpose(1, 0).contiguous()
+ for saved_hidden_states in self.saved_hidden_states_c ]
+ # remove the tuple for GRU
+ hid_a_batch = hid_a_batch[0] if len(hid_a_batch)==1 else hid_a_batch
+ hid_c_batch = hid_c_batch[0] if len(hid_c_batch)==1 else hid_a_batch
+
+ yield obs_batch, critic_obs_batch, actions_batch, values_batch, advantages_batch, returns_batch, \
+ old_actions_log_prob_batch, old_mu_batch, old_sigma_batch, (hid_a_batch, hid_c_batch), masks_batch
+
+ first_traj = last_traj
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/utils/__init__.py b/rsl_rl/rsl_rl/utils/__init__.py
new file mode 100644
index 0000000..1b505f3
--- /dev/null
+++ b/rsl_rl/rsl_rl/utils/__init__.py
@@ -0,0 +1,31 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+from .utils import split_and_pad_trajectories, unpad_trajectories
\ No newline at end of file
diff --git a/rsl_rl/rsl_rl/utils/utils.py b/rsl_rl/rsl_rl/utils/utils.py
new file mode 100644
index 0000000..b6affab
--- /dev/null
+++ b/rsl_rl/rsl_rl/utils/utils.py
@@ -0,0 +1,71 @@
+# SPDX-FileCopyrightText: Copyright (c) 2021 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
+# SPDX-License-Identifier: BSD-3-Clause
+#
+# Redistribution and use in source and binary forms, with or without
+# modification, are permitted provided that the following conditions are met:
+#
+# 1. Redistributions of source code must retain the above copyright notice, this
+# list of conditions and the following disclaimer.
+#
+# 2. Redistributions in binary form must reproduce the above copyright notice,
+# this list of conditions and the following disclaimer in the documentation
+# and/or other materials provided with the distribution.
+#
+# 3. Neither the name of the copyright holder nor the names of its
+# contributors may be used to endorse or promote products derived from
+# this software without specific prior written permission.
+#
+# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# Copyright (c) 2021 ETH Zurich, Nikita Rudin
+
+import torch
+
+def split_and_pad_trajectories(tensor, dones):
+ """ Splits trajectories at done indices. Then concatenates them and padds with zeros up to the length og the longest trajectory.
+ Returns masks corresponding to valid parts of the trajectories
+ Example:
+ Input: [ [a1, a2, a3, a4 | a5, a6],
+ [b1, b2 | b3, b4, b5 | b6]
+ ]
+
+ Output:[ [a1, a2, a3, a4], | [ [True, True, True, True],
+ [a5, a6, 0, 0], | [True, True, False, False],
+ [b1, b2, 0, 0], | [True, True, False, False],
+ [b3, b4, b5, 0], | [True, True, True, False],
+ [b6, 0, 0, 0] | [True, False, False, False],
+ ] | ]
+
+ Assumes that the inputy has the following dimension order: [time, number of envs, aditional dimensions]
+ """
+ dones = dones.clone()
+ dones[-1] = 1
+ # Permute the buffers to have order (num_envs, num_transitions_per_env, ...), for correct reshaping
+ flat_dones = dones.transpose(1, 0).reshape(-1, 1)
+
+ # Get length of trajectory by counting the number of successive not done elements
+ done_indices = torch.cat((flat_dones.new_tensor([-1], dtype=torch.int64), flat_dones.nonzero()[:, 0]))
+ trajectory_lengths = done_indices[1:] - done_indices[:-1]
+ trajectory_lengths_list = trajectory_lengths.tolist()
+ # Extract the individual trajectories
+ trajectories = torch.split(tensor.transpose(1, 0).flatten(0, 1),trajectory_lengths_list)
+ padded_trajectories = torch.nn.utils.rnn.pad_sequence(trajectories)
+
+
+ trajectory_masks = trajectory_lengths > torch.arange(0, tensor.shape[0], device=tensor.device).unsqueeze(1)
+ return padded_trajectories, trajectory_masks
+
+def unpad_trajectories(trajectories, masks):
+ """ Does the inverse operation of split_and_pad_trajectories()
+ """
+ # Need to transpose before and after the masking to have proper reshaping
+ return trajectories.transpose(1, 0)[masks.transpose(1, 0)].view(-1, trajectories.shape[0], trajectories.shape[-1]).transpose(1, 0)
\ No newline at end of file
diff --git a/rsl_rl/setup.py b/rsl_rl/setup.py
new file mode 100644
index 0000000..ec4cb6d
--- /dev/null
+++ b/rsl_rl/setup.py
@@ -0,0 +1,16 @@
+from setuptools import setup, find_packages
+
+setup(name='rsl_rl',
+ version='1.0.2',
+ author='Nikita Rudin',
+ author_email='rudinn@ethz.ch',
+ license="BSD-3-Clause",
+ packages=find_packages(),
+ description='Fast and simple RL algorithms implemented in pytorch',
+ python_requires='>=3.6',
+ install_requires=[
+ "torch>=1.4.0",
+ "torchvision>=0.5.0",
+ "numpy>=1.16.4"
+ ],
+ )
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000..cd12ef3
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,11 @@
+from setuptools import find_packages
+from distutils.core import setup
+
+setup(name='unitree_rl_gym',
+ version='1.0.0',
+ author='Unitree Robotics',
+ license="BSD-3-Clause",
+ packages=find_packages(),
+ author_email='support@unitree.com',
+ description='Template RL environments for Unitree Robots',
+ install_requires=['isaacgym', 'rsl-rl', 'matplotlib', 'numpy==1.20', 'tensorboard', 'mujoco==3.2.3', 'pyyaml'])
 ](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [
](https://oss-global-cdn.unitree.com/static/5bbc5ab1d551407080ca9d58d7bec1c8.mp4) | [ ](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [
](https://oss-global-cdn.unitree.com/static/5aa48535ffd641e2932c0ba45c8e7854.mp4) | [ ](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) |
+
+
](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) |
+
+ +
+Then use the `ifconfig` command to view the name of the network interface connected to the robot. Record the network interface name, which will be used as a parameter of the startup command later
+
+
+
+Then use the `ifconfig` command to view the name of the network interface connected to the robot. Record the network interface name, which will be used as a parameter of the startup command later
+
+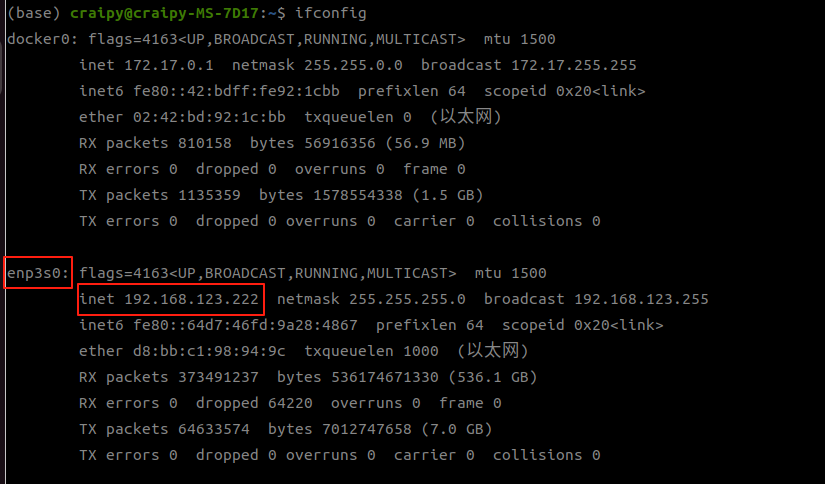 +
+### 4. Start the program
+
+Assume that the network card currently connected to the physical robot is named `enp3s0`. Take the G1 robot as an example, execute the following command to start
+
+```bash
+python deploy_real.py enp3s0 g1.yaml
+```
+
+#### 4.1 Zero torque state
+
+After starting, the robot joints will be in the zero torque state. You can shake the robot joints by hand to feel and confirm.
+
+#### 4.2 Default position state
+
+In the zero torque state, press the `start` button on the remote control, and the robot will move to the default joint position state.
+
+After the robot moves to the default joint position, you can slowly lower the hoisting mechanism to let the robot's feet touch the ground.
+
+#### 4.3 Motion control mode
+
+After the preparation is completed, press the `A` button on the remote control, and the robot will step on the spot. After the robot is stable, you can gradually lower the hoisting rope to give the robot a certain amount of space to move.
+
+At this time, you can use the joystick on the remote control to control the movement of the robot.
+The front and back of the left joystick controls the movement speed of the robot in the x direction
+The left and right of the left joystick controls the movement speed of the robot in the y direction
+The left and right of the right joystick controls the movement speed of the robot's yaw angle
+
+#### 4.4 Exit control
+
+In motion control mode, press the `select` button on the remote control, the robot will enter the damping mode and fall down, and the program will exit. Or use `ctrl+c` in the terminal to close the program.
+
+> Note:
+>
+> Since this example deployment is not a stable control program and is only used for demonstration purposes, please try not to disturb the robot during the control process. If any unexpected situation occurs during the control process, please exit the control in time to avoid danger.
+
+## Video tutorial
+
+
+deploy on G1 robot: [https://oss-global-cdn.unitree.com/static/ea12b7fb3bb641b3ada9c91d44d348db.mp4](https://oss-global-cdn.unitree.com/static/ea12b7fb3bb641b3ada9c91d44d348db.mp4)
+
+deploy on H1 robot: [https://oss-global-cdn.unitree.com/static/d4e0cdd8ce0d477fb5bffbb1ac5ef69d.mp4](https://oss-global-cdn.unitree.com/static/d4e0cdd8ce0d477fb5bffbb1ac5ef69d.mp4)
+
+deploy on H1_2 robot: [https://oss-global-cdn.unitree.com/static/8120e35452404923b854d9e98bdac951.mp4](https://oss-global-cdn.unitree.com/static/8120e35452404923b854d9e98bdac951.mp4)
+
diff --git a/deploy/deploy_real/README.zh.md b/deploy/deploy_real/README.zh.md
new file mode 100644
index 0000000..83761ef
--- /dev/null
+++ b/deploy/deploy_real/README.zh.md
@@ -0,0 +1,79 @@
+# 实物部署
+
+本代码可以在实物部署训练的网络。目前支持的机器人包括 Unitree G1, H1, H1_2。
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) | [](https://oss-global-cdn.unitree.com/static/ea0084038d384e3eaa73b961f33e6210.mp4) | [](https://oss-global-cdn.unitree.com/static/12d041a7906e489fae79d55b091a63dd.mp4) |
+
+## 启动用法
+
+```bash
+python deploy_real.py {net_interface} {config_name}
+```
+
+- `net_interface`: 为连接机器人的网卡的名字,例如`enp3s0`
+- `config_name`: 配置文件的文件名。配置文件会在 `deploy/deploy_real/configs/` 下查找, 例如`g1.yaml`, `h1.yaml`, `h1_2.yaml`。
+
+## 启动过程
+
+### 1. 启动机器人
+
+将机器人在吊装状态下启动,并等待机器人进入 `零力矩模式`
+
+### 2. 进入调试模式
+
+确保机器人处于 `零力矩模式` 的情况下,按下遥控器的 `L2+R2`组合键;此时机器人会进入`调试模式`, `调试模式`下机器人关节处于阻尼状态。
+
+### 3. 连接机器人
+
+使用网线连接自己的电脑和机器人上的网口。修改网络配置如下
+
+
+
+### 4. Start the program
+
+Assume that the network card currently connected to the physical robot is named `enp3s0`. Take the G1 robot as an example, execute the following command to start
+
+```bash
+python deploy_real.py enp3s0 g1.yaml
+```
+
+#### 4.1 Zero torque state
+
+After starting, the robot joints will be in the zero torque state. You can shake the robot joints by hand to feel and confirm.
+
+#### 4.2 Default position state
+
+In the zero torque state, press the `start` button on the remote control, and the robot will move to the default joint position state.
+
+After the robot moves to the default joint position, you can slowly lower the hoisting mechanism to let the robot's feet touch the ground.
+
+#### 4.3 Motion control mode
+
+After the preparation is completed, press the `A` button on the remote control, and the robot will step on the spot. After the robot is stable, you can gradually lower the hoisting rope to give the robot a certain amount of space to move.
+
+At this time, you can use the joystick on the remote control to control the movement of the robot.
+The front and back of the left joystick controls the movement speed of the robot in the x direction
+The left and right of the left joystick controls the movement speed of the robot in the y direction
+The left and right of the right joystick controls the movement speed of the robot's yaw angle
+
+#### 4.4 Exit control
+
+In motion control mode, press the `select` button on the remote control, the robot will enter the damping mode and fall down, and the program will exit. Or use `ctrl+c` in the terminal to close the program.
+
+> Note:
+>
+> Since this example deployment is not a stable control program and is only used for demonstration purposes, please try not to disturb the robot during the control process. If any unexpected situation occurs during the control process, please exit the control in time to avoid danger.
+
+## Video tutorial
+
+
+deploy on G1 robot: [https://oss-global-cdn.unitree.com/static/ea12b7fb3bb641b3ada9c91d44d348db.mp4](https://oss-global-cdn.unitree.com/static/ea12b7fb3bb641b3ada9c91d44d348db.mp4)
+
+deploy on H1 robot: [https://oss-global-cdn.unitree.com/static/d4e0cdd8ce0d477fb5bffbb1ac5ef69d.mp4](https://oss-global-cdn.unitree.com/static/d4e0cdd8ce0d477fb5bffbb1ac5ef69d.mp4)
+
+deploy on H1_2 robot: [https://oss-global-cdn.unitree.com/static/8120e35452404923b854d9e98bdac951.mp4](https://oss-global-cdn.unitree.com/static/8120e35452404923b854d9e98bdac951.mp4)
+
diff --git a/deploy/deploy_real/README.zh.md b/deploy/deploy_real/README.zh.md
new file mode 100644
index 0000000..83761ef
--- /dev/null
+++ b/deploy/deploy_real/README.zh.md
@@ -0,0 +1,79 @@
+# 实物部署
+
+本代码可以在实物部署训练的网络。目前支持的机器人包括 Unitree G1, H1, H1_2。
+
+| G1 | H1 | H1_2 |
+|--- | --- | --- |
+| [](https://oss-global-cdn.unitree.com/static/0818dcf7a6874b92997354d628adcacd.mp4) | [](https://oss-global-cdn.unitree.com/static/ea0084038d384e3eaa73b961f33e6210.mp4) | [](https://oss-global-cdn.unitree.com/static/12d041a7906e489fae79d55b091a63dd.mp4) |
+
+## 启动用法
+
+```bash
+python deploy_real.py {net_interface} {config_name}
+```
+
+- `net_interface`: 为连接机器人的网卡的名字,例如`enp3s0`
+- `config_name`: 配置文件的文件名。配置文件会在 `deploy/deploy_real/configs/` 下查找, 例如`g1.yaml`, `h1.yaml`, `h1_2.yaml`。
+
+## 启动过程
+
+### 1. 启动机器人
+
+将机器人在吊装状态下启动,并等待机器人进入 `零力矩模式`
+
+### 2. 进入调试模式
+
+确保机器人处于 `零力矩模式` 的情况下,按下遥控器的 `L2+R2`组合键;此时机器人会进入`调试模式`, `调试模式`下机器人关节处于阻尼状态。
+
+### 3. 连接机器人
+
+使用网线连接自己的电脑和机器人上的网口。修改网络配置如下
+
+